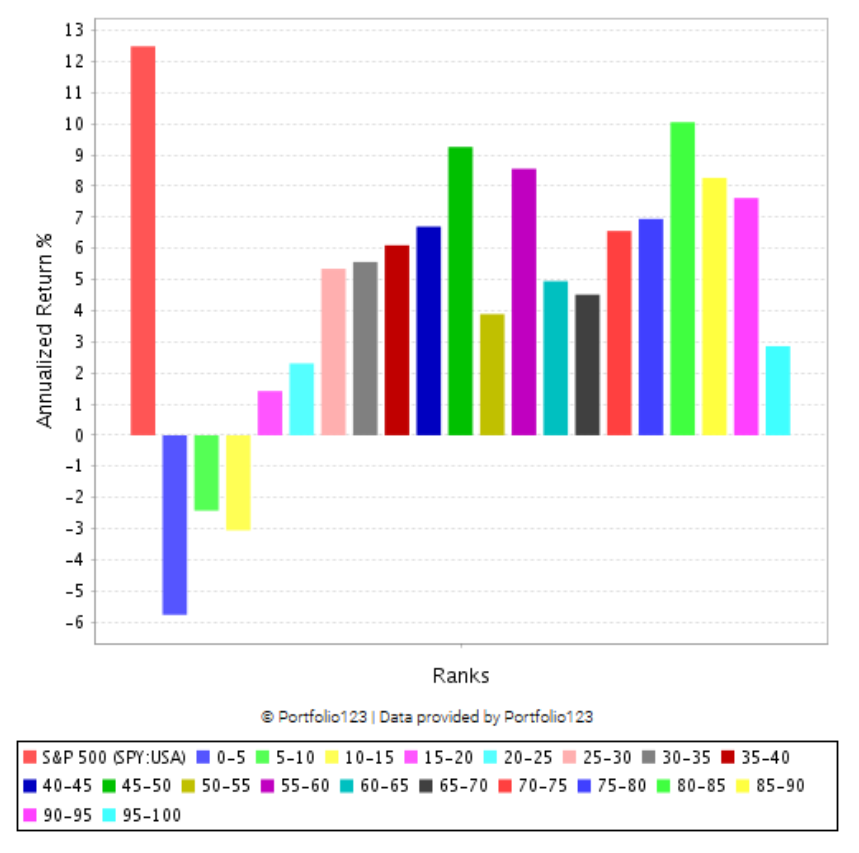
I am curious what other folks think about looking at factor rank performance using different metrics than just returns and fixed slippage. Such as variable slippage and alpha.
I recently downloaded ranking data for use with ML algorithms and I wanted to check the individual factor performance to make sure I was not feeding the ML model junk. Since I am using alpha - slippage as my training target for ML I wanted to see how the factor ranks performed with this target. The results were surprising to me in that slippage inverted a number of my factors. That being said I am applying slippage every week which is an exaggeration as I am not turning over the portfolio every week. Do other folks have experience with looking at factor performance with slippage or alpha? If so do you think the effects I am seeing are because I am applying too much slippage?
