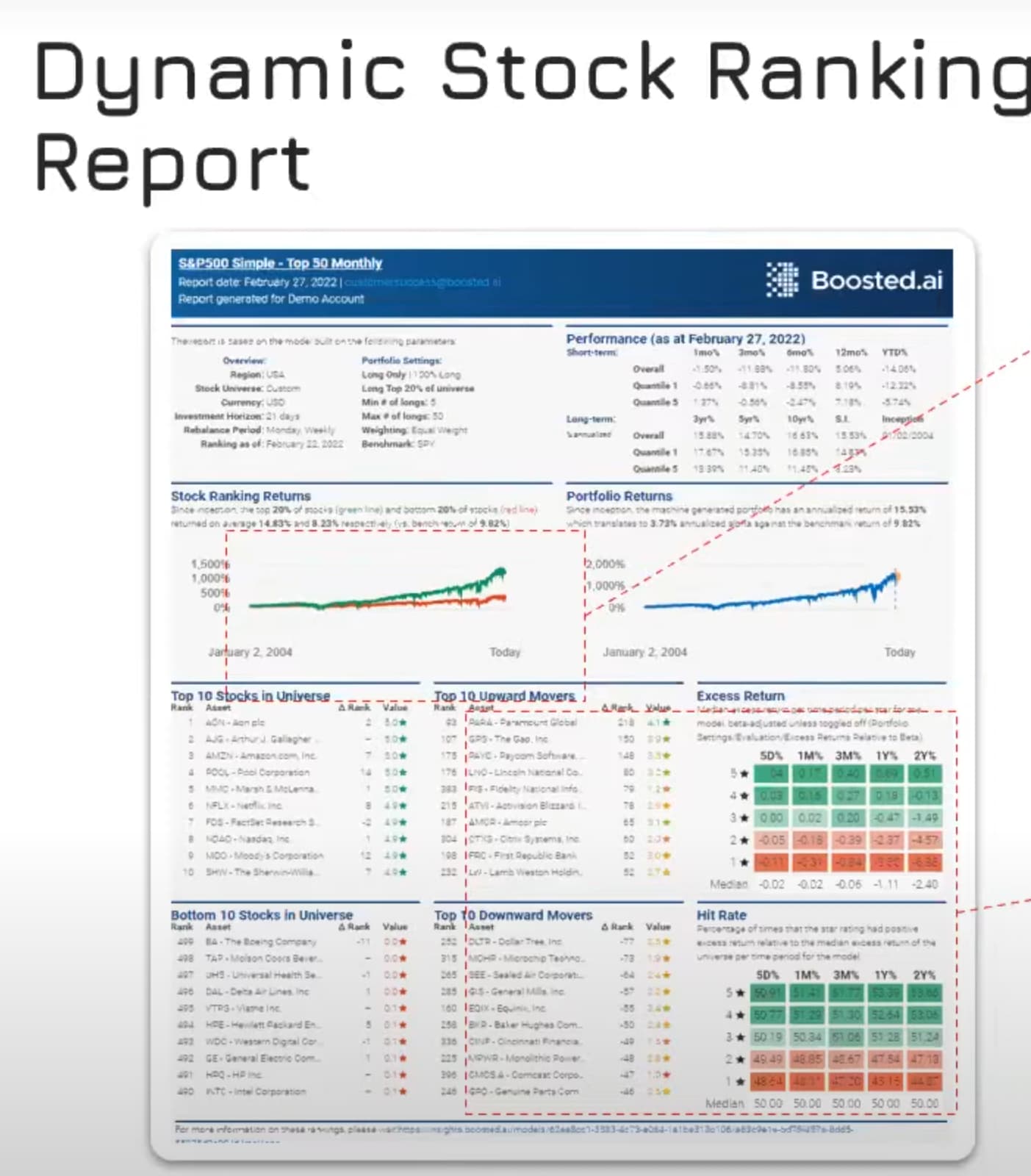
Well, how strange to see someone demo something eerily similar. These guys did it with about $40M funding (as of the date of the video). We did it with... let's just say a heck of a lot less.
