Yep, I forgot many things from that stuff. Maybe later I can say anything for sure regarding stochastic processes ![]()
Actually there is no big need to go deep in math. Models that really work are quite simple.
You can correct my memory but my recollection is that a stochastic process is normally distributed by definition. The stock market isn’t.
Steve
I think Jim can make separate theme discussing that things.
I think that you and Jim clearly have too much free time on your hands that could be utilized on other endeavours ![]()
Steve
Steve,
Only you get to spend all of your time talking to Yury?
That is called “weakly stationary”. There is also strong stationarity, which basically means that the underlying distribution of the stochastic process does not change over time.
That is not necessary at all. You can model a stochastic process using any kind of distribution.
In timeseries analysis, you want to model/analyse something that is “stable” over time. The simplest example is when there is a trend in the data. For example, the S&P500 index has an upward trend (in the statistical sense). The easiest transformation is to take first differences. That means you wouldn’t take the index as is, but you’d take the difference between the index on each day and the day before that. Now you’ve got data that is confined to relatively narrow range.
However, because the day-to-day changes get larger (in absolute terms) as time goes on, the range of values you’ve got in the data keeps expanding little by little over time. That’s still not “stable”. So in this case we would prefer to transform the index to percentage changes (daily returns). Now we’ve got something that stays in a relatively narrow range: the daily returns of the S&P500 in 1960 were probably similar in magnitude as the daily returns in each of the decades after it for example.
Of course financial data like the S&P500 index exhibits time-varying volatility. Strictly speaking, this means that even the returns are not weakly stationary (the second moment, the variance, changes over time). You could use GARCH models to handle that. But for simple linear models, this is not so important I think. The first moment, the mean, is much more important.
The key here is that using prices or indices as the dependent variable is usually wrong, you need to work with returns instead (as Yury has been doing).
Jim, my MT model is simple expressing in math. Return = MT function(f1(t), f2(t)…) + e,
where is function - deterministic linear function of factors f, f(t) - factors dependent on time, e- stochastic deviation with stable distribution over time (stationary) with zero mean. Also I assume f(t) is constant over time to avoid overfitting. To get higher correlation to future return you can use not constant factors as me, but variable as Hull (it means he add or leave factor over time through screening procedure). That’s all. Nothing you can do with stochastic component. You can try to model it using stochastic processes but there is no need to do that, accuracy of forecasts won’t be higher in practice.
Be carefull with correlation and Regression. they are based on an assumtion (normal Distribution), Stocks are not normal distributed, they
have fat tails, very ofthen a strategy goes for those fat tails, and would not work if the fat tails would not exist.
At least this is the case with my Systems…
Regards
Andreas
I agree, stochastic component e has not normal distribution. But nothing we can do with fat tails and black swan events. I dont’t model it. We can buy put options if we assume that black swan events risks are not priced efficiently in options, that’s all.
Peter,
Thank you for your clarification. I’m going to assume Yury’s 9 other factors that he speaks about for MT are stationary too: after reading his post (and thinking) the normalization may be helpful in this regard. Not speaking for Yury but for me personally, using time series data would have the risk of showing a false correlation that would never materialize in my trading. I would probably never know why.
One attractive (theoretical for now) feature of the appropriate use of OLS is that it is not really optimized. It’s just the function you get the one time you do the math (or run it in Excel). OOS similar to IS? I intend to find out. But I’m also willing to scrap the whole idea. There are a lot of assumptions starting with should I even be looking for the line of best fit? Is the distribution even linear? Linear even at the extremes for a 5 stock model say? I think you already said it does not work well for 5 stock models. Those outliers that really do not fit the regression line can sure affect your bottom line.
Yury. Looks like you are on the right track. I encourage you to keep going but do pay attention to the details.
Warmest regards,
Jim
1. What we currently have in P123.
We have daily updating point in time data base, ranking tool with a lot of factors, permutation tool for ranking and simulation, rolling test, hedging, books, macro and getseries sections and many other things. So ok.
It allows us to make quite good systems with proper approach.
But, I don’t understand the following (I’m maybe wrong on some issues):
Why does the getseries tool allow to use only universe operations? Why macrodata is not available there?
Why can’t we download in excel info from macro section? Why is macro composite Boolean market timing index not available for hedging purposes in ports?
