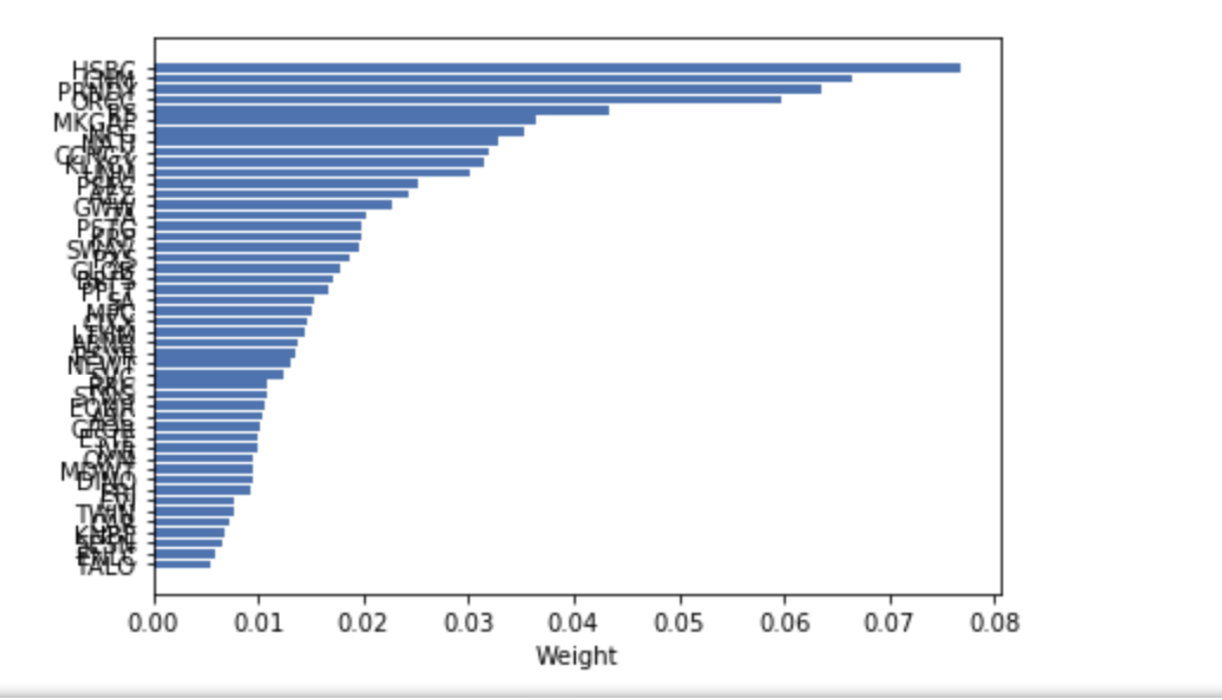
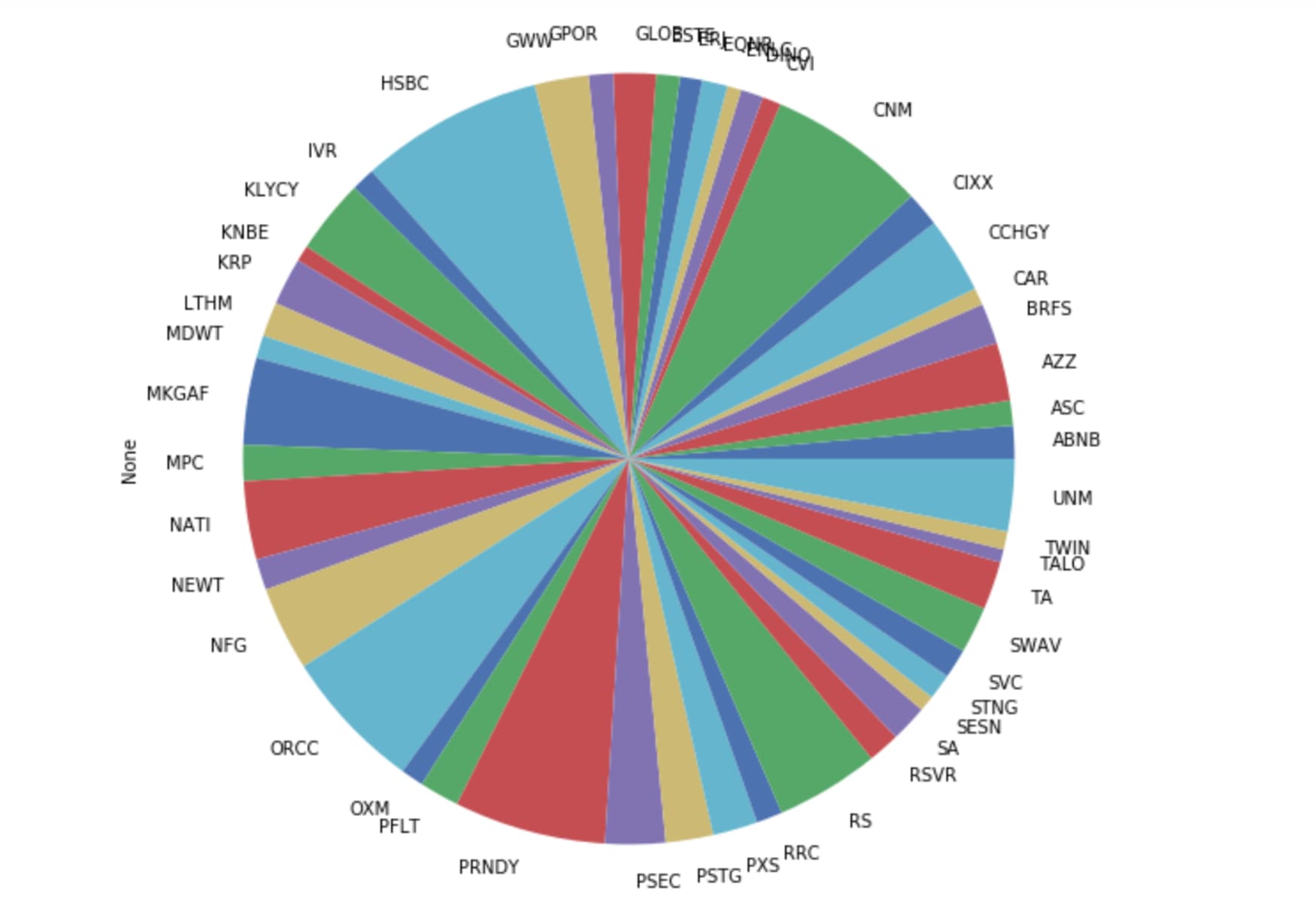
All,
I have some evidence that would suggest hierarchical risk parity (HRP) improves returns (and reduces risk) for securities selected on the basis of momentum (ETFs in this case).
That makes some sense if one believes in the Kelly criteria and diversifying ones bets. But one could also support this idea with mean-variance optimization.
I am beginning to think this forum is not the place to discuss machine learning in detail. Not yet anyway but I truly appreciated Marco’s efforts to change this. Thank you Marco. So to just summarize:
An optimal Kelly bet is μ/σ^2. So assuming momentum might continue, selecting a momentum asset hopes to improve μ. The denominator (σ^2) can be addressed by using hierarchical risk parity.
And hierarchical risk parity also serves to diversify those bets. The truth is μ is hard to predict going forward. Fortunately, hierarchical risk parity is not so sensitive to the predicted μ while HRP serves to diversify those unpredictable bets.
So HRP is a prefect compliment to any real-world discussion on how to “place your bets” in the stock market using the Kelly criterion. But to be clear, I am not looking for “Optimal Kelly” which would produce the theoretical maximum returns (I can only wish). In fact, I am saying one can never find optimal Kelly because one can never really know μ going forward.
