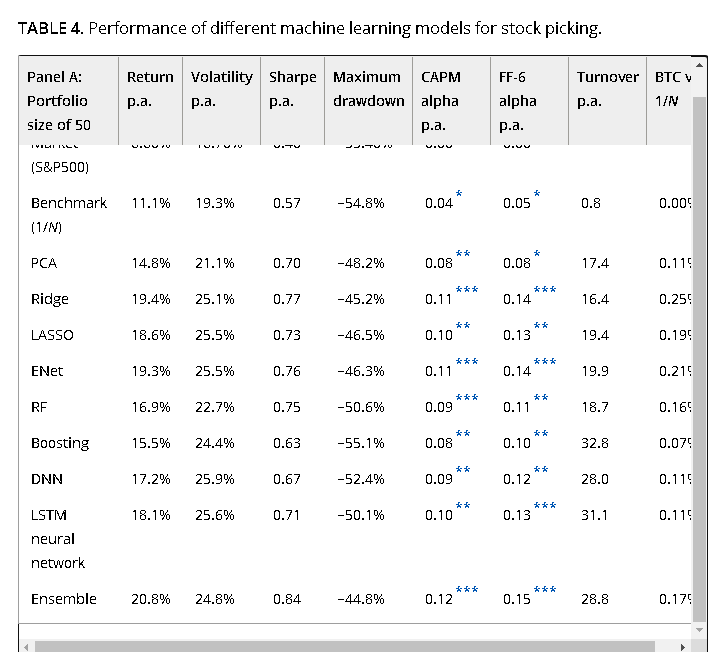
… "Our empirical results show substantial and significant outperformance of machine learning-based stock selection models compared to an equally weighted benchmark. Interestingly, we find more simplistic regularized logistic regression models to perform similarly well compared to more complex machine learning models. " …
From the paper: “Next, we analyze a trading strategy that picks stocks with the highest outperformance probability prediction.”
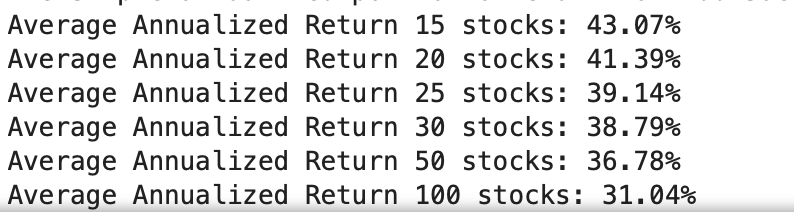
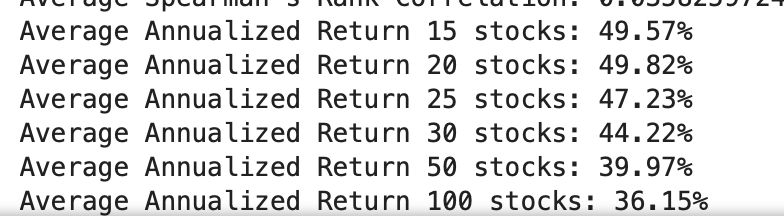
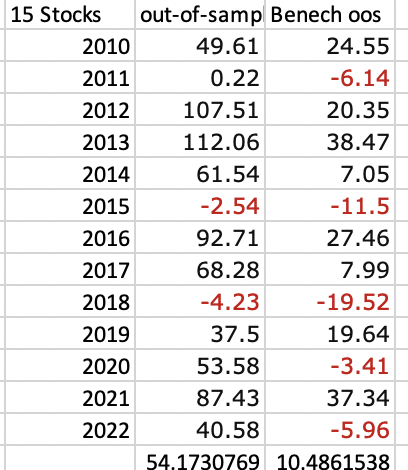
Doing this with an Extra Trees classifier (with probability prediction as in the paper) and common P123 factors (k-fold cross-validation with a 3-year embargo):
Conclusion: This Extra Trees model (using both classification and regression) with these factors does better using regression when compared to the same model using classification.
TL;DR: You can rank stocks based on the predicted returns (regression model) or on the probability of having excess returns relative to a benchmark as done in this paper (classification). Anecdotally in this one example regression did better.
Thanks for an interesting, simpler to read paper (or maybe I’m starting to get used to it).
The main takeaway is that we are on the right track for our ML release. Some things will still be missing, but most of what the paper is doing will be doable in P123.