Edit: this is all for a universe with the following rules:
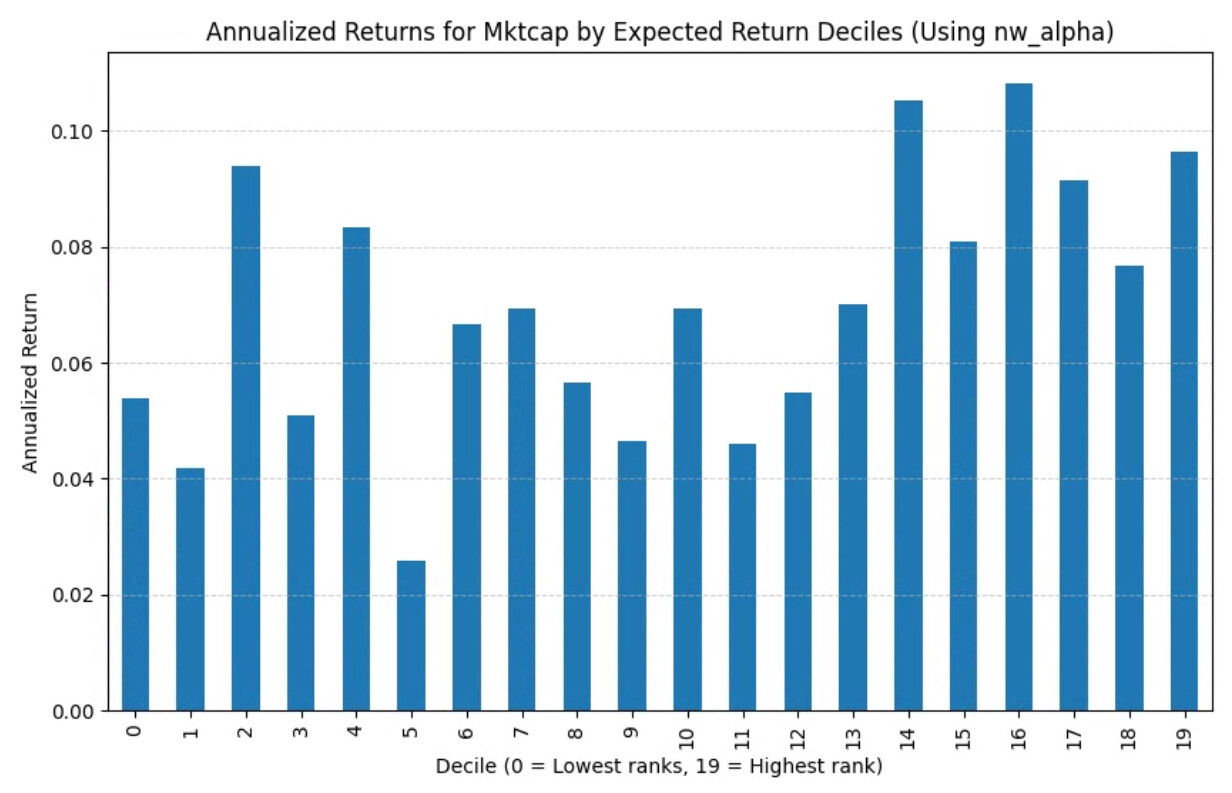
For example if you look at Market Cap with just annualized returns and say 20 buckets