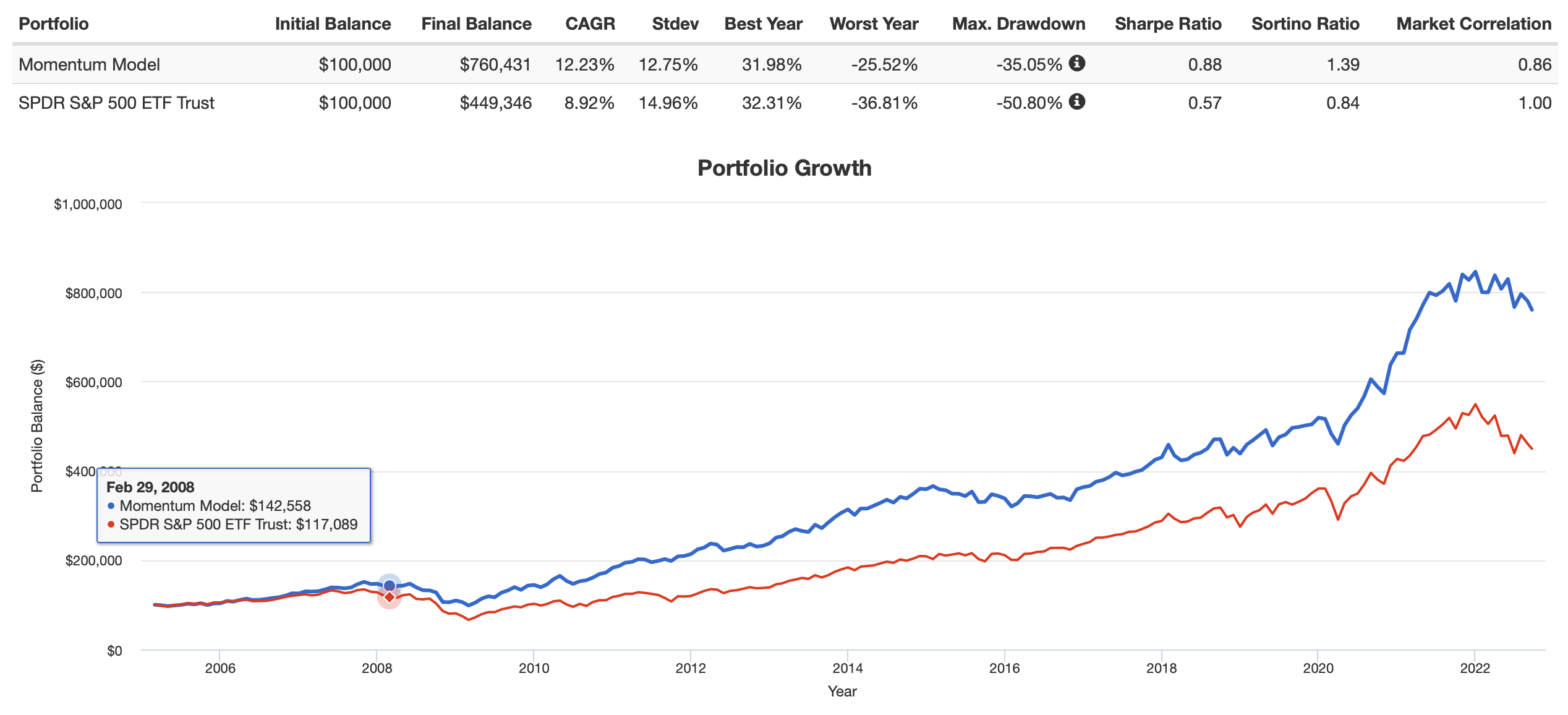
Anyway, that is enough of the theory. Here is one piece of evidence. Returns of equal weighing of some ETFs based on relative strength:
Exact same holdings weighted using hierarchical risk parity calculated by PyPortfolioOpt (Python):
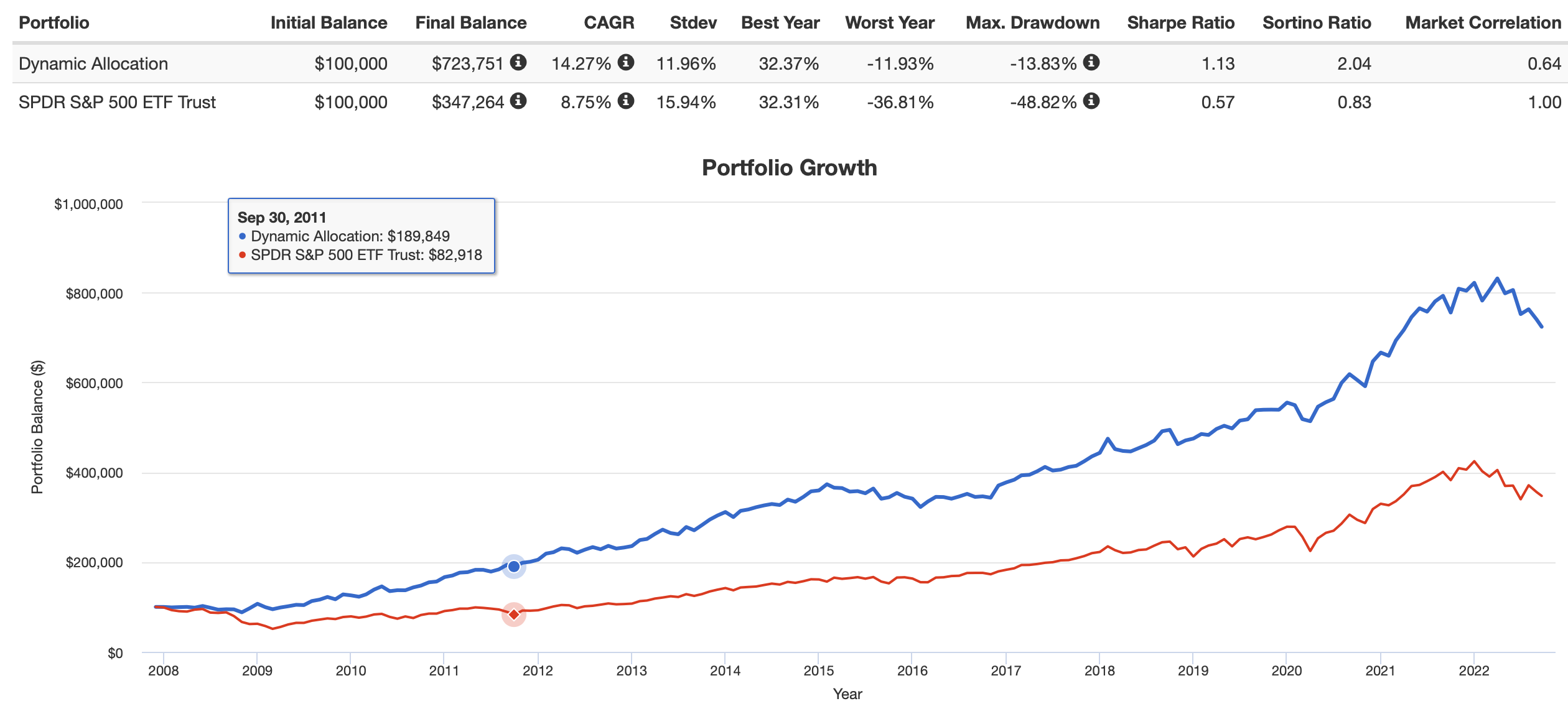
That is higher returns with less risk, I believe. Which is all I was looking for using HRP–as humble as that goal may seem.
I think one could take on even more risk based on the Kelly criterion. That could be done by using more volatile stocks (or leverage) and the risk could continue be minimized and diversified using hierarchical risk parity. Sentiment or other factors may work better or interact with momentum in a positive way (maybe one could use partial least square to optimize the factors).
TL;DR: You can probably skip the above and still improve your returns while reducing your risk by using the program PyPortfolioOpt with Python. And again, thank you Marco for supporting machine learning and AI in the forum.
Jim