Thoughts? What do you like in their version? Not even sure what algorithm is being used.
Actual product demo starts around 23:30. Terrible questions at the end of the video, no?
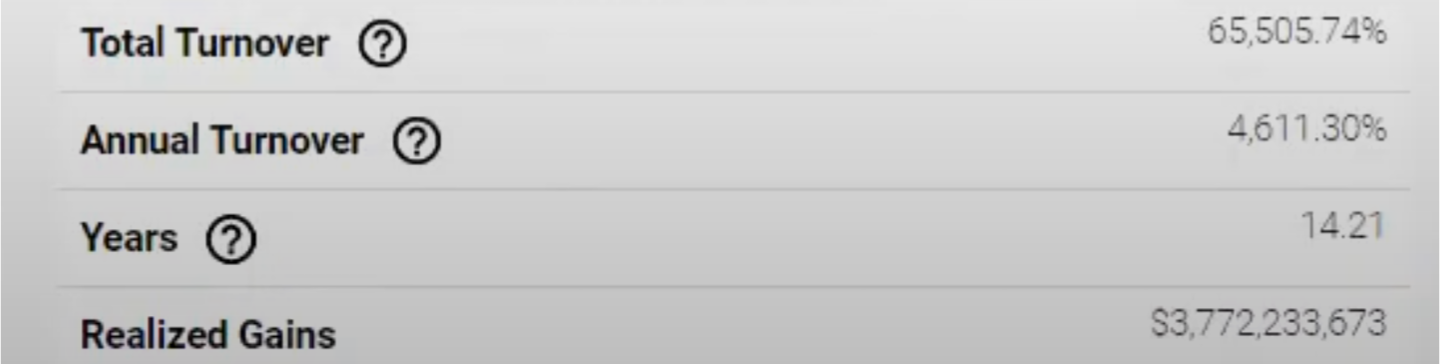
PS. at least in speed we're definitely doing better (around 27:40 the prediction took around 1 min)
So I had trouble watching that. It had almost no information.
The name would suggest it is just a boosting algorithm like XGBoost or LightGBM.
But as you say, totally lacking in transparency. Time series validation? Validation at all? Does it have a hold-out trade set? Maybe, as I say I could not sit thru it.
We do know P123 offers boosting (2 advanced methods for boosting) along with a wide range of additional AI methods and includes the ability to set most of the hyperparameters. The ability to control the hyperparameters is no small thing.
I would say that the only thing they have is a slick YouTube video but as I said I could not sit thru it. So maybe not that slick after all.
I do think there are low-cost algorithms that run quickly which could be marketed by P123 to even retail investors to increase membership while maintaining the strength of multiple advanced methods with good user-control (hyperparameter control and control of cross-validation methods) for advanced members. They are marketing to low-information investors and P123 could offer a low-cost solution to those people too.
But P123 mostly just needs to become widely know or to go viral in a sense.
Also while they had they had a "similar" idea, it is far from new or original. The Kaggle crowd is posting about trading ideas all of the time. The problem for them, until now, is the lack of access to the data. If they find P123, they can use the AI/ML or do anything they want with the AI/Ml and/or the downloads or API.
The link to this site just shows that the interest is already out there. This is just one example of that. They won't need a video to recognize the value of P123. They just need to find us.
They are being innovative with their LLM AI and sentiment algorithms, for example creating factors like "news sentiment factor" and reading 10-Ks. See their youtube channel. Geared for discretionary portfolio managers mostly. LLM is something we will start exploring next year.
Since their product is for discretionary managers, the usefulness doesn't matter. What matters to these dumb money is making those managers and "investors" aka gamblers feel easy and feel good.
