What is your stock universe?
Here is some extra reading. Not all of the papers are as positive as the one I posted in the first post. If you have any thoughts on some of the research, please share them.
Researchers and practitioners hope that machine learning strategies will deliver better performance than traditional methods. But do they? This study documents that stock return predictability with machine learning depends critically on three dimensions: forecast horizon, firm size, and time. It works well for short-term returns, small firms, and early historical data; however, it disappoints in opposite cases. Consequently, annual return forecasts have failed to produce substantial economic gains within most of the U.S. market in the last two decades. These findings challenge the practical utility of predicting returns with machine learning models.
From the paper:
… Third, machine learning profits decline over time. As is the case for many anomalies, the abnormal returns over the past 20 years have been nowhere close to what they have been from
three or four decades before. … Combining all three dimensions does not build an optimistic picture of machine learning strategies. The interactions between return horizon, firm size, and time further undermined the implementability of machine learning strategies. For example, when yearly return forecasts are
considered, no significant abnormal returns have been recorded in the big-firm segment during
the period of 2001 to 2020. To put it simply, our machine learning strategies failed to produce
any alpha over the past 20 years in the stocks representing 90% of the U.S. market.
We propose a statistical model of heterogeneous beliefs where investors are represented as different machine learning model specifications. Investors form return forecasts from their individual models using common data inputs. We measure disagreement as forecast dispersion across investor-models. Our measure aligns with analyst forecast disagreement but more powerfully predicts returns. We document a large and robust association between belief disagreement and future returns. A decile spread portfolio that sells stocks with high disagreement and buys stocks with low disagreement earns a value-weighted alpha of 14% per year. Further analyses suggest the alpha is mispricing induced by short-sale costs and limits-to-arbitrage.
This article reviews ten notable financial applications where ML has moved beyond hype and proven its usefulness. This success does not mean that the use of ML in finance does not face important challenges. The main conclusion is that there is a strong case for applying ML to current financial problems, and that financial ML has a promising future ahead.
We reconsider the idea of trend-based predictability using methods that flexibly learn price patterns that are most predictive of future returns, rather than testing hypothesized or pre-specified patterns (e.g., momentum and reversal). Our raw predictor data are images—stock-level price charts—from which we elicit the price patterns that best predict returns using machine learning image analysis methods. The predictive patterns we identify are largely distinct from trend signals commonly analyzed in the literature, give more accurate return predictions, translate into more profitable investment strategies, and are robust to a battery of specification variations. They also appear context-independent: Predictive patterns estimated at short time scales (e.g., daily data) give similarly strong predictions when applied at longer time scales (e.g., monthly), and patterns learned from US stocks predict equally well in international markets.
The emerging literature suggests that machine learning (ML) is beneficial in many asset pricing applications because of its ability to detect and exploit nonlinearities and interaction effects that tend to go unnoticed with simpler modelling approaches. In this paper, we discuss the promises and pitfalls of applying machine learning to asset management, by reviewing the existing ML literature from the perspective of a prudent practitioner. The focus is on the methodological design choices that can critically affect predictive outcomes and on an evaluation of the frequent claim that ML gives spectacular performance improvements. In light of the practical considerations, the apparent advantage of ML is reduced, but still likely to make a difference for investors who adhere to a sound research protocol to navigate the intrinsic pitfalls of ML.
From the paper:
Many studies that report strong results for ML models focus on predicting next 1-month returns
based on a large number of traditional factor characteristics as input features. Although the models
load on traditional short-term return predictors they are able to exploit additional nonlinear alpha
opportunities. The challenge with these models is to turn the resulting fast alpha signals into a
profitable investment strategy after costs and other real-life implementation frictions. The
corresponding literature is scarce, and the few works naturally suggest that the opportunity set for
ML models to outperform traditional ones is often reduced given the reliance of ML models on
high-turnover signals.
