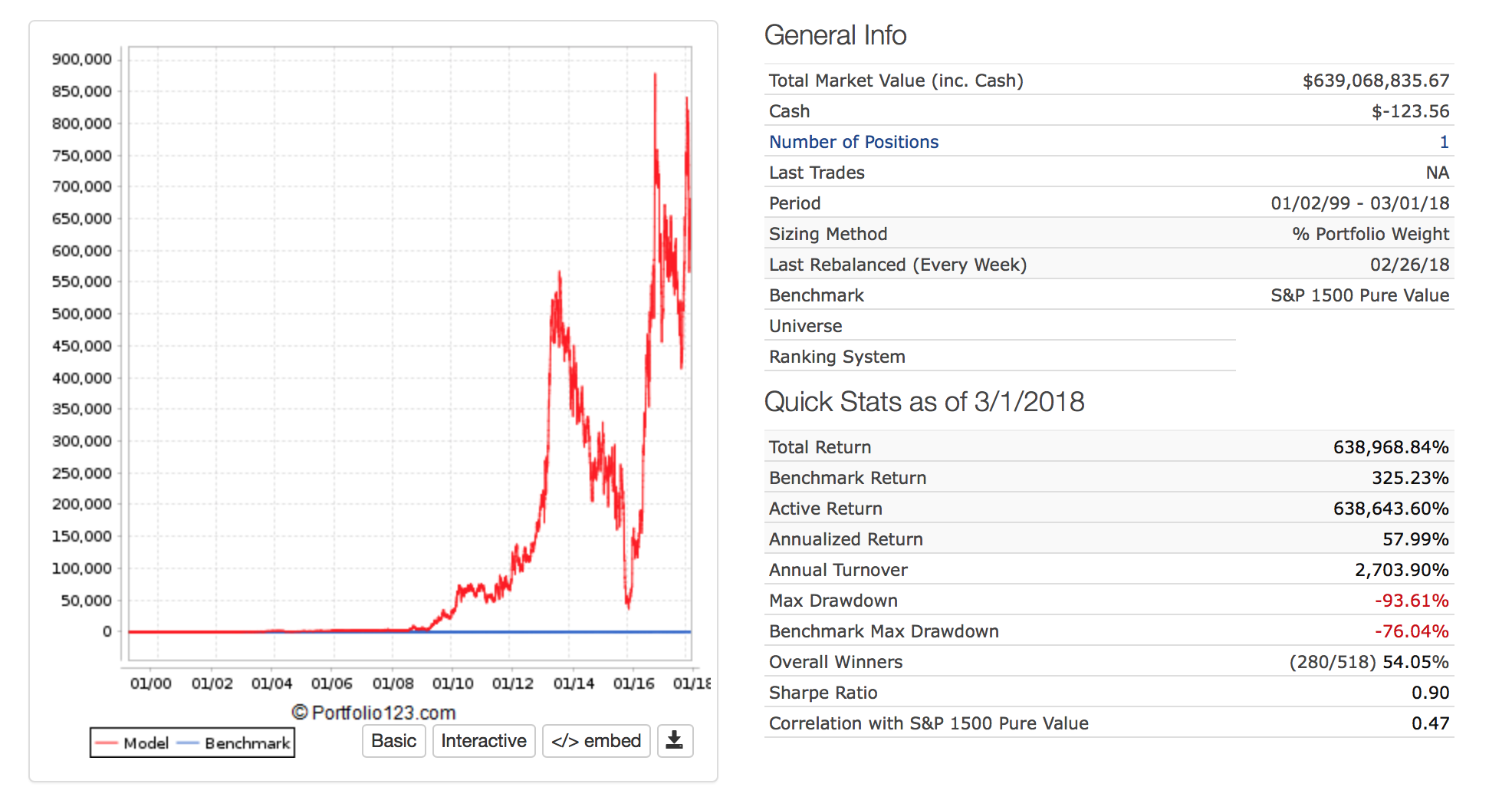
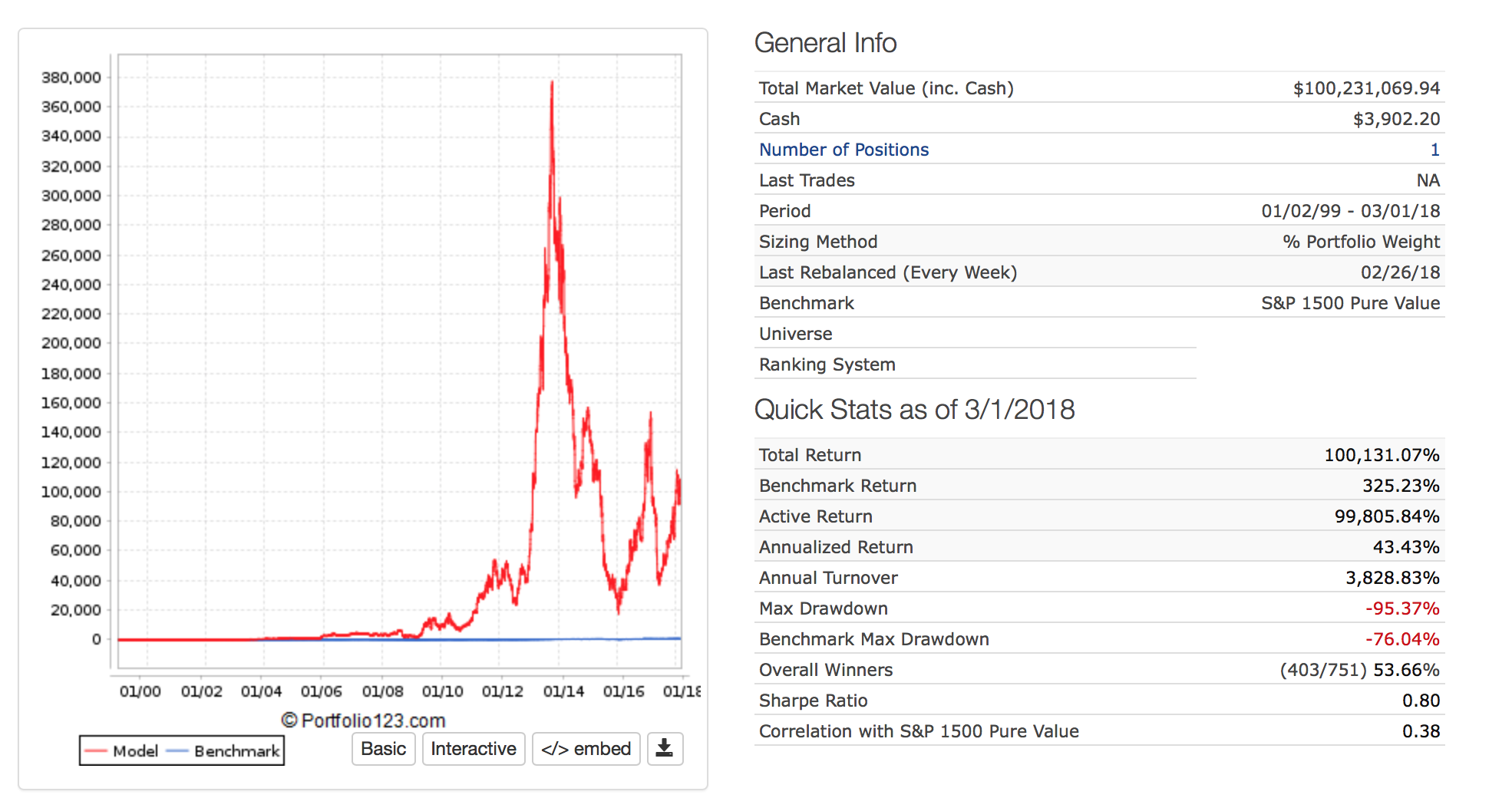
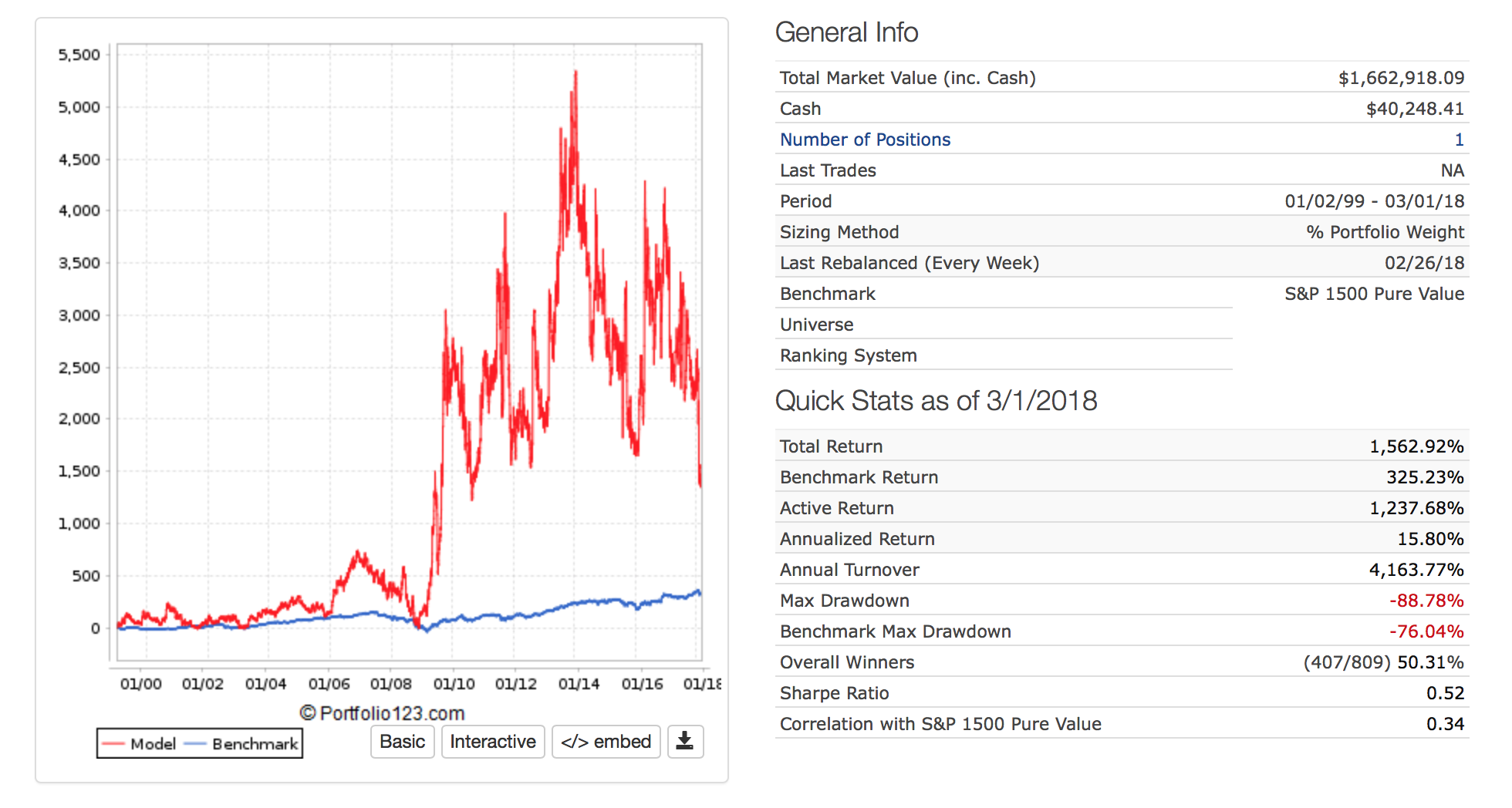
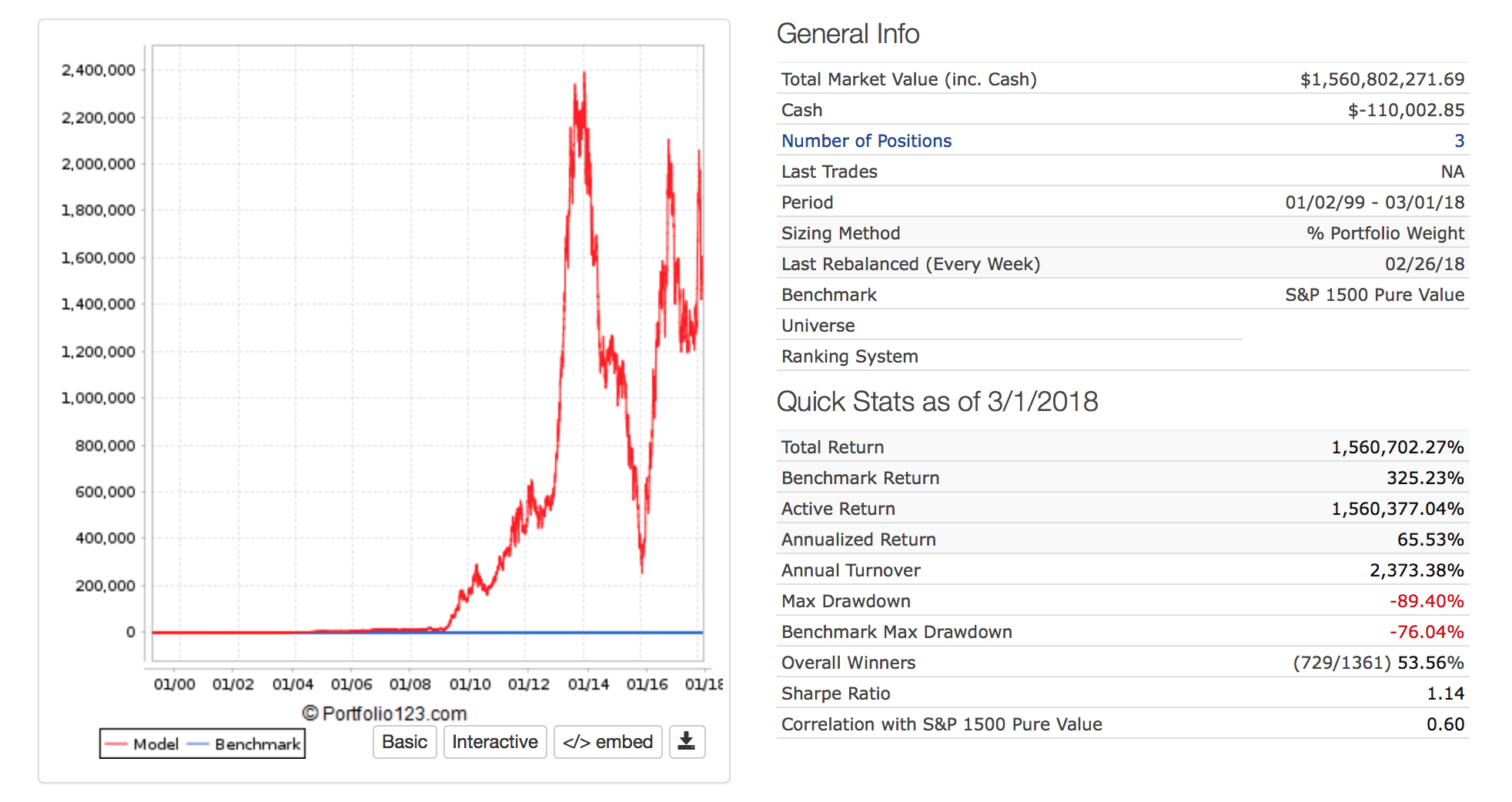
I find Kelly betting interesting. Usually (maybe always) the formula really does not work for stocks. Here are 3 formulas.
Kelly #1: x = p - q/(W/L) = (pW - qL)/W
Kelly #2: x = (pW - qL)/(WL)
Kelly #3: x = (pW - qL) / {pS2(W)+pW2 + qS2(L)+q*L2}
where
W = average of the Winning returns
L = average of the Losing returns
S(W) = Standard deviation of the Winning returns
S(L) = Standard deviation of the Losing returns
p = probability of a win
q = 1 - p = probability of a loss
Here is a link with a calculator for the first 2 formulas: Kelly Ratio
The first only works if you have predefined wins and losses that are aways the same: like at a Blackjack table. Also, it assumes that you lose your entire bet–again like at a Blackjack table.
The second works for average (partial) losses and average gains but of course we have a range of losses and gains.
The third uses the normal distribution to calculate optimal Kelly based on past results: the mean and standard deviation.
All good except if I had used the last formula it would have recommended the use of leverage for “Full Kelly.”
The problem is one of the months I would have gone bankrupt with that much leverage in the sim I was looking at.
I do not know if the lesson is do not use Kelly betting, do not use “Full Kelly” if you do, or the stock market really does not follow a normal distribution.
Mostly for fun.