I think that stuff is easy to do.
2. Must have features:
A) Variable hedging based on MT index. Which in turn constructed on macro data and stock universe specific data. Everyone understands it’s importance.
B) Results presentation. All parameters should be presented year by year from specified starting point (not only calendar years). Performance graphs everywhere (including rank performance) have to show alpha instead of simple return (better to have a switch option between return/alpha)
C) Variable port weights into the book based on set up rules – MT index for example. It is clear too.
D) Pearson and Spearman correlation of separate stock-alpha distribution for specified rank percentiles (for example, the whole range 0-100%, or top 10% only). Using these numbers we can check rank robustness and reliability.
E) Average rank performance (and simulations too) during specified time periods combined (we can do it through permutation tool now, but we don’t see the average results) . It will allow us to quickly optimize systems on assigned history times frames (not full 16 years period as in R2G)
F) Allow short ports and books in R2G, change IS to rolling test, make more strictly disclosure requirements etc, I don’t want to repeat, many things were discussed already several times.
G) Borrowing fees and availability for short ports
3. Desirable features:
a) Individual position variable weights allocated on specified rules, proportionally to stock’s rank for example.
b) Global coverage or at least europe
c) Daily rank recalculation
Regards, Yury.
Concentrated ranking and combined forecast model.
In ranking histogram we see two dimensional space rank-return, or lets say ranked factor-alpha (correct view).
As I mentioned in previous posts the larger time frame for the ranking system simulation the smoother the histogram.
In other words the greater correlation between factor range (rank percentile) and realized alpha (within the time frame when stocks lie within that percentile).
We don’t see that correlation because we can divide our 4000 stock universe only to 200 percentiles. That means every percentiles consists 20 stocks that placed somewhere on rank-alpha graph within it. But we can see larger scale correlation across different percentiles (percentiles deviation on graph is low within quite small ranges, lower number of outliers in other words) and high overall ranking slope.
The smaller simulation period the less number of stocks were used for distribution, the higher stochastic not compensated component and the lower the overall correlation. It is totally clear then you use 1 years or 6 month instead 16 years for test. But due to cyclical factors nature (and maybe not-monotonic) very large time frame is bad too. It reduces ranking performance in tests. It is clear too. For example if we imagine 3 dimensional space again with x axis as stock specific factor (explains alpha waves) and y as market timing index factor (explains beta waves) and z as total risk adjusted return (inludes beta and alpha) we ll see that for different MT range value correspond different factor distribution (which we see on our ranking histogram). At some time it gets high correlation at some zero and even negative (for example volatility factor during bull and bear market). Combined MT and stock specific model forecasts returns on each stock.
Using concentrated rank especially without appropriate market timing model is very dangerous. It becomes even more dangerous when along with such a ranking you use very limited stock holding number (when stochastic component not compensated enough). Especially on shorter time frame periods (when correlation is low no matter which factor you use).
Each layer imposes on each other (negative beta, not appropriate factor for specific market conditions - negative alpha, plus negative stochastic realization), and you can huge drawdown even if the market drops only for 5%.
Also about factors and smart beta. Recent smart beta strategies popularity growth gives us very attractive opportunity. Mentioned alpha waves becomes larger and longer (creates alpha momentum by itself), small money investors can jump and dismount very fast achieving their first tier alpha in comparison to smart beta ETFs.