the relationship looks something like this for a universe similar to the Prussel 2000: please ignore the chart title saying using NW_alpha. I forgot to update my code, it is using next week gains.
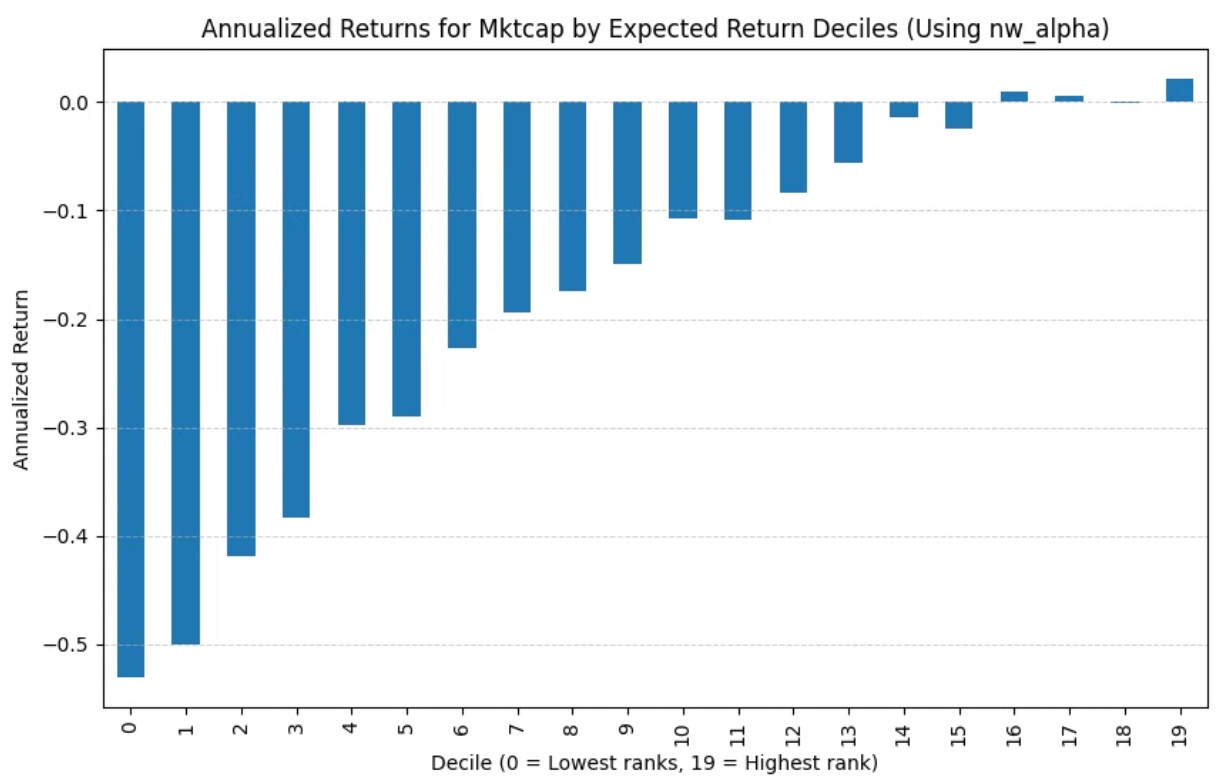
However, if I add in volume based slippage (see the transaction costs blog by Yuval for how I calculated the slippage) I get a much stronger trend:
