At this moment, nothing is likely to be lost. But looking ahead, it is the SP500 universe that may go away to be replaced by a P123 approximation, as we now do for Prussell1000 fro Russell 1000, etc. ( No, that P at the start of the name is not a typo; its there to differentiate between our approximation and the real thing.)
I guess I’m having trouble understanding, but I can go to the SPY ETF website and pull up the holdings.
https://www.ishares.com/us/products/239726/ishares-core-sp-500-etf
Right now it’s showing 509 holdings, but it seems to be a pretty good SP500 tracker. I don’t understand the behind-the-scenes programming required to grab data, but a periodic pull of this data from one of the major index funds that track the SP500 other other index would be fine for my purposes. I’d really hate to see P123 held over a barrel, especially if it’s 20% of data fees, over something like this.
I agree with Chipper about the ‘cleanliness’ of the SP1500 universe versus just using PR3000, for instance. I feel more confident in using a base universe that has been pre-scrubbed than one that is just based upon marketcap, for instance. I know the S&P is doing this in effect for me.
Maybe this could be an area where P123 and its community comes up with some criteria that has added value.
For instance, I would like to see a base universe that use has something like Rating(“Quality”)>20 which I can use for operating, non-financial companies.
Or a similar one for banks (which I know has completely different criteria than an operating company).
Just an idea…
iShares Core S&P 500 ETF (IVV)
At iShares one can download historic monthly constituent data of their ETFs back to Sep-28-2012. So it is easy enough to construct a point-in-time universe from this information for the S&P 500.
We did this for USMV and are able to run a PIT strategy from 1/1/2013 which periodically selects 9 stocks from its holdings. The strategy has a turnover of only 58% and a CAGR of 24%, outperforming USMV which only produced 14%.
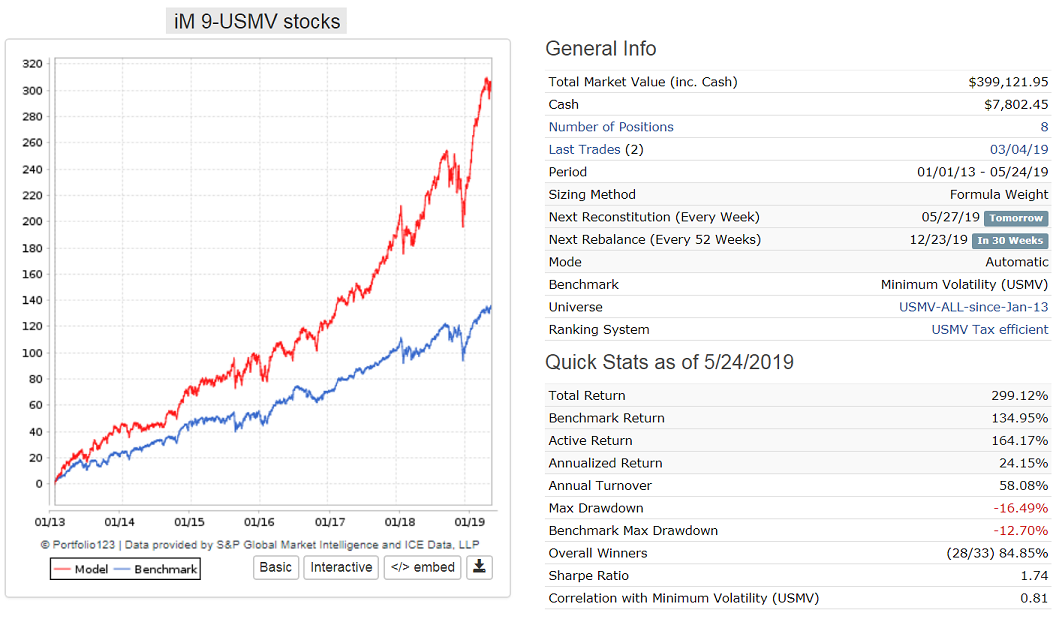
Georg, how are you importing the data into the simulation?
Walter,
We made inlists of the holdings every 3 months. Then you make a universe that holds all the inlists and future inlist which are empty at this time.
