For a model that performs well, $100/month is cheap. However, subscribers will like to see that as out-of-sample performance. Too many people are still hawking great simulated results that don’t seem to pan out in live performance. If P123 is able to attract more users, future subscriber demand may be there for that price point.
In addition, it costs nothing extra to submit a DM model and you’re under no obligation to open it after the incubation period is over. It’s a no-risk venture for you.
you should by all means go ahead and launch some designer models. For low liquidity stocks just use between 10-20 stock holding and low turnover (=< 5x). Most traders in small- and microcaps get burned when trading on a Monday open. If the turnover is low, one can easily wait a day or two before doing the trade.
Regarding pricing I have a different point of view: consider that one designer model should only be one of many strategies. I have 5 strategies combined in a book, others even more. Imagine you have to pay 100$ for each single strategy, then your costs will soon eat up all potential performance.
None of my models are more than 49$. I have few subscribers but I think they get a fair return for what they pay.
I am relatively new to P123, but have used these types of systems since '98. I still find myself reminiscing about Microsoft’s MSN MoneyCentral screening tools; that was years ahead of the curve. While it thrived in the dot.com/bomb era it was well supported by Microsoft with contributors like Jon Markman, Mary Rowlands, Jim Jubak, etc… When Microsoft killed it I periodically went searching for something similar (Zacks Research Wizard, Vector Vest, finviz, etc.) but nothing came close until I stumbled across this site last year. I can honestly say I have been kicking myself for not finding P123 sooner…
Note: a google search of “stock screener” returns P123 in the middle of the 9th page (for me). That’s far too far down for anyone searching for a “stock screener”
It is a steep learning curve though. I have spent a lot of time trying to digest years of posts and put together a system that fits my own risk profile. As have many others, I have moved slowly away from large cap stocks to micro/small caps as the models I am running prove themselves.
The designer/alpha models though have confused me. I ask myself why would anyone sell a system that significantly outperforms the market? I wouldn’t. I find the “black box” approach is also unappealing. If it doesn’t work, then there is no way know why. I agree with Yuval. It makes no sense to sell a system such as that for $40/month, or even $100/month, especially if doing so increases slippage…
I haven’t figured out who are the target buyers for designer models.
Yuval if you can get those type of returns keep it to yourself. Here are my observations:
The vast majority of models under perform just like the mutual fund industry the numbers are the same.
The top ports the designers have models that under perform and some have gone to the graveyard so how do we evaluate the designer and model can you seperate them?
The top models are not full everyone knows how hard it is to trade everyday. If the models where so easy everyone would subscribe.
What most users want is out of sample performance more is better with minimum effort no one talks about how hard it is to trade a model that underperforms for 2 years and you work it everyday. I tried and it’s hard.
In the mean time I will keep indexing with leverage I am very happy with that choice I have been in QLD since 2009 with market timing and it is my best performing pick every year with very little effort. P123 makes it really easy for me to combine that pick in a book with other models. Until someone proves me wrong I will stick with QLD in a book.
P123 is the best and I could not be successful without it.
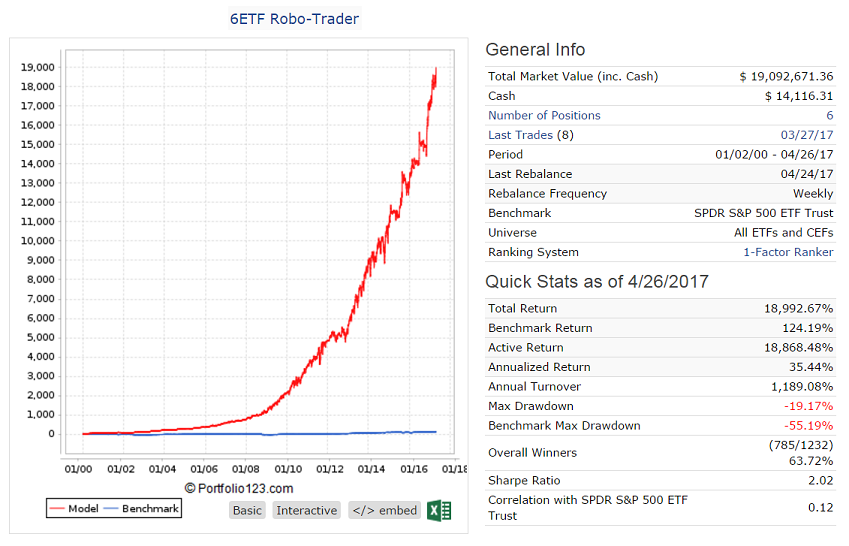
In anticipation of the proposed revamp of P123 I have launched a new DM. It holds 6 ETFs from a possible list of 29 and shows a simulated return of 35% with a max D/D 0f -19%. Annual turnover is about 12x.