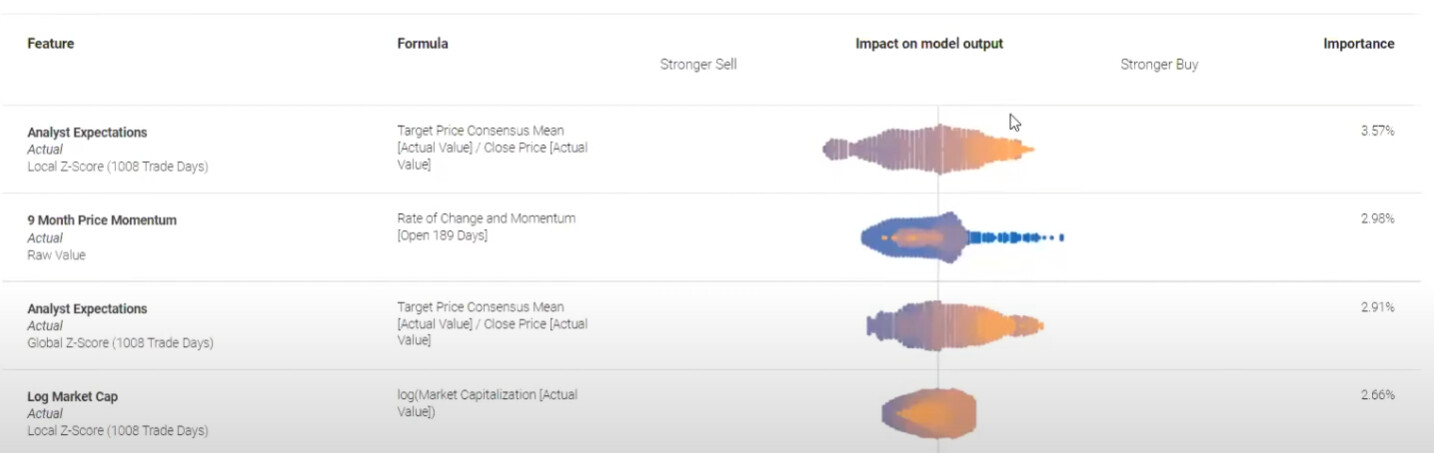
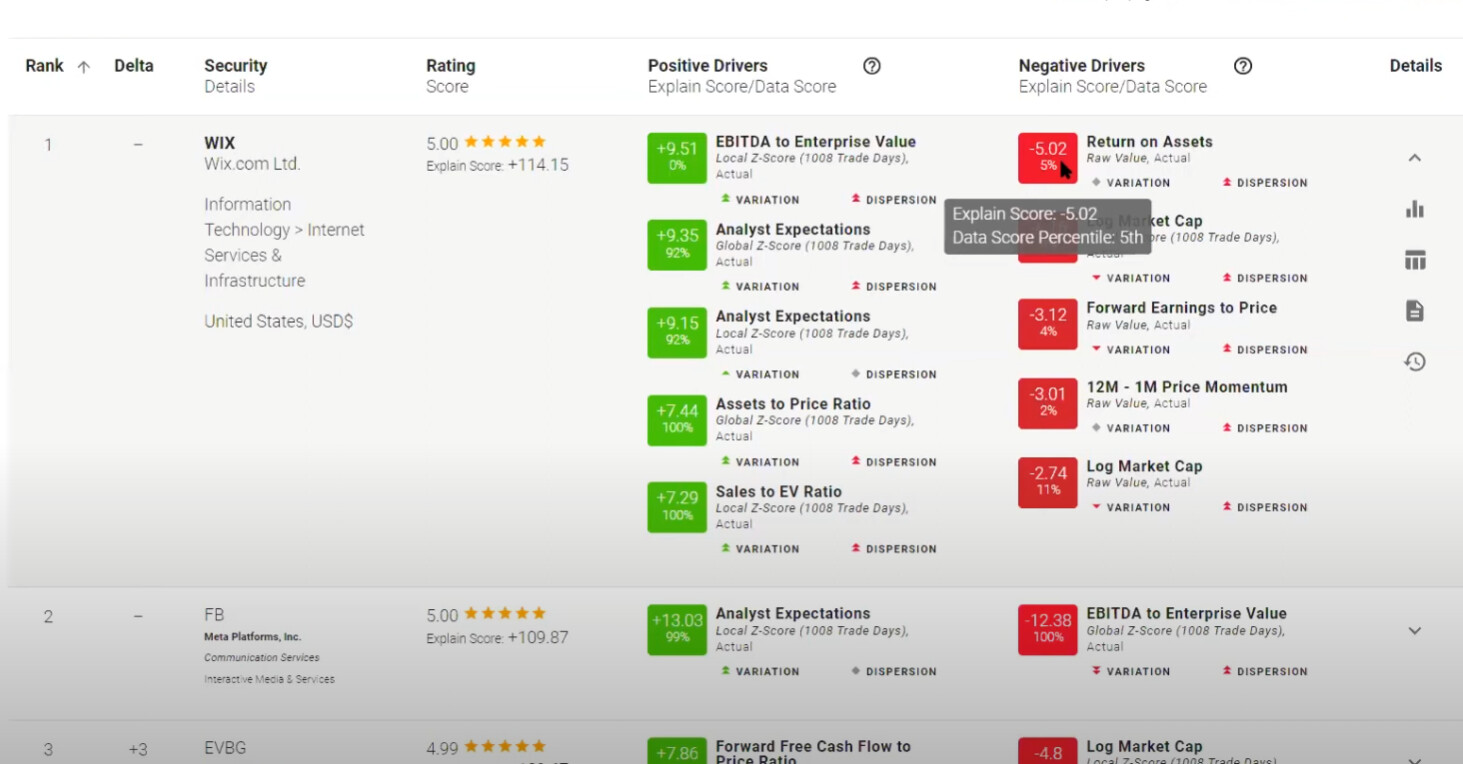
This is probably the most interesting feature they have that we do not. When they do the prediction the report shows the most positive and negative "drivers" of the overall prediction (not sure what variation and dispersion is).
Again, more geared towards discretionary manager, but still useful to get an insight of what the model is doing.
So if I were P123, I would just take the coefficient for the feature using a linear model and multiply the coefficient by the value for that particular feature. Rank times the coefficient if using ranks in your linear model, multiply z-score by the coefficient if using z-score etc.
With this normalization of the feature used. Keep z-score as it is but with rank and min/max normalize it so that a rank of 50 (or 0.5 of min/max) is zero (with negative ranks below 0.5 (with 0.5 transformed to 0). So that a company below the median or average gets a negative value for that feature.
So a company gets a negative value for a feature if the value for that feature is below the median and that negative value gets multiplied by how predictive that feature is (as determined by the model's coefficient for that feature).
They do some addictional things like find the historical range of this value for that particular company which could be useful, in practice, if there has been a recent change in the value for that feature. Like recent change in a value or growth factor for some reason. A recent change that may not be incorporated into the price yet.
As far as what linear model to use, it would not be too resource-intensive to do a GridsSearchCV of the hyperparameter for a ridge regression each time you wanted to generate coefficient for this analysis.
That is what you probably want even if they do it differently, but I think what they are doing is not likely to be so different.
So I guess they did some good things that P123 could try to emulate but P123's strength is the transparency of what is being done as well as the flexibility provided by the downloads. P123 is superior for those with enough knowledge to want to understand and control the ML method, IMHO.
I think there are a lot of people who understand ML but are not aware of P123. That may be where P123's greatest potential lies.
Thank Jrinne. We definitely need to do something in our prediction page to give more clarity. For example in our rebalance page we now have the "x-ray" feature.
Right now our prediction page is extremely simple. But, not sure showing the coefficient is what people want.
Pros especially want to know why a stock changed. Why it changed vs 1 week ago, or 1 month ago. And we need to make this easy and quick.
We're brainstorming this. Probably we'll create an "enhanced predictor" that stores the dataset every time it's invoked. This way we can quickly show you the changes in predictions, and what is driving them.
Hi, I’m curious about interpretability when AI models complete their factor calculations. It still feels like a black box. Beyond factor importance, is there anything else we can examine to understand how a decision or ranking is determined?