Machine learning for asset management faces a unique set of challenges that differ markedly from other domains where machine learning has excelled. Understanding these differences is critical for developing impactful approaches and realistic expectations for machine learning in asset management. We discuss a variety of beneficial use cases and potential pitfalls, and emphasize the importance of economic theory and human expertise for achieving success through financial machine learning.
Machine learning (ML) models for predicting stock returns are typically trained on one-month forward returns. While these models show impressive full-sample gross alphas, their performance net of transaction costs post 2004 is close to zero. By training on longer prediction horizons and using efficient portfolio construction rules, we demonstrate that ML-based investment strategies can still yield significant positive net returns. Longer-horizon strategies select slower signals and load more on traditional asset pricing factors but still unlock unique alpha. We conclude that design choices are critical for the success of ML models in real-life applications.
From the paper:
… but that their performance has weakened substantially in the second half of our
sample period. However, we show that by incorporating efficient portfolio construction rules, … and using longer prediction horizons to train the machine learning models, significant after-cost
returns can still be achieved by machine learning-based investment strategies.
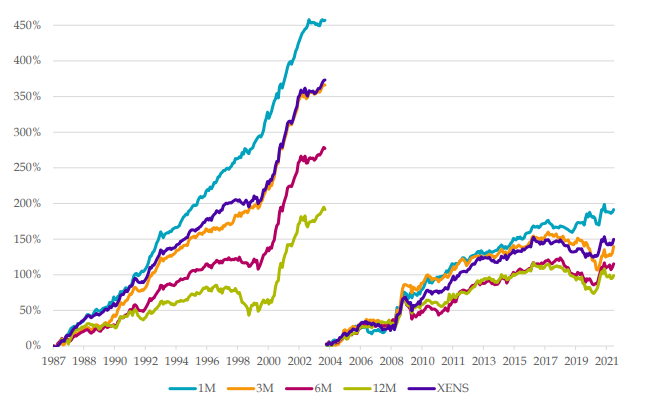
We theoretically characterize the behavior of machine learning asset pricing models. We prove that expected out-of-sample model performance—in terms of SDF Sharpe ratio and test asset pricing errors—is improving in model parameterization (or “complexity”). Our empirical findings verify the theoretically predicted “virtue of complexity” in the cross-section of stock returns. Models with an extremely large number of factors (more than the number of training observations or base assets) outperform simpler alternatives by a large margin.
We analyze machine learning algorithms for stock selection. Our study builds on weekly data for the historical constituents of the S&P 500 over the period from January 1999 to March 2021 and build on typical equity factors, additional firm fundamentals and technical indicators. A variety of machine learning models are trained on the binary classification task to predict whether a specific stock out- or underperforms the cross sectional median return over the sub-sequent week. We analyze weekly trading strategies that invest in stocks with the highest pre-dicted outperformance probability. Our empirical results show substantial and significant out-performance of machine learning based stock selection models compared to an equally weighted benchmark. Interestingly, we find more simplistic regularized logistic regression models to perform similarly well compared to more complex machine learning models. The results are robust when applied to the STOXX Europe 600 as alternative asset universe.
This ML module, that may be released already in the middle of March, would that require the use of API credits, or cost anything extra ?
It will not use API credits. That’s for traffic to/from our network, AI is all internal for now. There will be additional costs which will be initially be somewhat high and gradually decrease. The costs breakdown is (tentatively): 1) a fixed monthly cost 2) a variable cost based on resource utilization 3) a storage cost for datasets.
Which means that to research for a few months should not be that costly. And just doing predictions for live models, or model maintenance, will be affordable. As always, our mission is to make it affordable for retail users as well as non-retail. But our AI backend is not very big right now (we have our own servers) so we need to limit the usage at first somehow. If demand materializes, we may also leverage the cloud for large jobs like CV of hundreds of models, or just buy more hardware from the likes of SuperMicro (how did I miss this stock !?)
1 Like