Absolutely, and I deeply appreciate your willingness to consider these suggestions.
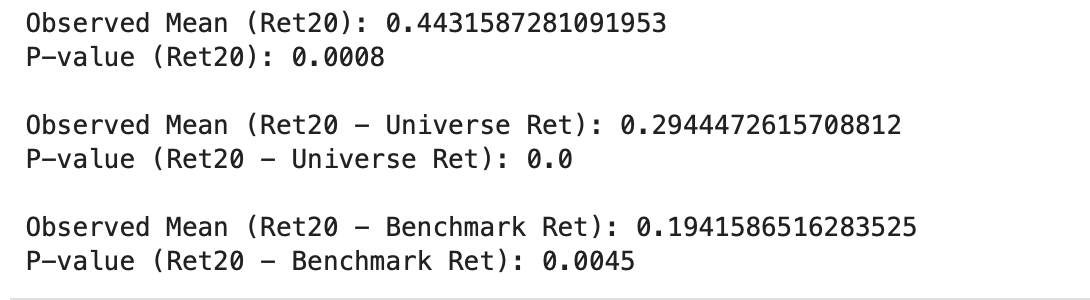
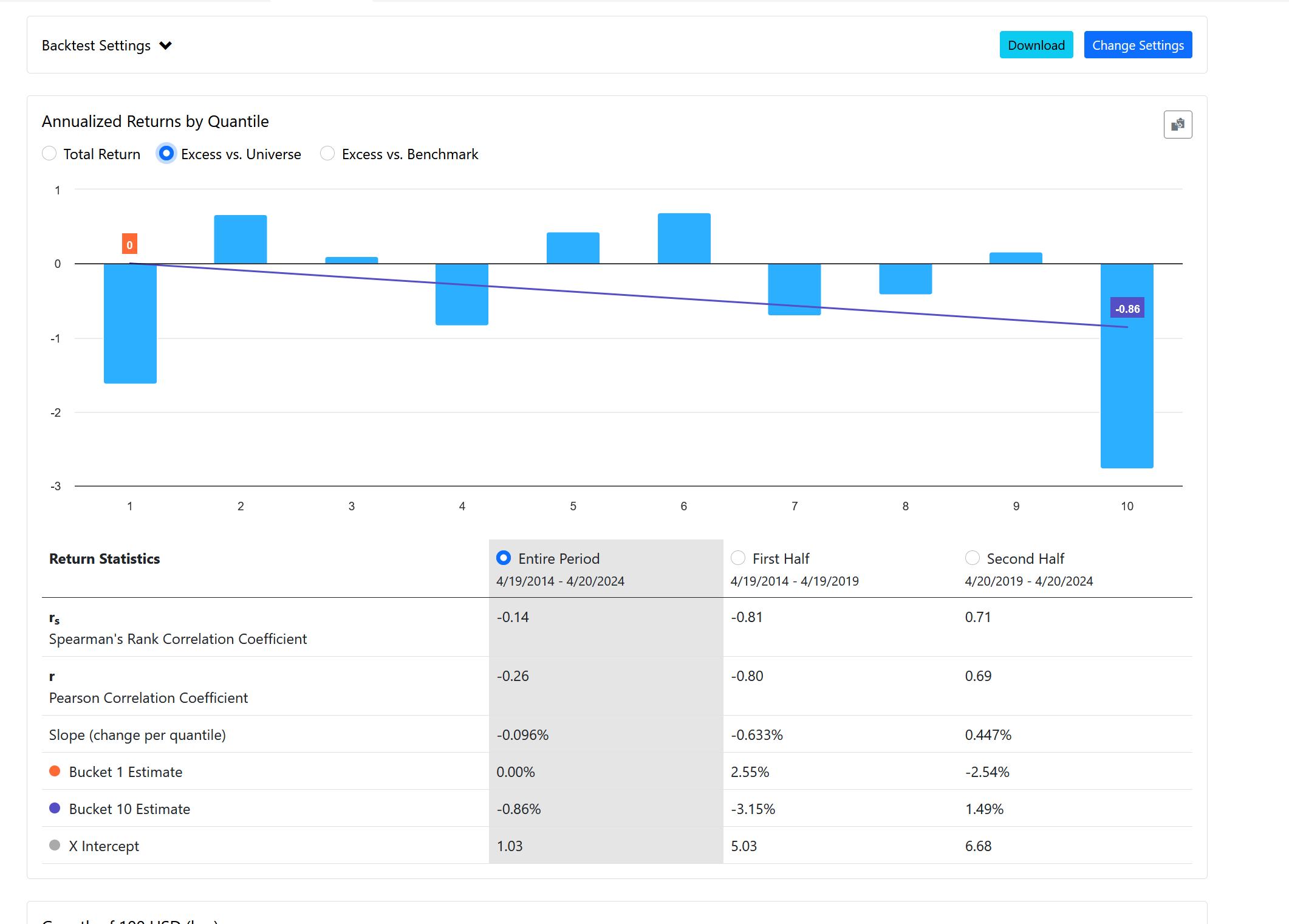
- While you do offer excess returns, which is fantastic, the concern lies in its nature as a proxy result. The excess returns you illustrate as StockReturn_A - BenchmarkReturn are indeed how it's currently handled in the ranking system. However, the focus here isn't on excess returns, whether knowingly or unknowingly, because it doesn't account for beta. The beta you provide, which might not be the most accurate in my opinion, is crucial. See these charts.