What’s different in this paper vs. others that aligns well with P123?
data from 1999
weekly sampling
straightforward factors that are easily reproducible
Table 5 with sub-period returns showing consistency through time is particularly interesting. Our fixed weights ranking systems show alpha decay over 20 years as the new Rank Performance tool clearly shows. Retraining weights every year or so is key. And it is very easy to do with ML once you picked the model(s).
Marco, will dynamic ranking system weights be supported in general? I already use ML methods for model selection external to p123 but am currently forced use a single static set of weights. I would love to be able to upload a date-indexed set of weights for a model and have p123 use the “as of” vector of weights when ranking a given date. I would hope this functionality will be possible even if not using p123’s provided ML methods.
I don’t understand why you are using such a long (3 year embargo). I thought that an embargo equal to the planned trading frequency which is typically the future price goal in training would be enough. I understand using k fold with factors containing factors like 3 year average ROI there will be some small amount of data leakage but the factor importance of these is small in my models.
I’m not trying to be critical, your obviously ahead of me on the curve but just trying to understand what you are doing.
I think there are several good ways to answer that starting with what you might need to know most.
You probably do not need an embargo. You can probably just use k-fold cross-validation or time-series validation if you prefer that method (or both). I use both at times (or either).
I think this is exactly right if you are talking about the target. An embargo is a different thing. But what you are doing is what I would use as a target if that is what you are thinking of. You are on the right track if you are thinking of what to use for a target.
Just if you want a direct answer to year question as clearly as I am able to make it: Using an embargo could be considered as simply a modification of the k-fold cross-validation. It was developed by de Prado and is discussed in this book.Advances in Financial Machine Learning
So the term used in the book is “information leakage.” I struggled with his for the longest time. It was VERY DIFFICULT for me.
The advantage of the way ChatGPT does it is that it explains it in several different ways. Perhaps, one will resonate with your present experience. I am happy to try to expand on this but ChatGPT simply says it better:
"Marcos López de Prado, in his work on financial machine learning, emphasizes the importance of using an embargo period when performing k-fold cross-validation in financial modeling. An embargo period refers to a time gap between the training set and the testing set.
Here are the reasons why an embargo period is important:
Non-Overlapping Samples: Financial time series data is often autocorrelated, meaning that observations close in time tend to be similar. If a model is trained on a dataset that includes information very close in time to the test set, it can inadvertently “peek” into the future. This leads to overfitting as the model may just be learning the noise specific to the dataset rather than any true underlying patterns.
(Note: This first reason is the reason most similar to what is in de Prado’s book. It is, perhaps, the most difficult to understand and he manages to make it even more difficult, IMHO)
Out-of-Sample Testing: By including an embargo period, we ensure that the model is truly tested on out-of-sample data which it has not seen before. This is crucial for assessing the model’s ability to generalize to new, unseen data.
Avoiding Look-Ahead Bias: Look-ahead bias occurs when a model uses information that would not have been available at the time of prediction. An embargo period helps to prevent this by ensuring that there is a clear separation between the training data and the data used to simulate the “future” where predictions will be made.
Market Regime Changes: Financial markets can go through different regimes or periods where the underlying behavior of assets can change significantly. An embargo can help to ensure that the model is robust to these shifts by not allowing the model to become too finely tuned to a specific regime that is present in the training data.
In practice, the implementation of an embargo period means leaving out a gap between the end of the validation dataset and the beginning of the training dataset during the cross-validation process. The length of the embargo period can be determined based on the autocorrelation structure of the data or based on domain knowledge of the asset or instrument being modeled."
BTW, the embargo probably does not need to be that long if you end up using it. 3-years is pretty long and was done more as a convenience (leaves out one DataFrame from the DataMiner downloads). Hope that helps some.
Thanks for the definition of your embargo. I’m going to have to start using Chat GPT, they actually do seem to come up with some clear definitions along with some off the wall answers. I have De Prado’s AiFML book but his explanations in chapter 12 are not the easiest to understand. The Hudson & Thames youtube Cross-Validation in Finance and Backtesting - YouTube and quantinsti’s blog with python code examples Cross Validation in Finance: Purging, Embargoing, Combinatorial (quantinsti.com) were helpful for me. But I still haven’t gotten a ML using it working yet, and like you I find a lot of this very difficult!
I do not have a comparable study of that using the same cross-valdiatoin method or the same periods.
Equal-weight of my factors seems to do pretty good. But is seems so random to me. The weight of growth factors, for example, is totally dependent on the number of growth factors I have looked at. If I keep adding growth factors when is it too much weight on growth. Maybe I force myself to spend equal time looking at each type of factor?
