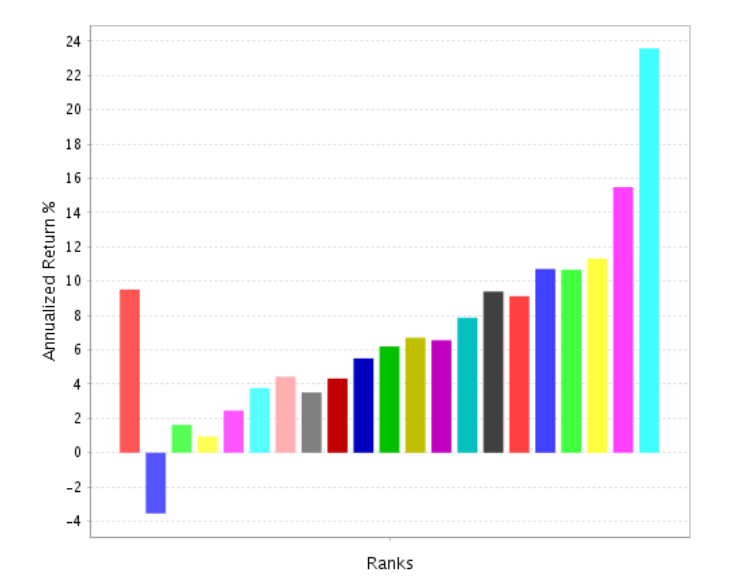
Just a general extension of this. It NEVER works for me to weight by the historical returns no matter what I am doing. And this would be just another example that proves this rule to me.
AND this is in-sample. I think it gets much worse out-of-sample. Done out-of-sample it would be a clear example of fitting to noise and overfitting as there is guaranteed to be some noise in the returns. Pure and simple. Overfitting to some extent is guaranteed with raw returns and there are know solutions.
There is information in the returns that can be use. It is just not necessarily a good idea to overfit that information.
An example of a solution is Ridge Regression that uses the information but shrinks it (Lasso regression might discard some of the data). My experience and it is growing every time I look at this is shrinkage does work and information like this can be used while the raw data does worse than nothing.
There are a lot of good shrinkage methods with ridge regression being just one of them. Empirical Bayes is another.
Empirical Bayes sounds complex. But here is a P123 resource that addresses some (but not all) of the reason it is used (e.g., regression-toward-the-mean) with the first link being to a paper that uses Empirical Bayes https://blog.portfolio123.com/thoughts-on-is-there-a-replication-crisis-in-finance/
And here is a link to the original paper if you just want to go there: Is There a Replication Crisis in Finance?
Here is a quick a dirty way to shrink things that seems to work with not a lot of justification and certainly nothing like a mathematical proof. But shrinking things to the lower confidence bound (i.e., the the lower side of your usual 95%confidence intervals) gets you pretty close. And JASP and other programs can calculate that number easily enough (menu driven and free). And if you squint, think about variance etc you can see how it sort of looks like a Bayesian approach as the confidence interval will widen (with more shrinkage) when there is less certainty (more variance or less data).
So, IMHO, Yuval has 2 good points. First, I suspect the sector return information can be used!!! And I give him credit for the “The Factor Zoo….” post which actually has a lot of good points. I think almost all of those points are related, but if anyone wants to say things like regression-toward-the-mean is something different, I would not mind how one decides to outline the general topic of raw returns out-of-sample. Or what particular solutions they may use if they too find some problems they want to address.
BTW, I do not mean to imply that once you shrink things you will get a dramatic improvement. In my experience you will not. But you are actually guaranteed to be less overfit out-of-sample and you will get some improvement in my experience.
Jim