Notice the distinct differences in each signal. Raw returns depict them as largely irrelevant. Universe returns (which ideally should align with the benchmark since I'm selecting the SP500 and IVV benchmark and universe, respectively) show marked discrepancies.
Simply observing a generic beta demonstrates the relevance of this metric and how our ranking tool isn't capturing it. In essence, a stock with a beta of 2 in a bullish market will exhibit excess returns 2x the benchmark, which isn't true alpha. Yet the ranking system will show those as excess returns. We must control for beta.
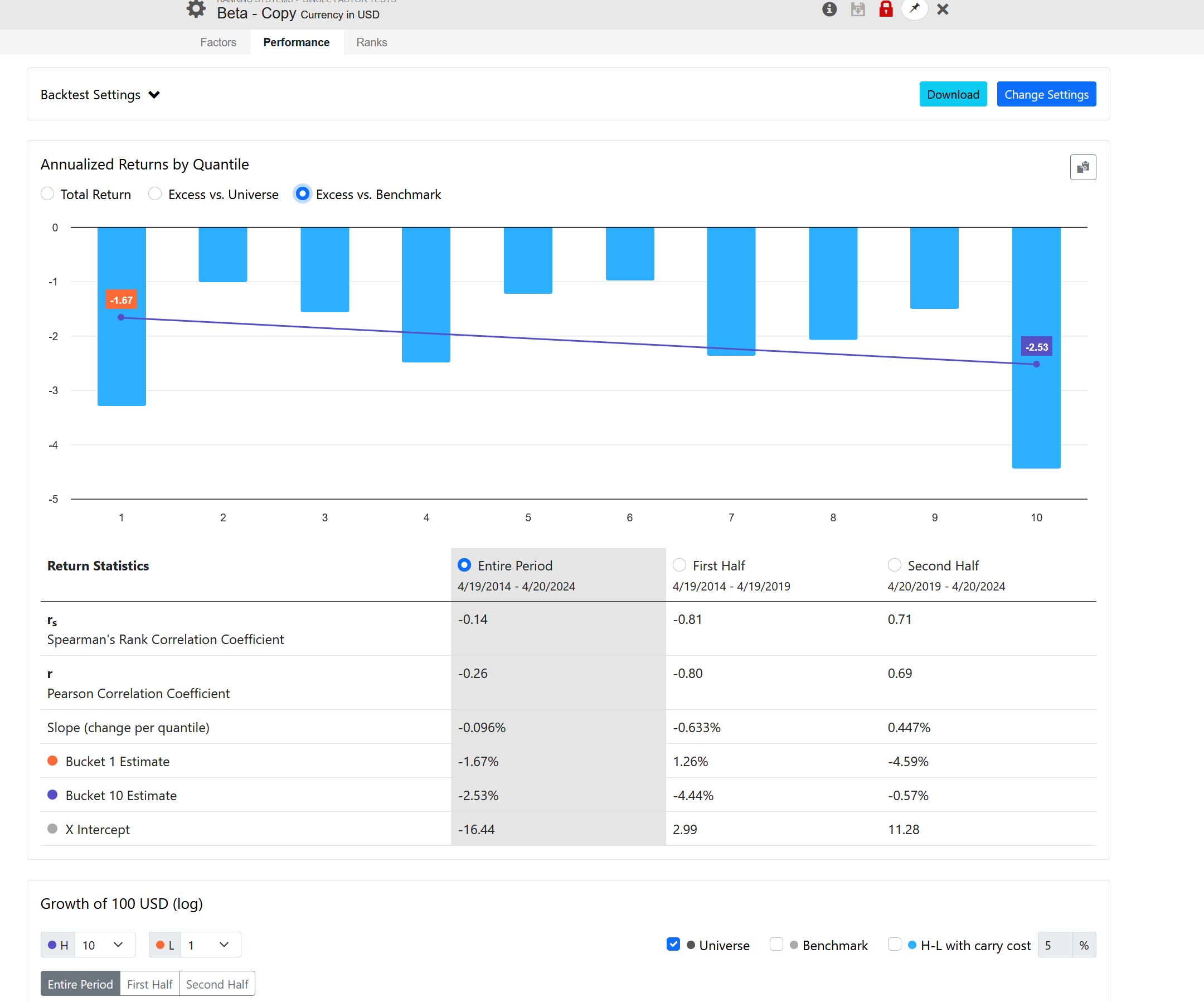
The same applies to a stock's volatility, which excludes its correlation to the index. Look at these results using 12-month historical volatility:
Just looking at a generic beta shows how this one metric is relevant and how we are not capturing it in our ranking tool. In other words, a stock with a beta of 2, in a bull market, will have an excess return of 2x the benchmark. That is not alpha. We need to control for beta
The same holds true for the volatility of a stock, which excludes it's correlation to the index. Look at this results using 12 month historical volatility:
You'll observe a similar impact.
In P123 models, we're unable to see the effects of beta or volatility on our ranking system. They remain hidden in our models, leaving us unaware of how much beta is influencing our systems. While others may develop "robust" or "all-weather" models, it's essentially layman's terms for persistent alpha.
