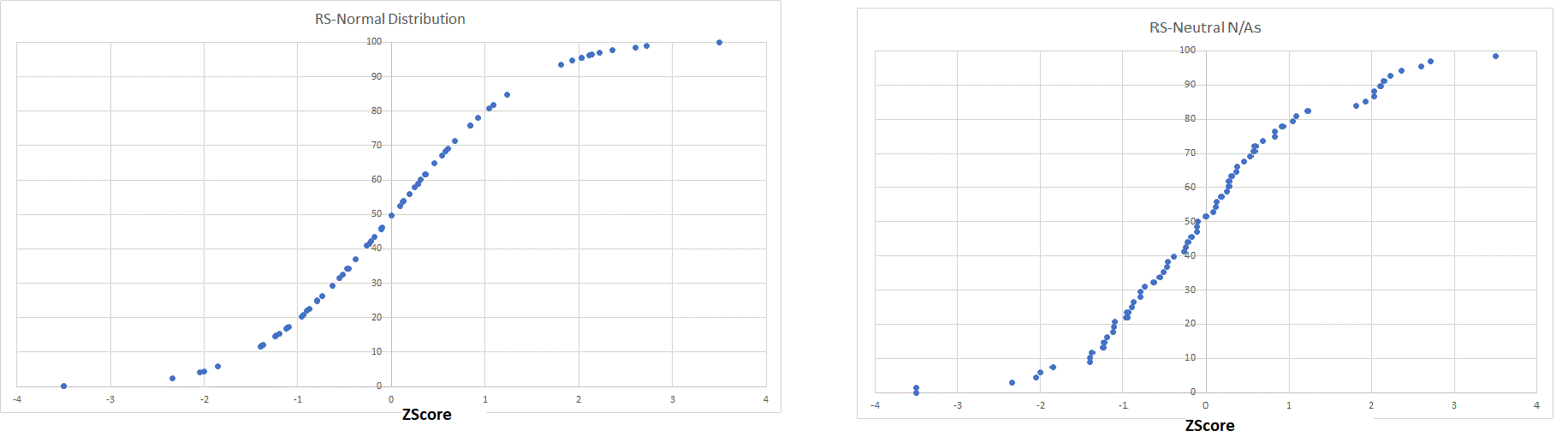
Marco / P123 - I still don’t understand what the Normal Distribution ranking method is actually doing. I have extracted the ranks for ~68 stocks with the factor SalesGr%TTM and compared it against a screener version of the ZScore of the same factor with default settings for ZScore. When I do a scatter plot, I get what is shown below.
If the Normal Distribution RS were simply a ZScore that has been rescaled to be within the range of 0 to 100 then I would expect that the scatter plot would be a straight line. But it is in fact a very nice curve. With the same thing using a N/A Neutral RS then I get a slightly frazzled version.
So what I am really looking at here with the Normal Distribution ranking method? It kind of looks like perhaps a ZScore has been applied then the results are ranking using the normal ranking method. Either that or the results are being mapped to a normal distribution curve.
I’m not complaining, I like the smooth distribution. It is important to know the processing algorithm if there is any hope of reconstruction the original.
Steve, it does seem to do things differently than just the ZScore default. It’s very old stuff and it was not advanced any further to work well in a ranking system. I’ll have to look at the code again.
BTW, We’re going to allow the use of ZScore & FRank in the APIs so you can download those directly . I think with this capability you no longer need to use a ranking system to generate the data you need. So for example you will be able to download FRank(“SalesTTM”), but to download the actual SalesTTM via the API you’d need a license. This capability will be added to the data API endpoint (which lets you specify multiple periods). By next week I think
Marco - I’m pretty sure that the old code is probably just doing a normal distribution mapping function. That is why it is called “Normal Distribution method” not “ZScore method”. I know, I’m a smart-ass
I look forward to the updates. With the new functionality, will you be able to call a custom formula? Some of my parameters can be complex.
** EDIT ** I would like to point out here that the normal distribution function appears to be a superior approach than a simple ZScore for the additional functionality that you are providing. I should clarify that it is superior only if you provide the algo so it can be reverse engineered by the application outside P123. It is superior because it conditions the data so that it is equally spread across the range 0 - 100 which is excellent for neural nets. It saves the external application from having to do that pre-processing.
Are you looking for the equivalent of =normsinv() in Excel?
You mention TensorFlow. While not necessary for XGBoost, I think, I have used =normsinv(rank +0.005)/100) in Excel to get a normal distribution shape for the data. BTW, the +0.005 used in this equation prevents a zero rank giving an NA.
So for example a rank of 99.95 will give 3.32 with this equation in Excel. Or a Z-score of 3.32 in a normal cumulative distribution function is greater than 99.95% of the data points in the distribution.
At least in theory this standardization (as opposed to normalization) could be helpful in TensorFlow. Especially if one uses BatchNormalization.
I fully understand that you want to load data into GoogleDrive and make any manipulations in Colab using Python. And not mess with =normsinv() in Excel.
But maybe this will help Marco understand what you are looking for—IF I understand correctly what you are trying to do.
Marco, having the option of a Z-score (and not just rank) is an excellent idea too, I think.
Jim - that could be it. I think the old code for the Normal Distribution method was probably doing that.
Tensorflow may have an implementation but not all neural net software has the same functionality. Biocomp has some weird pre-preprocessing functions such as arc-tan etc. So from a portability perspective it is best to control the I/O from the outside and not depend on some weed-smoking silicon valley type that wants to call inputs features and targets labels.