You can place this model in a book to see the performance and how it will combine with other models.
We shall see how it performs over the next few months. https://www.portfolio123.com/app/r2g/summary?id=1486029
So what about models where additional slippage isn’t a factor? Large cap models seem to still do well even with many subscribers. The real rub is that P123 isn’t well known. With more potential subscribers, more designers would spend the time required to build reasonable trading models. I would love to add more large cap models to my book just to avoid over-optimization via model averaging.
The way I see it, some people don’t have the time or inclination to learn the P123 system or build trading models. For them, Designer Models are a viable solution. Couple a trading book with an IB account and trading couldn’t be easier. However, for those that want, or do understand the theory and practice of investing, a black-box solution would probably be unappealing.
I think P123 should offer at its Investor level what https://allocatesmartly.com has - with source code - plus the current DM offerings.
Walter why would I want a large cap model when I can use QLD or SSO over the last 10 years with basic market timing and get 20-30 percent?
If You index you are beating 80% of mutual funds with minimal effort. I don’t want to sound negative but unless you have 10 years of o/s behind you the safe bet is indexing. Until P123 models show me the 10 years of history I am indexing. How do designers show they are better than index only time will tell. Can anyone convince me why indexing is not the safe bet?
MV, I’m not asking anyone to give up indexing. Choice is good. You mentioned earlier that you combine QLD with other models within a book. Is that a current strategy?
I do need to examine index ETFs with market timing. But MT is an requirement with leveraged ETFs unless one is willing to accept very large drawdowns. So now the question is how robust is the MT logic? Does it also need 10 years of o/s data to be considered reliable?
I’m of two minds now. Some of you have been very encouraging, others very discouraging.
a) I could just keep making boatloads of money investing in microcaps and not think about this anymore.
b) I could offer a dozen different designer models at $50 or $100 each and hope that makes the work worthwhile. In addition it would be fun. I would love to spend a few weeks working on a model that invests only in financials, or REITs, or industrials and materials–I’ve been playing with models for all three. I’d love to try my hand at an SP1500 model. But from what a number of people here are saying, offering a designer model may be like crying in the wilderness–nobody’s paying any attention to them. Nobody wants to go to the trouble of investing in microcaps, but large-cap models are unlikely to offer huge returns. And MV makes a very good point about QLD.
At any rate, one thing I’ve learned from this really illuminating conversation is not to include in any of my models any stock with an average daily dollar volume of less than $500,000. Those are my bread-and-butter stocks, and I’m not going to risk having some wealthy investor shove me out of them.
So here’s my last question (I hope). Are new subscribers to designer models pouring in these days or is the designer model business drying up? There may be alternative marketplaces for the kind of stock-picking expertise I hope I have been developing (e.g. at Seeking Alpha).
I think you have come to an interesting crossroads. On the microcap front, I think those are a tough sell for most people. The real world application isn’t great unless you are a professional day trader. Timing is a big part of the models that I have created. Way too much is what I call the Monday morning pop. I have seen about 50% of the return on thinly traded microcaps come in 3 hrs a week. I can cherry pick variables and generate 50-100% annual returns. That sounds great, but in practice I could not do it. Trying to sell 10 nanocaps and then jam 25k each into 10 nano caps at 9:30 - 10:00am to catch the pop while using limit orders just didn’t work. Man I tried though for a couple years.