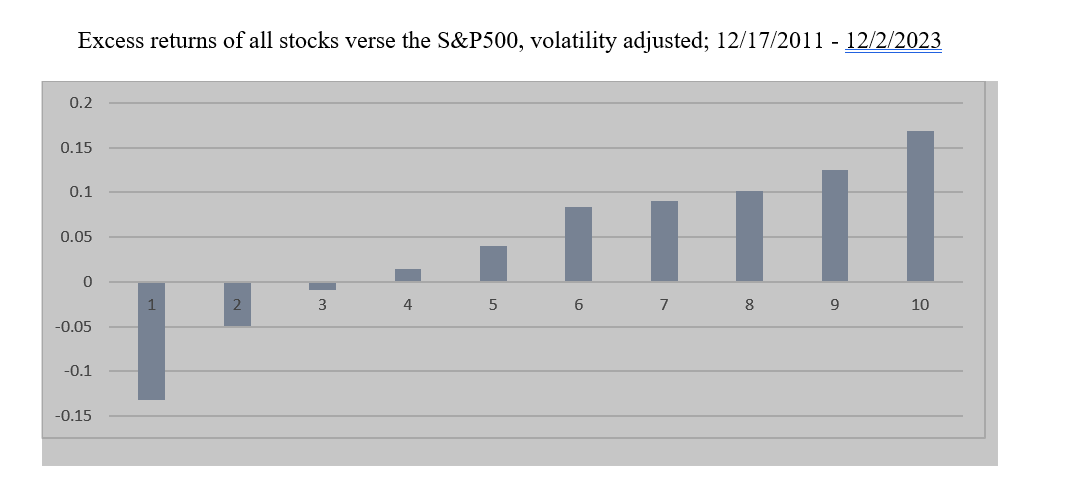
Lastly, here's a ranking system where I normalized volatility for each bucket, ensuring each bucket has the same volatility. See how clear the signal becomes:
We should be able to achieve this programmatically within P123, where the ranking signal for each stock/bucket is made equal for beta, volatility, and one which shows true alpha returns. This creates a much cleaner signal, allowing us to compare it against a benchmark or the universe for outperformance.
Does this explanation make sense?
- Correlation matrices are vital for managing risk. You previously shared a Google directory for these projects, to which I dedicated considerable time submitting spreadsheets and seeking feedback, which unfortunately never materialized. We need the backend database to calculate both covariance and correlation matrices for our individual universes or portfolios and then enable us to control things like beta or volatility effectively. These can be used most effectilinb in volality targeting, risk parity, and all the other portfolio managements you decribed years ago.
I hope this helped with the specificity of my remarks. If I was not clear, there are errors in my logic, anything else - please let me know. Thank you!