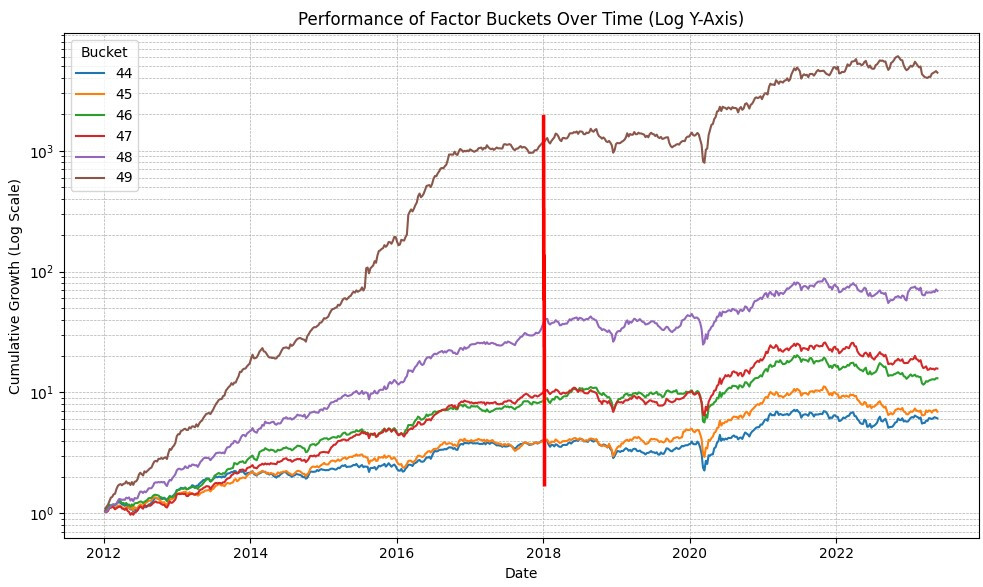
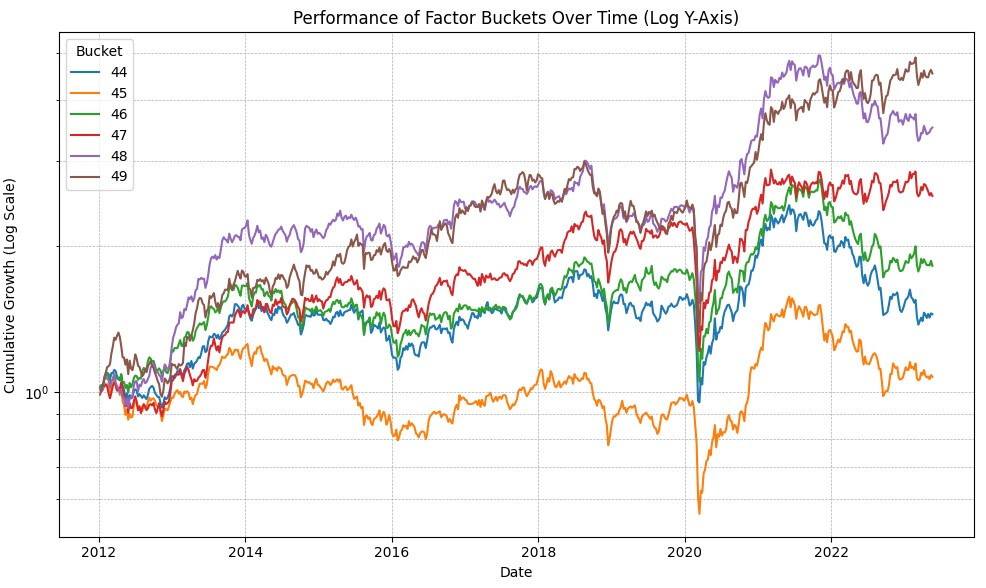
I wanted to share some of my observations/thoughts on python api downloads for ML. If others have any they want to share I would love to see them! I plan on adding to this if I find anything else of interest.
Observations/Tips in no particular order
- The API downloads factor ranks based on the Sunday night (thanks Walter for the correction) before, you cannot get midweek data even if the asofDate you use is from the middle of the week
- Many ML methods should be able to use "non-linear" factors like a "hump" shaped performance plot without wrangling the factor to make it "linear". However, be aware this requires careful consideration of NA handling. I think Negative NAs are usually the way to go for non-linear factors with a "hump" shape, but that is just my conjecture. I read a factor investing ML handbook that suggested backfill treatment of NAs, but we do not have that option at the moment. https://www.mlfactor.com/ (thanks InmanRoshi for posting it in Feb 2021)
- Its unclear to me what requires a PIT license, but the api gives a pretty clear error if you request a factor that requires it. Things like price data do not require it, but fundamentals do.
- Use the screener to check out factor values to see how it translates to a rank. It took me months to see that screener will give you the actual factor values... You run the screen and then select the screen values in the outputs.
- Composite ranks do not appear to use more API credits, but the ranks do show up in the download, at least top level composites do. That being said, you should be able to make your own composite ranks after downloading.
- As noted in other threads (thanks Walter) the Future%Chg function is Friday close to Friday close! If you rebalance on a Monday it would be as if you bought your stock on the previous Friday. Use (Close(-6)/Close(-1)-1)*100 or something similar instead.
- If you combine multiple ranking systems into one for a download make sure you eliminate duplicate factors and that all factor names are unique. If not it will probably mess you up later and use more credits than needed.
- Start small before you go for the big download! I have revised my ranking system 3 times, my universe twice, and my downloaded data 7 times in the last two days to fix things like -inf, column naming problems, and missing or unneeded factors.
Info from a mid sized download:
- Input: 5 years weekly, 89 factors, ~2200 stock universe, ~600,000 rows and ~53 million data points!
- Credits used: ~2200
- Download time: ~4m
- Size on disk as pickled pandas dataframe: 451 MB!
- XGBoost model training with 5 folds took ~20 minutes. Results in-sample are too good (600% annual), and out of sample (a year later than training) are too bad (way less than the original ranking system).
Thanks,
Jonpaul