Then my employer enacted a 30 day hold period starting this year as well, so I had to redo everything. Weekly models are now impossible and I haven’t found one that isn’t weekly that beats my own models. Therein lies your second problem. Many people here have created great models and don’t have a desire to pay up for inferior or inflated performance.
Heck, you can get a great model for free, and it is mostly large caps. Cherrypicking the Blue Chips - by Marc Gerstein is one of only 3 I follow. Almost all large cap, 20% annualized return and low turnover (relative to P123) for that rate of return. You can tweak it and do even better.
Here is the type of model I would pay for:
-Monthly hold at least, but quarterly would be ideal
-mid caps and higher (I would prefer R1000 or S&P 500)
-low turnover
-low volatility
-40%+ return on a backtest (I find you lose about a third out of sample)
I currently have 10 large cap models that averaged about 28% annualized since 2009, but the volatility is like a roller coaster. Btw, all of them came from academia, this site, or my own models and didn’t cost me anything more than my P123 subscription.
Keep up the modeling for fun (I do too), but really concentrate on continuing to kill it on your microcaps.
Regarding microcaps, my approach is never to look at past prices when choosing stocks. I look at value, quality, volume, growth, sentiment, size, sector, etc. But never momentum or 52-week low or mean reversion or any technical indicators at all. I have no idea what prices my stocks traded for in the past and I don’t care. I do look at the past few day’s prices when I set my limit orders, but that’s it. So “timing” is only an issue if the price is rising so fast I’ll miss out on my valuation multiples when buying, or falling so fast that selling no longer looks like the best option. If you ever consider getting back into microcaps, my advice is to concentrate on fundamentals, volume, and sentiment.
With ROBUST modeling I doubt that I or anyone else is going to get a 40% backtest return on a R1000 portfolio with a quarterly hold. I may be wrong, but the last thing I want to do is offer a non-robust model and cross my fingers that it’ll do well. I want to offer only models I’m very confident in, and that means sacrificing some backtest returns. For example, I never backtest a portfolio of fewer than 50 stocks. I could achieve great results for a smaller portfolio, but they wouldn’t mean much going forward.
To be clear, I still by micro caps, but I don’t buy nanocaps. My microcap universe starts at $250MM in market cap. My previous experience was with nanocaps below that level. My point on the pricing was that these nanocap stocks showed backtested returns that were much, much higher buying Monday’s open than Monday’s close or the average. Not that price mattered directly. I had a bunch of screens that showed a 60-80% return from the open, but it might only return 30-40% at close. There was no real world ability to duplicate these models, unless you were in and out at that open.
The 40% target was monthly in my mind. Quarterly would obviously be lower. Regardless, I don’t understand your comment on robustness. What is your definition of that? How is one model more robust than another? I develop mine and then test them forward out of sample for at least 5 years. I use the same methods for all.
I also think that 50 stocks is way to many to trade. I do agree that you could never hit any decent returns on large caps at that level. I try to do 5 stocks a week, rolling 5 weeks to 25 positions. Under those conditions, you can hit some nice returns that are longer hold and actually executable. For microcaps under these conditions I am close to 40%. For largecaps its closer to 25%, but I haven’t testing that many factors and believe much higher results are possible.
If your model has 50 stocks traded weekly, then I don’t think anyone will pay for that.
I’m sorry I didn’t make myself clear in my last post, and I probably misread yours.
What I meant to say was that when evaluating or developing a strategy, I never backtest a portfolio smaller than fifty stocks. But when it comes to actually investing or showing my results to someone, then I’ll use a much smaller sample. The reason for this is that if you optimize your strategy by backtesting with only a small number of stocks, your results will have a lower chance of persisting, and you’re too liable to make changes to your system that won’t benefit its out-of-sample performance.