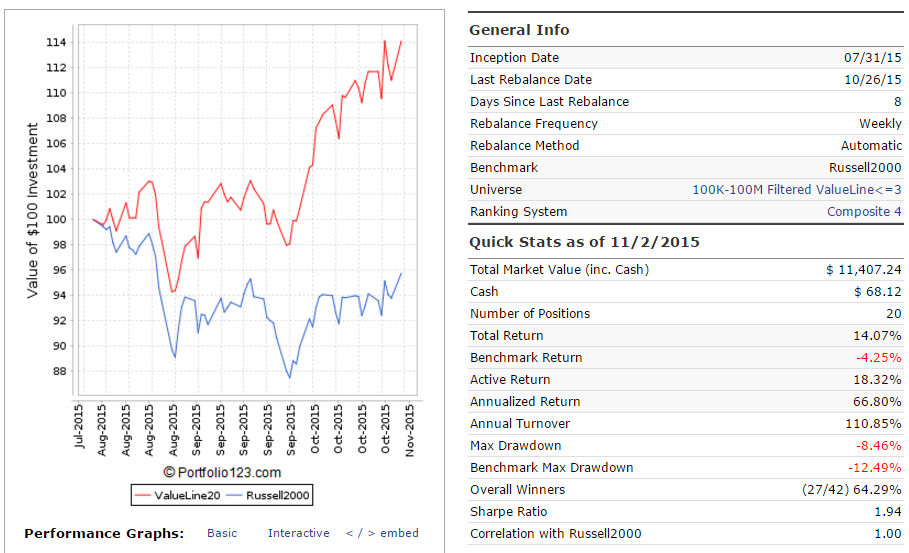
I wrote that daily rebalancing is a desirable feature. But floating rebalance date for R2G is necessary thing. Because for example I have attractive valueline based port (just in the best R2G traditions of 50%+ returns :), but it can’t rebalance on monday because of valueline data delay.
smart-beta-defining-the-opportunity-and-solutions.pdf (881 KB)
Hello, everyone.
Here I put some thoughts about our endeavors to make good ports in P123.
1. Small liquidity and high return systems.
Ranking performance convexity (ranking graph is not linear, highly increasing/decreasing at highest/lowest percentiles) leads to potentially higher return ports.
It is clear that very few and huge outliers is the major part of that phenomenon. If ranking systematically captures these outliers based on robust and economic logic it is ok.
Theoretically in that case you can get 50%+ of annual return using last percentiles of concentrated ranking and low number of stocks. But there are some problems associated with that:
A) Liquidity will be very limited anyway. Most of that outliers are small and microcap stocks that lack liquidity. The total number of that stocks is also small. I estimate total daily liquidity of that outliers approx. at 20*300K = $6M or lets say maybe $10-20 mln not higher. And that amount is dividing across all extreme alpha seekers worldwide and they make 50-100%+ annualized return on that deals. So in absolute terms US outliers annual alpha is about several billions, not much comparing to the industry.
B) Port return stability is lowering. Not only because of my previously mentioned reasons but even according to fundamental law of active management (that I personally dislike because of some problems associated with it and quite theoretical meaning) which states that
IR = excess ret/ st dev of that ret = ICN^0.5TC,
where IC – correlation of our bets to future realized excess returns (which should be high in our case),
N^0.5 –breadth, number of independent bets, in our case it means number of stocks in universe, in port and higher turnover.
And TC – transfer coefficient, trading costs in our case for simplicity.
So if we use small number of stocks N will be low leading to higher tracking error (st dev of excess ret).
C) The main problem is system design by itself. Using very concentrated ranking leads to undesirable and inevitable capturing of other factors along with wrongly chosen basic factor itself. For example very extreme valuation (which again could be wrong for example in recession periods) leads to higher volatility that has negative impact especially in volatility market. You simply strengthen negative effect by using it. In that case it should be used not for long but for short positions instead. So in my view using 2-3 themes in ranking is required. Also I recommend to use balanced ranking with many themes and factors before concentrated ranking for filtering purposes (using buy rules, the better approach is to filter universe, but we can’t apply ranking to make filtered custom universes). But the best approach to make high ret system is to use factor timing model which is not available in P123 now.
D) Several simple robustness tests like rolling test, half universe test (ID = 0/1, actually it is not appropriate test for large systems with many stocks 50-100+), ranking system rolling test would reveal fitted ports very quickly if it actually takes place. Therefore it is so important to have an access to that tests for profound investors/subscribers.
2. Stable higher liquidity systems.
A) By using only highest ranking percentiles we miss more stable alpha (and much bigger in absolute terms than outliers) existing in the rest percentiles of ranking. Especially it is important if correlation to future realized alpha is more or less stable across all ranking percentiles (but I think correlation is higher at extreme percentiles). If we get a tool calculating correlation of ranking to each stock excess return (it is very simple to make), we could choose such stocks (showing greatest correlation) for port and weight them by ranking (needed variable position weight). Such port will show very high information ratio and high liquidity required by hedge funds.
