It's only available in the screener right now. We are still tweaking its RAG data and instructions. Tool wise it's very limited right now, just a proof of concept. It only knows your name, and can search through P123 screens. It's strengths are definitely explaining rules. It got a lot better yesterday writing rules because we made its instructions much bigger to make it stop using non-P123 syntax. We're still exploring alternative in this area.
We are also working on
Adding RAG data including examples, FAQs, site how-tos
Adding forum content (last 5y for ex)
Adding agentic tools
Improving UI/UX
Let us know what you think, specially what tools you'd like it to have and mistakes it makes. Also interested in hearing in how we can all collaboratively make it smarter.
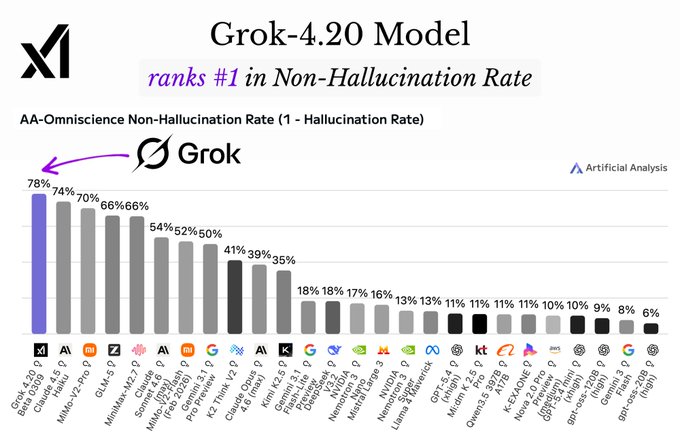
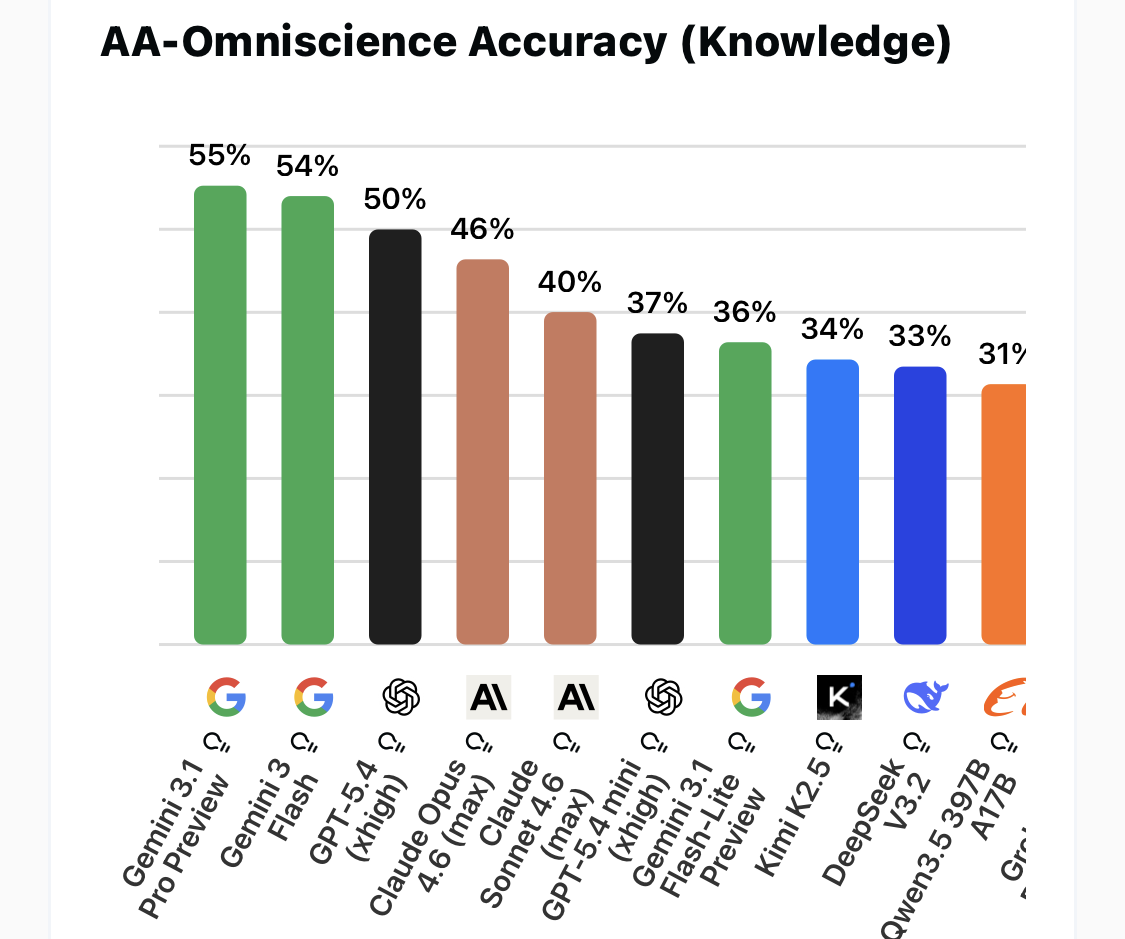
Will try it out! One way to reduce hallucinations and force it to use the right syntax would be having a mixture of differently trained models and having the final arbitrator model go with the consensus answer, discarding any outlier answer. Currently LLM are bad at not hallucinating when they don't know the answer but this greatly reduces that negative aspect. Some (non) hallucination metrics:
That previous post is specifically what they do when they don’t know -which is a niche read. The ratings change over time but rather than it telling me to go with a specific model it tells me to not go with a single/unique model! Even 22% is too much for me. Of course it does not mean 22% hallucinations since its just when the model somehow does not know the answers or makes assumptions. Models know more and more these days and by having them check each other it can get quite accurate.