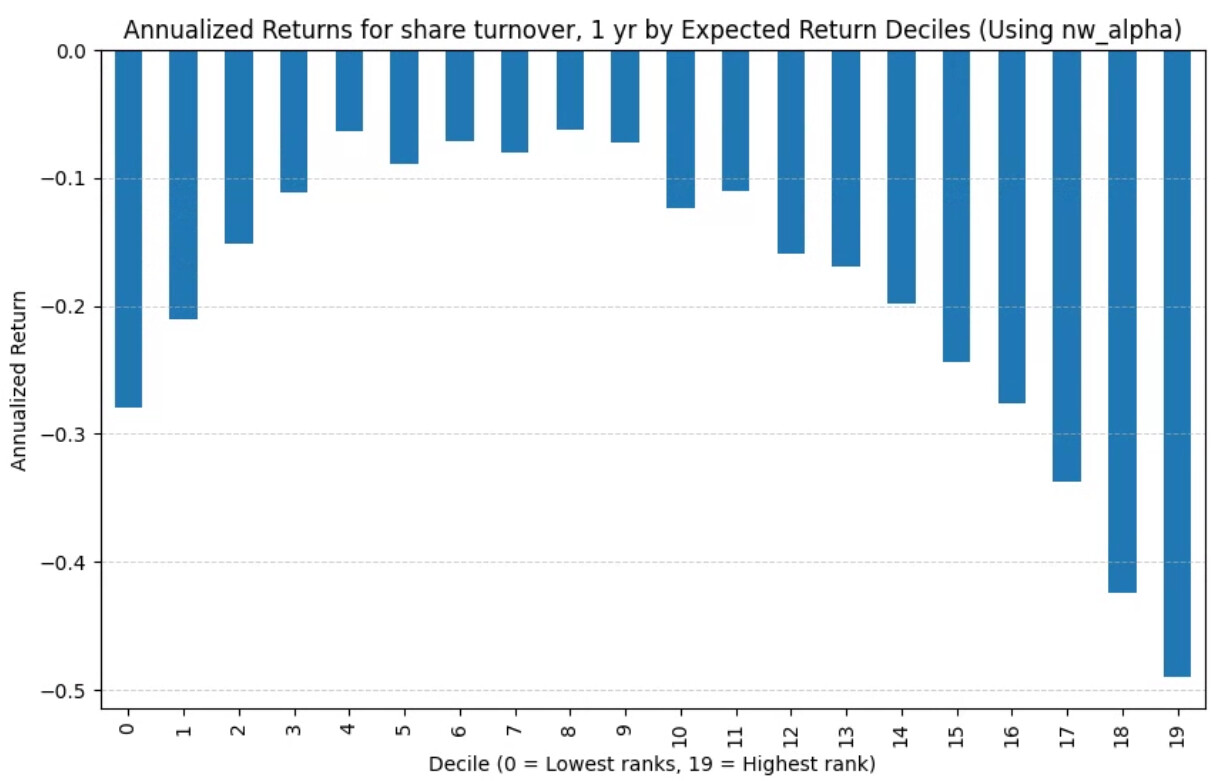
A more significant change is 1 year share turnover: using next week gains without slippage
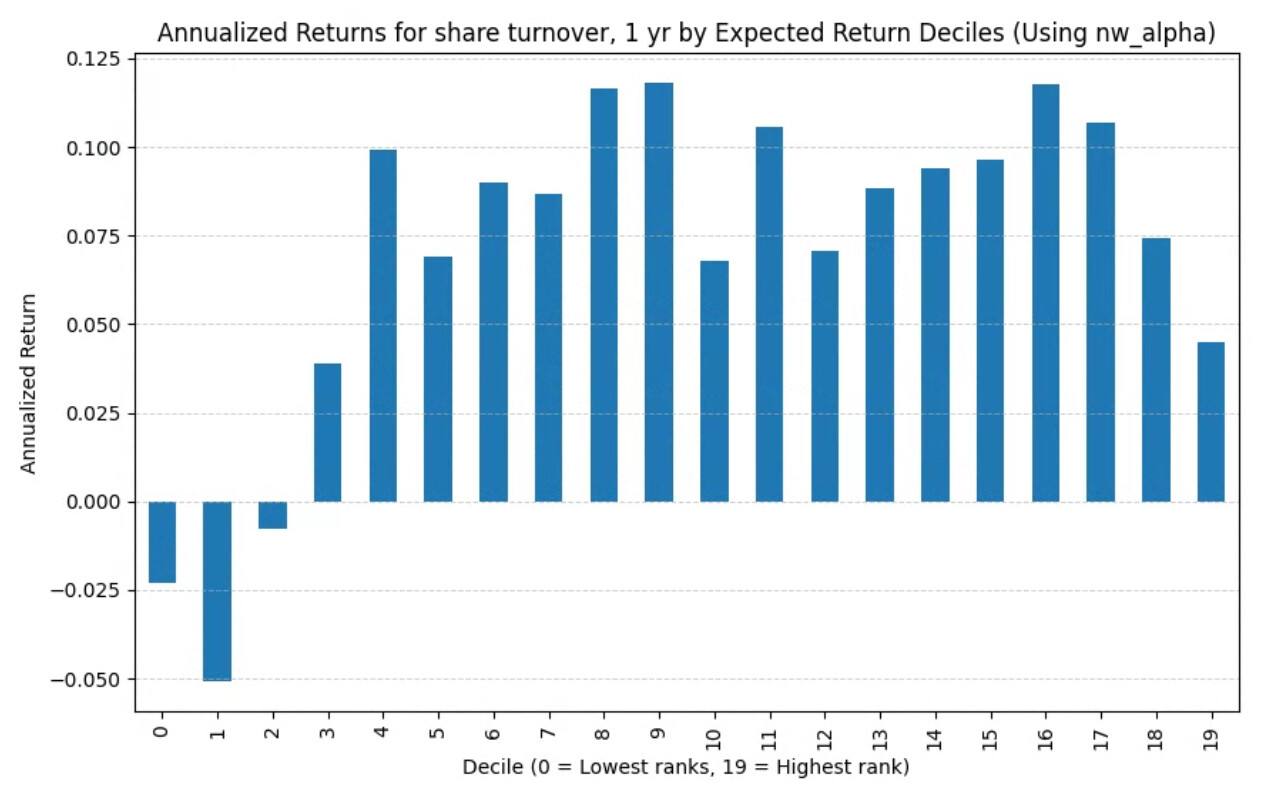