B) So now P123 inherently focuses on development of type 1 ports. Also we inherently tilted to size factor (because we have only equally weighted positions) which is not good too. Therefore the right benchmark for all ports shouldn’t be the cap weighted indexes like S&P500 or Russell2000. P123 should make equally weighted substitution for all popular indexes (now we have only eq weighted S&P500). In other case we show misleading information to investors.
C) Factor timing. It is especially important for short ports. It is hard to do such a system in P123 but it is possible to make smart beta ETF universe and separate them by themes (used factors). Then it will be cost efficient to use such ETF for shorting purposes (and for long too) when factor timing model (created somewhere else not in P123 as market timing models we use now) showing you to short specific factors. For example, short small cap high volatility index etf during recession. Or short large cap low volatility during bull market, whatever you believe in other words. It will be very convenient cause you short or buy only one or several etf tickers instead of hundred of stocks and cost efficient because of much lower borrowing costs of etfs in comparison to stocks.
So must have features to make “investment grade” ports are:
· Variable position size
· Correlation parameter mentioned above
· Results presentation methods written in the previous posts (for example current total return graphs are very misleading, at least it should be presented on relative to benchmark basis or alpha, because when we visually see very good performance two years ago and current performance is bad on graphs it looks like it is very good system with euiqty curve far above a benchmark)
3. Some critique of P123.
A) R2G section. I don’t care much about designers and their subscribers. I created my R2G ports mainly for independent verification purposes cause in live ports I can change it manually (I should show pure strategy without any manual manipulation). But while they are the major source of income for P123 (and I care about this platform) I think that absolute prohibition of any kind of IS simulated results is not the right move. This action just cuts the major part of information about any system (good or bad, newly developed or even launched long time ago). It won’t be useful to nobody - not to designers nor to subscribers or P123 team itself. The right thing to do expressed in point 1D of this post. If investors-subscribers are not willing to make such test or don’t understand it then P123 team should make it by themselves automatically and publish the final result in R2G. In other case P123 would lose some portion (maybe big) of their so far small income.
But there is one conspiracy reason that they don’t want to show proposed tests. They made that tests by themselves for R2G ports and saw terrible results and decided to simply hide it all ![]()
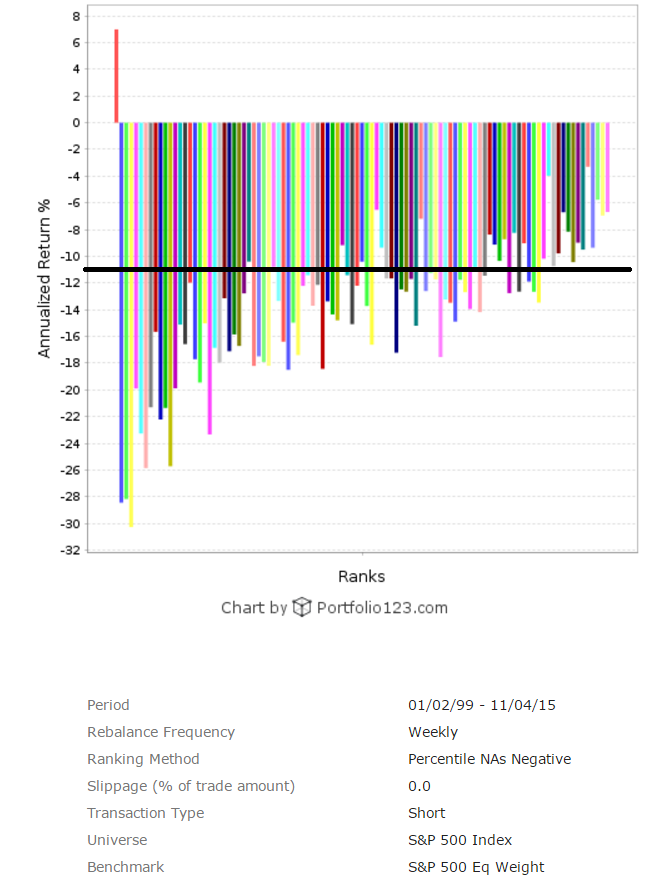
B) I checked one thing recently. Return of S&P 500 eq. weight benchmark and the average performance of any ranking system from S&P 500 universe should be the same. But as you can see from the picture below it is not. Where is error?