You start the sim on a specific date and in the buy rules use portbars to call up the specific inlist applicable to the time period of that inlist. That gives you a PIT simulation as it will only select stocks from the currently active inlist. Going forward you need to fill the predefined inlists every three months and also run a total on the universe so it updates.
The only inconsistency is that your universe gets bigger all the time because it will hold all the stocks dropped from USMV over time. But USMV has a turnover of only 27% so that’s not a big problem. If you are using RANKPOS in the sell rules you may want to change the position number every few years. For my strategy the universe now holds 292 stocks, while the most recent list holds 214 stocks. Of course you can also remove the redundant stocks from the universe as you update every 3 months.
Thanks Georg! I didn’t consider using portbars. Nice!
No issues from my end on using the SPY constituents.
Yuval, Marco and Marc, thanks a lot for the transparency and for asking our opinions. Much appreciated.
The proposed proxy screen reduces by 3 percentage points the annualized return and increases the drawdown by 7pp of my oldest screen in use on its out-of-sample-period (7 years, with a few forgotten revisions on the way so not 100% OOS). But, I’m not sure the difference between 23% and 26% CAGR on a 7-year period is really significant about the quality of your proxy or of my screen, or of any of them. I can live with this uncertainty.
- Maybe the proxy screen can be improved.
- No issue for me if you decide to use constituents of SPY or IVV to make a S&P 500 universe as PIT as reasonably possible.
- Anyway, I wouldn’t pay S&P for that. Even if it’s perfectly legal it looks like racketeering.
Additional clarifications.
What’s at stake here is the SP 500, 400, 600 and 1500 index universes and their historical data. They are currently included with our S&P data agreement and go back to at least 1999. The constituent data will disappear around August from our data service. Their index data will be marketed separately and they are asking around 20% of our current costs for it. Of course there are a lot more indexes than we need, but they don’t care that we do not use it.
If we do not accept their terms …
- We will not try to re-create them using rules.
- We will have a backup using ETF constituents data providers. Since the SP 500,400,600,1500 all have ETFs we should not loose any functionality. The only loss will be historical data that goes back to 2007 for the SP500 (not sure about the others yet) and maybe a little bit of “precision” as far as when stocks enter/exit the index.
This one is $240/mo http://masterdatareports.com/Content/Subscribe.htm
That sounds good to me and we will not have to raise prices! It will also give us something we do not have: ETF constituent data for all US etfs which we may want to use for other ideas.
Thanks
That would be amazing! Bravo!
Marco,
Your approach is good for me. Thank you.
Jerome
I really like the idea of having ETF constituents to model with as our base universe. That will be a very powerful tool going forward. Very powerful!
Marco, this is excellent. We can then all produce shadow ETFs with rank-selected stocks that outperform the actual ETFs. For DMs of shadow ETFs the current 10-year min backtest period will have to be shortened. This should be a good source of new revenue for all of us.
I just looked at their SPY constituent list and it has 506 entries. Five of those are due to multiple share classes (DISCA/DISCK, GOOG/GOOGL, FOXA/FOX, NWSA/NWS and UA/UAA). How will P123 handle that?
Also, I think this data should be accepted on a probationary basis for the first year. Perhaps this should include a restriction on its use in DMs.
Walter
We only use primary shares, so automatically the secondary shares would be excluded.
Not sure what you mean in your next sentence.
Also heavy restrictions on DMs is no longer needed since only out of sample performance is shown
THanks
I’m concerned about the quality of a new data source. What’s going to happen if by next year P123 decides that something’s wrong with the constituent lists (e.g. missing data, incomplete data, missing ETFs, etc). If user’s have already built the data into their models, pulling the plug may be painful for everyone. If this data is going to used in DMs, it better be available for years.
Walter
Data looks quite good. Comes from Reuters it seems. The main decision is whether to source SP universes from ETFs and save around 10X. We can always switch provider for the ETF constituents.
Thanks Marco, ETF constituents as universes would be really great!
What I’m afraid of is, next step in S&P pricing policy might be doing the same for GICS data. Is there a backup plan if it happens? (ETFs holdings would fix it only at sector level for large and mid caps, and on a limited time frame)
GICS is already a separate contract as well as pricing data from ICE Data.