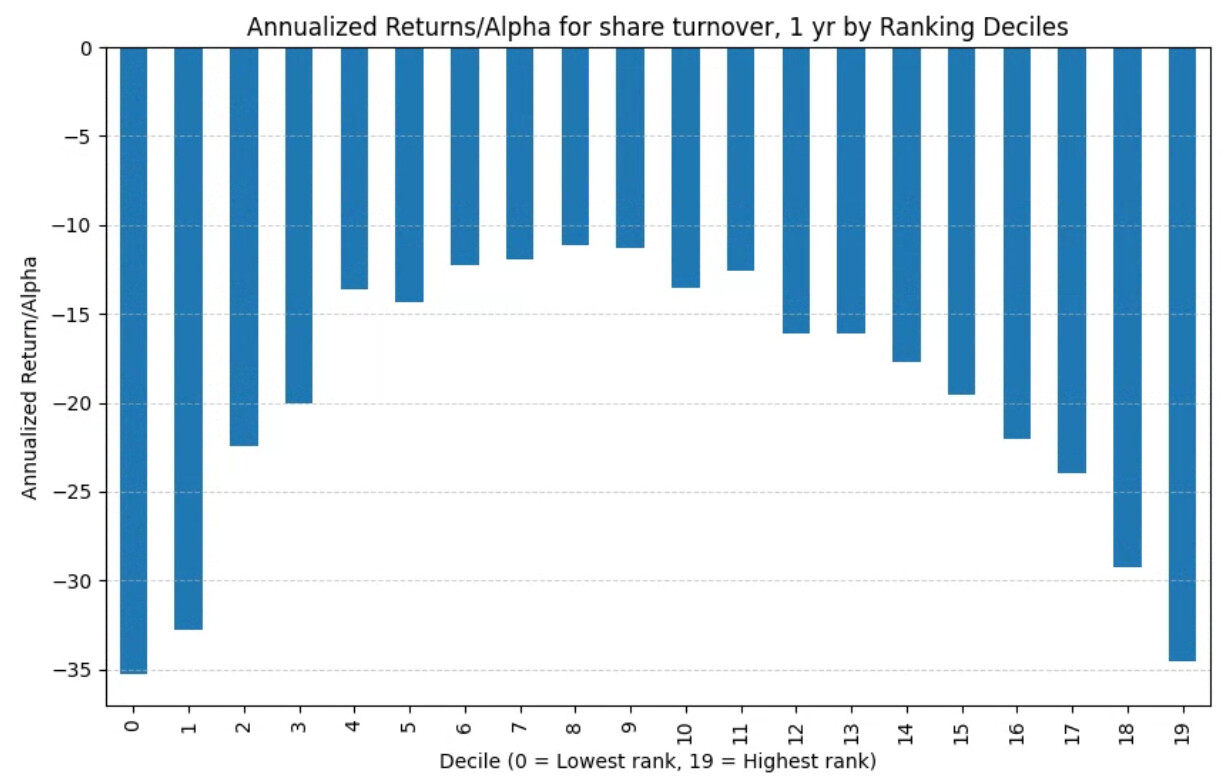
Using alpha without slippage (sorry my chart titles are wrong): note the trend is almost gone
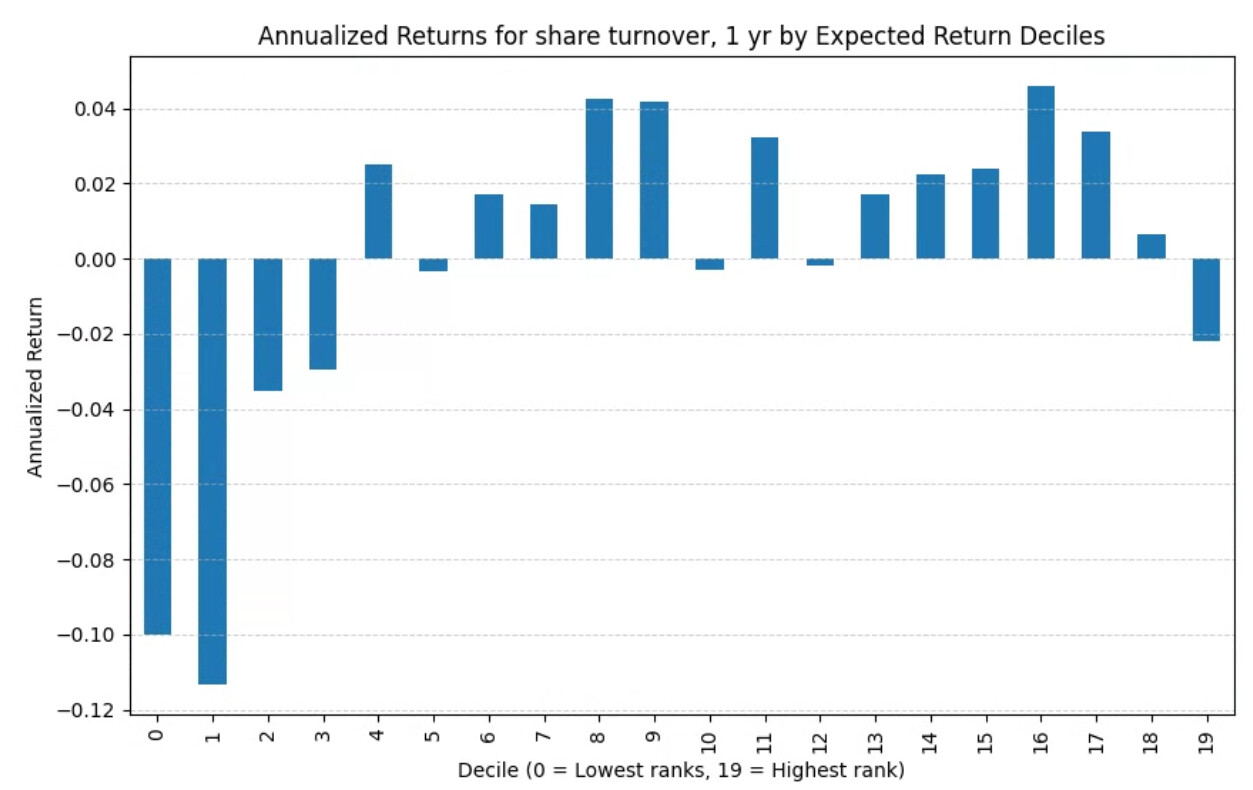