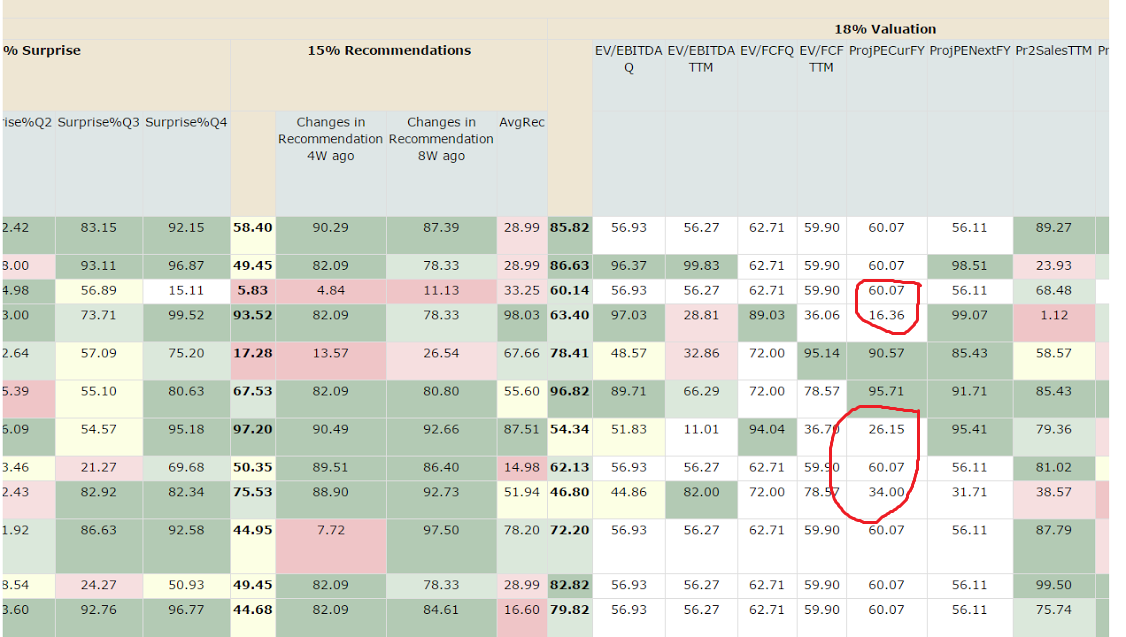
C) I wrote to P123 support about ranking systems and its NA handling types (negative and neutral). I saw that some ranking systems work in a strange way. I attached examples where neutral and negative ranking show the same values for missed data in factor table (rank at the moment with separate factors values and companies). And it wasn’t the same factor value for missed data for each company as they state. It was completely different for different stocks. Nobody answered to that request (more than a month passed, they usually answer quickly). All that things reduce the credibility of the platform. Especially assuming how much money we spend here. I spend more than one thousand dollars for sure, most likely more than two thousands.
P.S. I don’t expect many comments because I’m making post mainly for myself (In order not to forget important thoughts for the pres). But it is interesting that nobody asks any questions or disproves my theses. Nobody cares or everybody agrees? ![]()
We are discussing now how to build investment grade portfolios and books
1. Portfolio construction.
Since we defined our alpha signals (factors/themes) and made appropriate ranking system we begin to build portfolio positions from chosen stock universe. To do so on each rebalance date we launch portfolio MVO (mean-variance optmization) process based on volatility, pairwise correlation and return estimates of each stock. We set appropriate limits for weight variables and other parameters based on constraints (max-min stocks weights based on liquidity, short available or not, desirable level of volatility, borrowing costs which affect return estimates, available leverage and it’s cost, limit number of stocks in portfolio, etc. All parameters influence on target function).
The target function is not only sharpe ratio. I propose to use the following: (sharpe + sortino)/2 – kst._dev, where kstdev is a potential drawdown expressed in terms of volatility. Because we afraid mostly downside volatility it is not correct to use only sharpe. But using only sortino is not good either (volatility sign reversion reason).
How to get inputs for the model.
