I implemented early stopping today and I think I am doing it right (stopping after RMSE stops improving). Interestingly it did not fix my in-sample vs out of sample performance issue, at least not that I could tell. My code is changing a lot and I switched from colab to my desktop and got different results so I don’t have a 1 to 1.
I trimmed my training and validation data, but not the “OOS” data, and it did not fix the issue. Then I trimmed just the training data, not the validation, and it almost doubled the “OOS” returns! Still way less than in sample, but better than the equal weighted ranking system.
I have not figured out how to directly increase leaf size in xgboost yet, but min_child_weight which chatgpt says is similar did improve the returns a lot more than a 1% trim, but I had to set it to 1,000 and chatgpt says normal values are 1-10…
Huber loss instead of RMSE did improve my results, but not by a very large amount. The min_child_weight had the largest improvement on its own.
All combined methods are worse than just the large child weight.
Once again thank you for the suggestions! While I could probably learn these things on my own it would take a lot longer without the community.
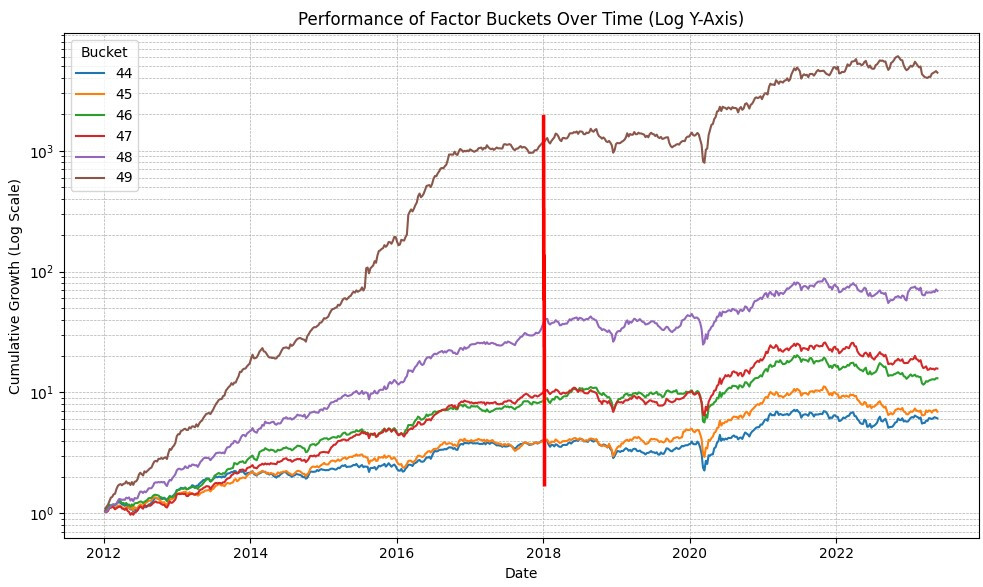
Also here is an interesting plot for those who are curious what the in-sample vs out of sample performance looks like for a 50 bucket “rank performance” test with kind of variable slippage (mean 0.3%) on a slightly modified core combinations ranking system:
The red line is where my training data stops and my “OOS” data starts.
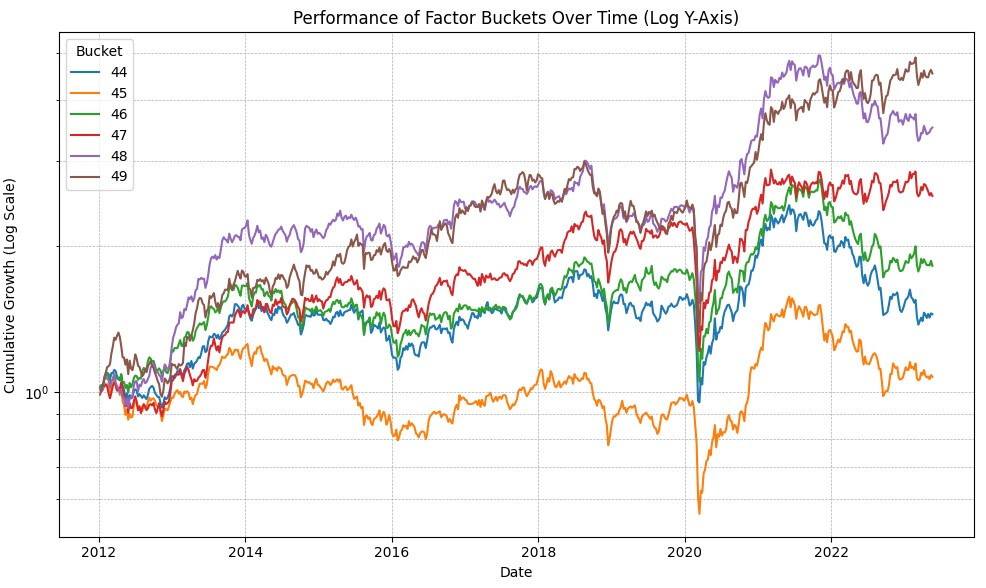
Core Combinations using the ranking performance method I coded:
Note 20 buckets look similar to the 50, its just around 17% annual OOS vs 27% for the top bucket on the ML algorithm. Also I ran a simulation with a similar ranking system, universe, and stock count and the simulation has an annual of 20%. I think a big part of the difference is my code back test for the ML and equal weight ranking apply the slippage penalty every week (although only buy), so I assume a turnover close to 25x… Without slippage I get about 22% annualized return on the equal weight port and 40% annual on the ML. So I need to make my back test code smarter to look at actual turnover. Anyway its starting to look very promising if ML can double the “OOS” performance of a ranking system.