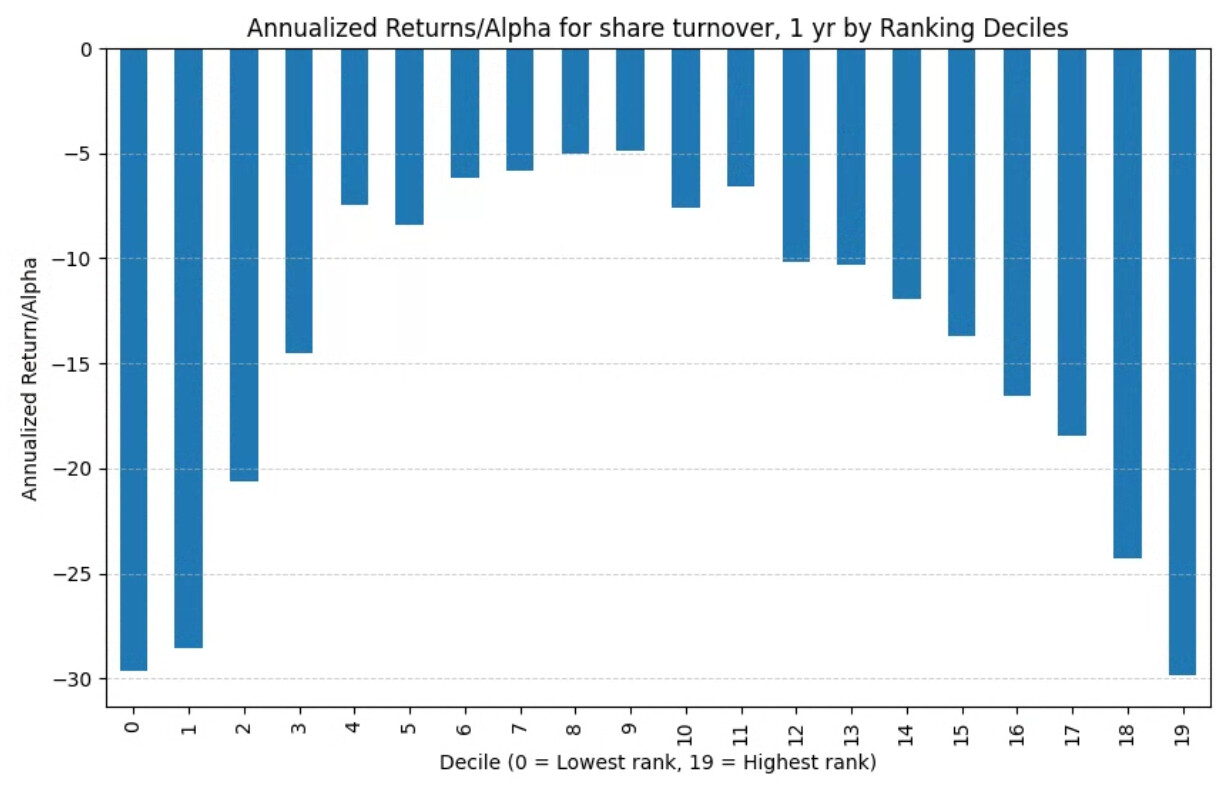
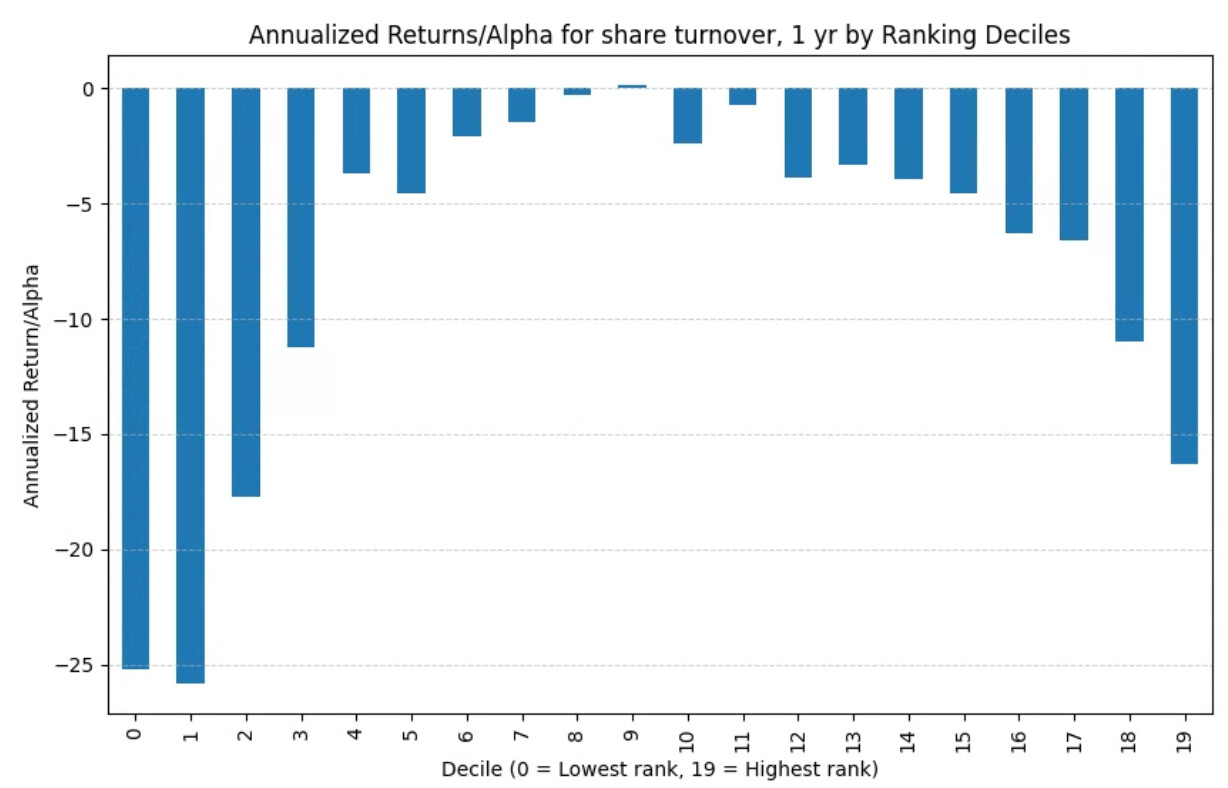
With slippage (next week gains, but alpha looks similar): the trend reverses for the most part