A. Volatility – most simple way to use previous period volatility (several months or year).
B. Pairwise correlation – the same way.
C. Return estimates – based on our alpha signal model – ranking system (ranking value itself plus maybe historical correlation of rank to future realized return), market timing model (and factor timing model for books)
When you get the result you normalize it to get required level of volatility using leverage/deleverage for further composition to a book (leverage is not constant). The system will show weights for each stock in your universe to get maximum possible result in future (based on your assumptions and estimates of course). And it is not equal at all as we have now. Because of close stock pairwise correlation even across different sectors or themes as P123 suggests the weights will be close to naive risk parity weights with return estimates tilt.
The simple prototype of such optimization model (at least simple risk parity) should be built into P123.
2. Book construction.
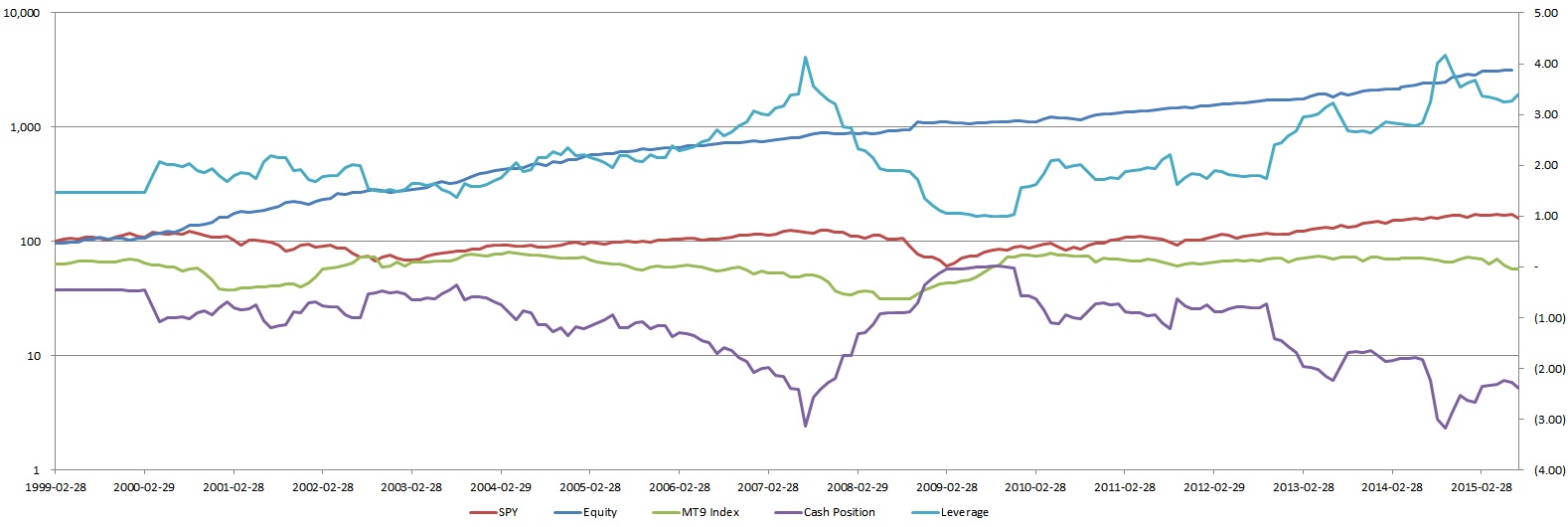
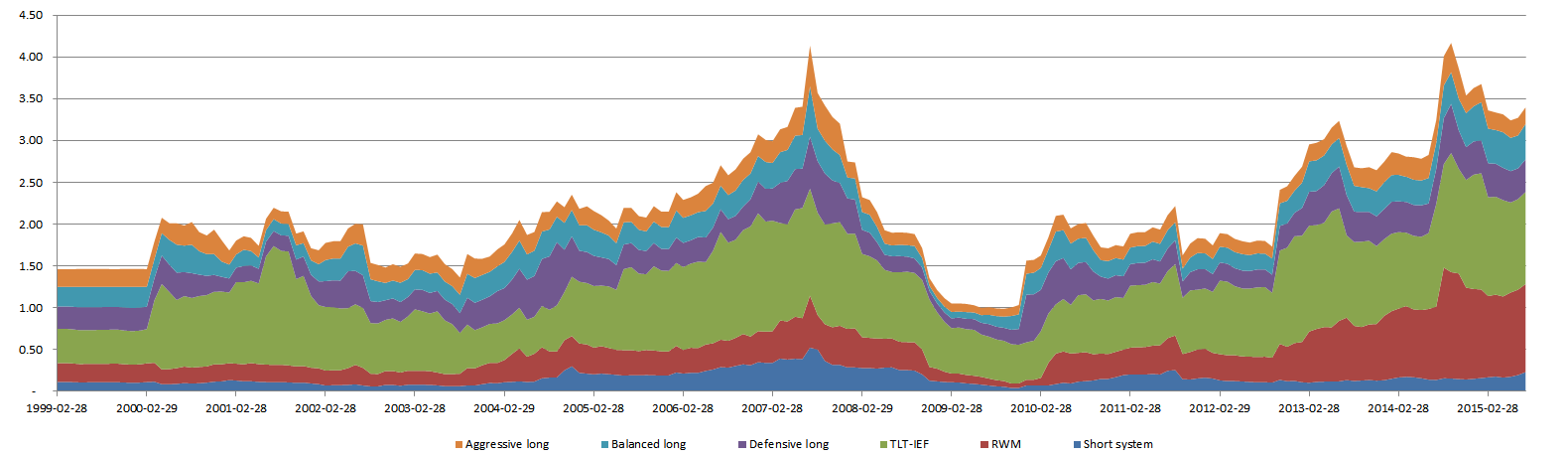
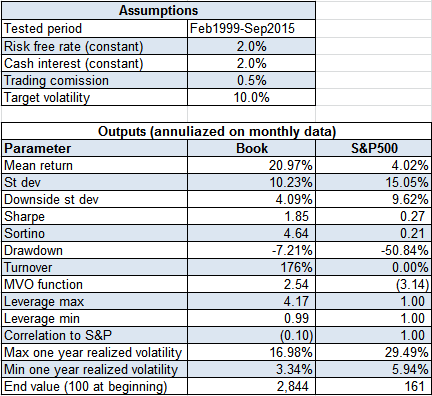
It is based on the same dynamic risk parity approach (MVO). The difference here is underlying assets. It is not stocks but systems itself comprising different asset classes from almost zero correlated to equity (exotic beta strategies for example) to even negatively correlated – short systems for stocks. It also has more stable volatility, pairwise and return parameters. Market timing and factor timing models are working here as future return estimates for stocks systems and fixed income. Since you defined your systems as separate assets in a book on each rebalance your launch the same MVO process. The result here can be far away from naïve risk parity approach because of low pairwise