For example, let’s say you came up with two different systems, one for fifty stocks and one for five. The fifty-stock model shows a return of 25% per annum and the five-stock model shows a return of 40%. Would it be better to invest in the five-stock model or invest in the top five stocks of the fifty-stock model, even if a backtest run on those only got you 30%? I would argue for the latter, unless you could expand the five-stock model into a fifty-stock model that got better results. I wouldn’t offer any top-five, top-ten, or top-fifteen designer model unless I arrived at it through top-fifty or top-hundred backtests. That’s what I mean by robust modeling.
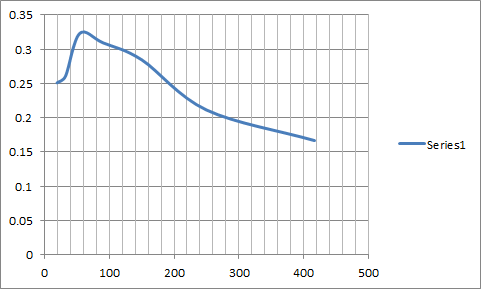
For what it’s worth, I recently did a correlation study of thirty similar strategies, testing them over eight different eight-year periods and comparing the results to the subsequent three-year periods. The eight-year tests were done with varying portfolio sizes ranging from 20 to 400 stocks. The subsequent three-year periods were with baskets of twenty stocks. The highest correlation of the thirty different strategies, by far, was when the first portfolio was in the 45-to-105 stock range. See the results below. Now I’m not saying my results are definitive, and they might vary some depending on universe size, the type of strategy being tested, the size of the “subsequent” baskets, etc. But that’s where I’m coming from.
Your real-world results impress me, and I respect your years of experience. I don’t get appreciably different results for my microcap and nanocap strategy when I backtest at the open, the close, or the high-low average. Maybe that’s because I’m backtesting large portfolios. As for my results, I’m getting over 50% per annum on my microcaps since 1/1/16, which is two months after I started using P123’s ranking systems.
You may want to think about this in another way. You spent a LOT of hard work developing excellent models. Instead of considering how much profit subs will make, consider how much MORE you can make. If you offer 1 microcap model for $25 to only 10 sums and it is successful out of sample, you will make $250/month, $3000/year, for no more effort than you have already spent. If you launch 5 $25 small cap models, with $1 Million or more liquidity and 20 subs each, you can have a total of $2500/month and $30,000/year. That is not pocket change. And for no additional work. The difference at $100/month is that you will have VERY few subs unless you systems outperform every other Designer Model out of sample. Consider the TWY 5 stocks HG EMA 11 SYS model at 323% gain over 4 years out of sample. It only has 10 of 20 subs at a cost of $88/month.
When an investor signs up for ANY mutual fund, ETF, or any other type of successful investment system, that investor is profiting from the hard work of the people that developed those systems. Why should you expect to be any different? Especially since there is minimal additional effort on your part and it won’t effect the profits you make on your systems.
And I wonder if you systems are all that different from many others on P123. Have you compared your holdings to the list of tickers in “Popular with our Users” on the P123 home page? Or the “This week’s top stocks in Portfolio123 models” list in the weekly Portfolio123 Weekly Performance Report? I always find 20 to 30% of my holdings listed there.
This is good advice indeed, and I thank you. I don’t know whether it’s realistic to expect such a lot of subscribers, but I might as well try. I do need to adapt my present systems for designer models since with a higher liquidity limit I’ll be emphasizing different factors.
My system is indeed very different from those of other users. I don’t have a single one of the stocks in the “popular with our users” list, nor do I have any of the stocks on the “top stocks in Portfolio123 models” list. My top seven holdings right now are INTT, ALSK, STRM, JIVE, CNTY, MEIP, and BASI. I don’t think those stocks are very highly ranked in most people’s models. Their QVG ranks are mostly pretty low: 60, 66, 30, 38, 98, 44 and 30 respectively.
How comfortable are subscribers with buying stocks that sell for under $3? There are plenty of good stocks with ADT over $500K but prices under $3 (e.g. VVUS). Should I put a lower price limit of $3 or $1 on my universe?
The overall return for QLD/SSO with basic market timing might be 20-30% but it will be quite volatile. Large cap designer models don’t have as much OOS but provide much less volatility - should be able to get return in the 20’s w/basic market timing.