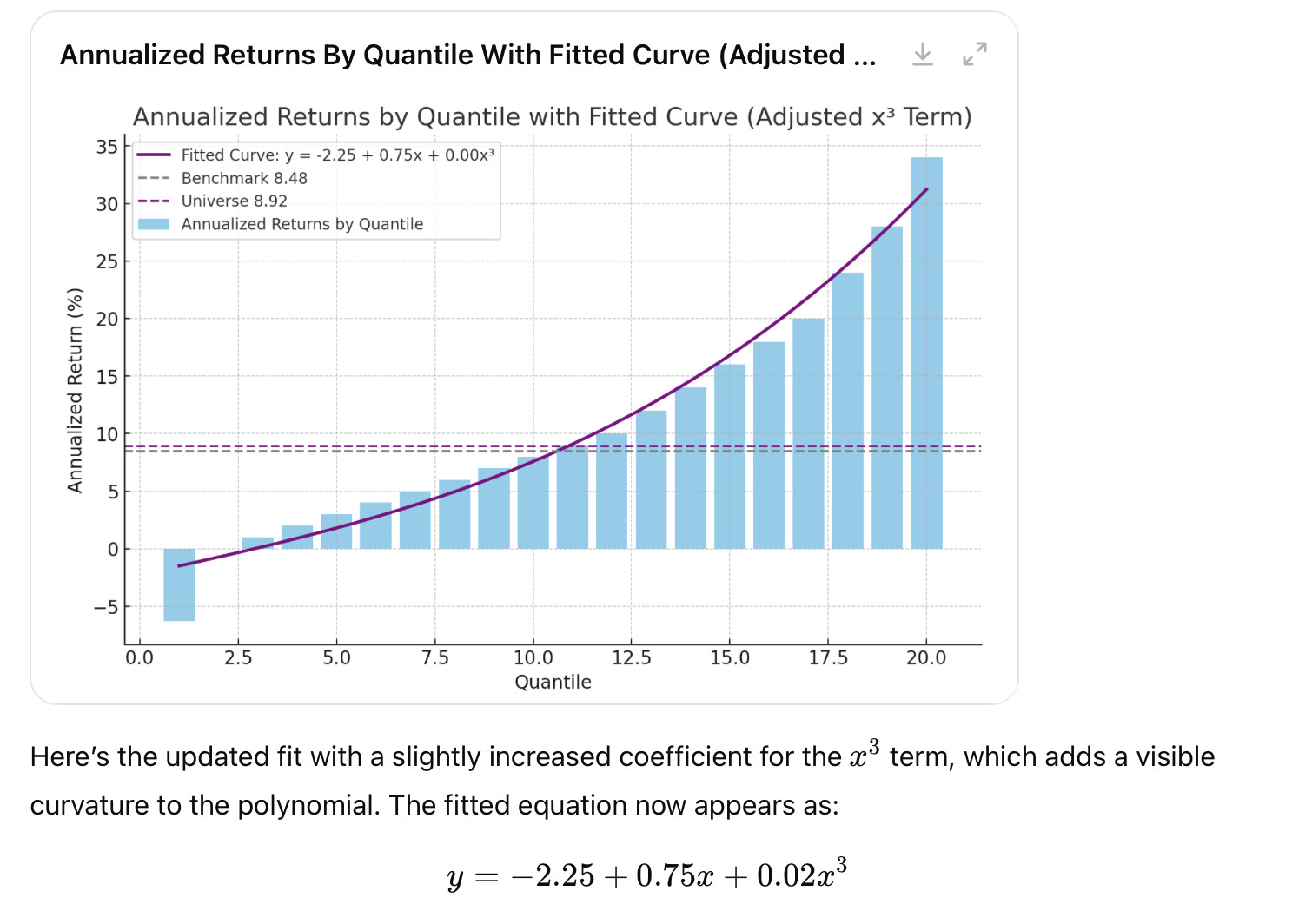
To limit the overfitting to some degree i used only monotonically increasing factors and x^1 and x^3 are naturally fit to monotonically increasing (or decreasing) factors so I limited the polynomial to these (excluding x^2).
And of course I wanted to save some time so I did it with Python code; "Total run time: 10.58 minutes" And I think it is true that Polynomial regressions are relatively efficient compared to many Kernel Regression methods.
Everything is decimalized and not in percent (I need to change that). So annualized return is 43.6%:
This is a walk-forward backtest for 15 stocks over a 10-year period (five 2-year test periods). It is not a substantial improvement over some of my other models, BTW.
Thanks for the ideas, Yuval and ZGWZ! It could probably be tweaked and made useful but I am not necessarily recommening it based on this.
For those interested in other types of non-linear regression, IsotonicRegression was a huge fail for some unknown reason. But it gave bad answers quickly (it was efficient). So there is that at least.
Sorry for the noob question. That would be the performance metrics of a x & x^3 model of a set of factors? I think i am missing something here but curious to learn.
So Sklearn for what I did uses this equation y = c + ax + bx³. Generally it finds the a, b and c constants that minimize the mean squared error or (MSE) but you can use other metrics.
I gave ChatGPT a rank performance test and asked it to fit the rank performance test visually. It looks like there may be some "artistic liberties" taken by ChatGPT but I think the illustration makes the point.
I think this is a better fit than a straight line for sure, but not perfect in this example or in practice.
You can add higher order terms like x^4 and x^5 as high as you want. But as ZGWZ correctly points out, higher orders have a greater risk of overfitting,
This helps a lot, thank you. To verify if a factor is suitable to be used this way you would need to download it and subsequently let the PC find the coefficients, correct? I can see the risk of overfitting, but keeping 2 years of out of sample should relatively mitigate it. Another way i believe is to constrain the algo to find solutions with intervals of 0.1 for example, or 0.5. This way you are limiting the "liberty" of the algo.
You are way more experienced on these topics, do you think these solutions would help and is my interpretation correct?
Thank you. I always like to read you but not educated enough to understand your posts on AI and related topics.
My post about polynomial regression was inspired by your post about middling factors. What I did was similar, I think, but plugging what I did directly into P123 classic is difficult. And the resulting ranks in P123 classic miss the change in slope that I was looking for. The gentle upward curve, in other words. The ranks will not be changed in the example above. In more technical terms the ranks will not change in a monotonically increasing function and this will always be a compromise with P123 classic.
I think aschiff and Dan respectively had good posts that will help with your original question:
I think those work and are relatively easy to implement with P123 classic. Polynomial regression is something to try when you want to do machine learning with P123 data downloads, I think.