correlation. And the leverage can be huge (in my example it reaches 4.2) to get required target volatility. Most prominent funds and quantitive firms work in this paradigm. We have competitive advantage – proprietary alpha signals, team cost effectiveness, small size and less constraints.
Here is my simple dynamic book example comprising 6 systems: short, RWM, TLT-IEF, defensive large, balanced, aggressive small and previously mentioned market timing model as return estimator. All inputs for model are point in time data to avoid look ahead hindsight bias, therefore for the first year of test I used constant weights (to get volatility statistics). Drawdown is underestimated because of monthly data, on daily basis it would be 2-3% percent higher. Realized average volatility is close to targeted 10% with 3.33%-17.12% min-max range. Leverage reaches 4.17 when volatility gets its minimum. On negative cash (borrowed money) I use risk free interest rate – 2% (borrowing cost for shorting stocks embedded into short system itself). Transaction costs – 0.5% for each system.
As can be seen from the second graph fixed income comprises major part of assets at anytime (therefore institutional investors have so big fixed income exposure in their portfolios). Also the the average leverage is quite high - 2.1 (also in line with hedge funds strategies - minimize st dev of portfolio and then take high leverage to get desirable characteristics, the average leverage for them is close to two also). One important aspect - all realized return is alpha because book correlation to S&P is close to zero even negative - 0.1
Superior book result in comparison to other book construction methods expressed not in usual performance statistics as st dev and sharpe ratio but in downside st dev, sortino ratio and as a result in very low drawdown.
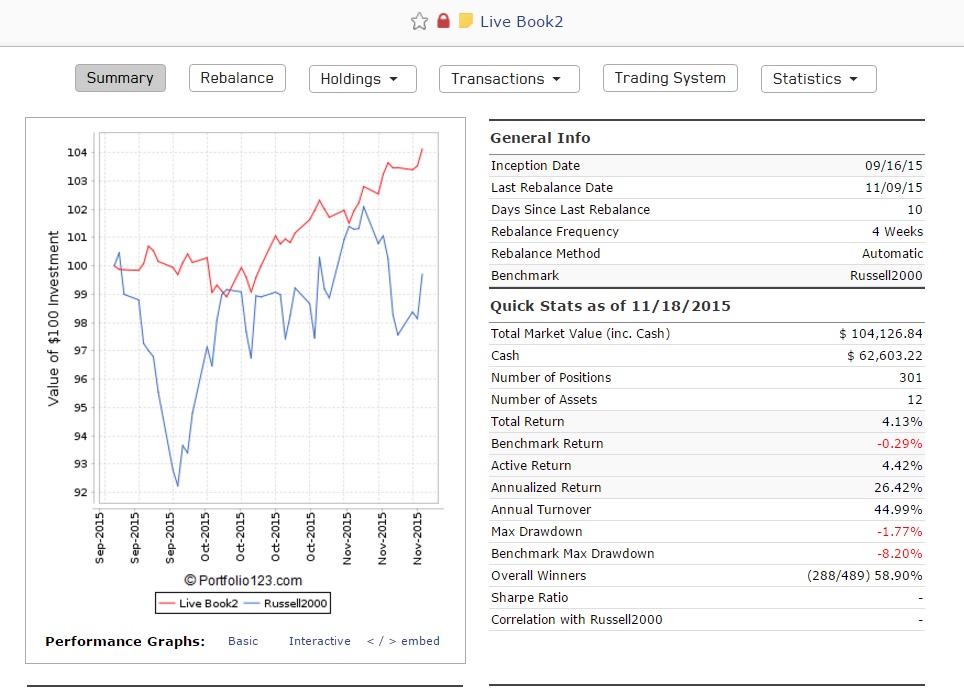
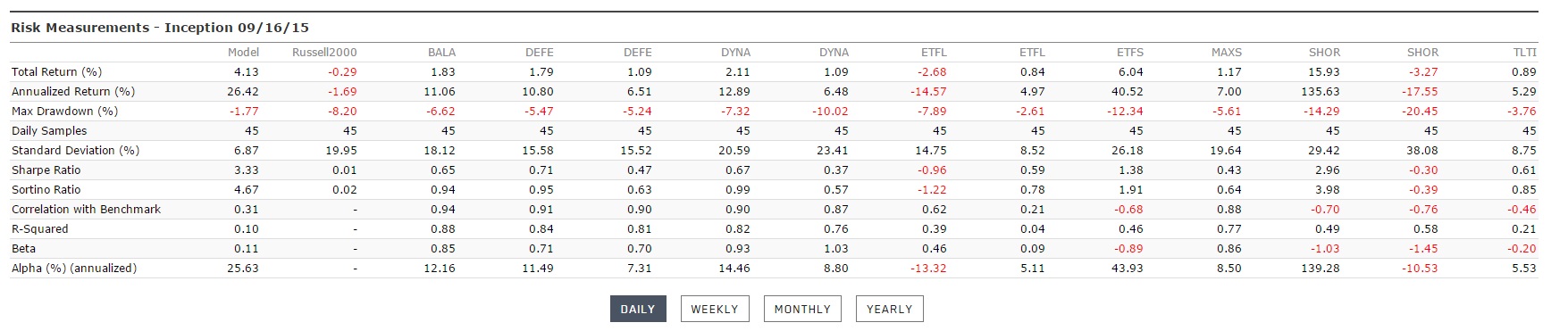
The last two pictures show live book statistics launched two months ago based on risk parity approach (simple approximation cause I don’t have access for required systems for exact calculations).
As can be seen realized volatility is only 6.87%. So we can leverage that book to get required 10%. It needs approximately 1.5 leverage and total return in that case would be 4*1.5 = 6% just for two months = 36% annual return with 10% deviation. But more importantly it is overall st dev, downside st dev would be two times lower at 5%. Therefore realized and prospective drawdown number is very low.
Good morning, P123 guys.
Here is my overview paper about modern asset management and factor investing specificaly.
I would greatly appreciate your comments and feedback.
Best wishes, Yury Polyakov.