So I don’t usually use it for a comparison anymore. But it did pretty good when I looked at it. It was not the best model when I looked at it.
Walk forward of what I am doing now including selecting factors with an algorithm as part of the training to reduce look-ahead bias if I understood your question:
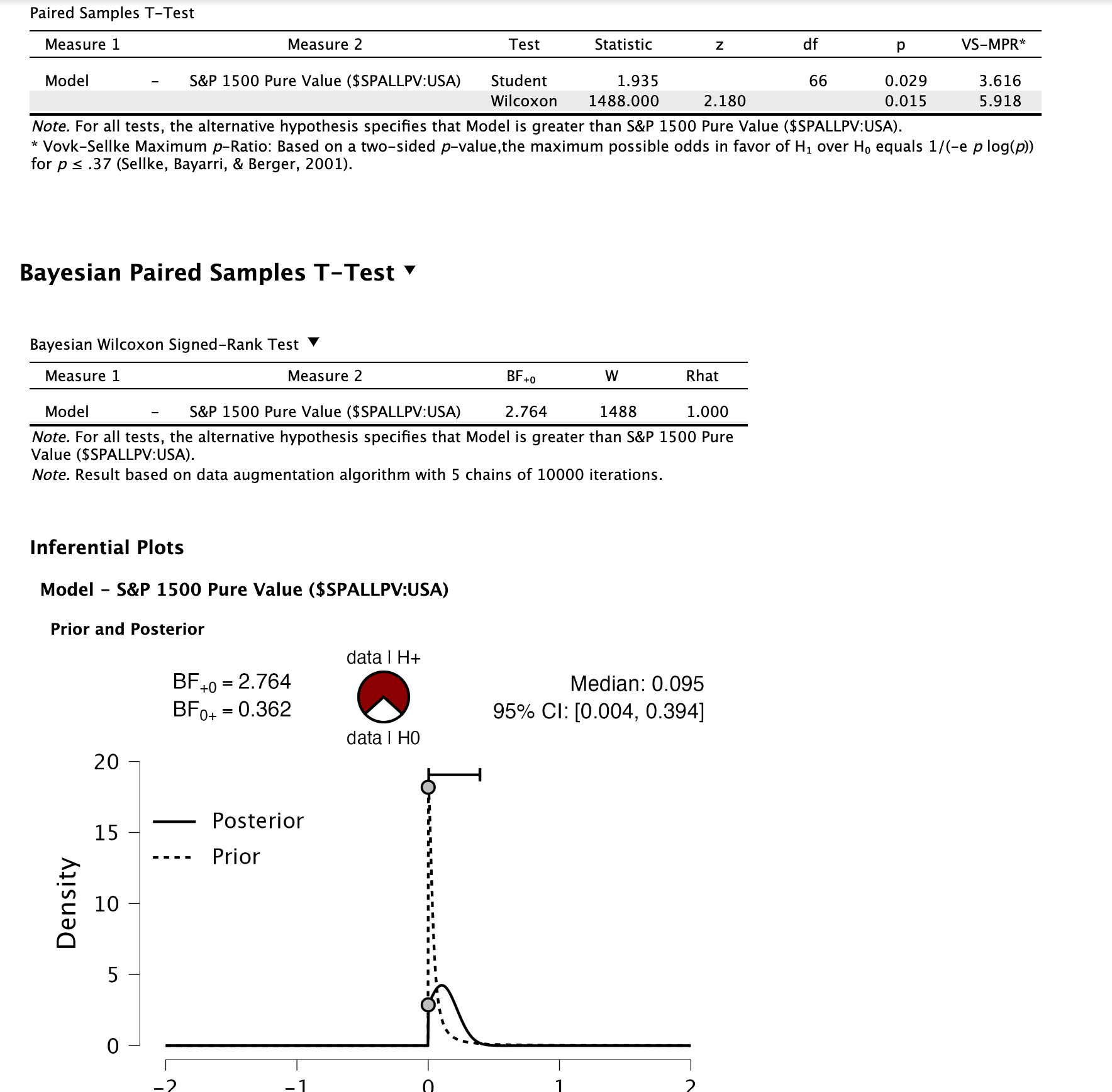
I do not want to get into a competition with my funded out-of-sample results But I looked at the statistical significance of my median-performing model this week-end. Let me give you the results without a lot of comment.
If you are a fan of using Bayesian statistics to avoid p-haking then not quite into the category of "worth mentioning with the limited data. It is what it is:
As a reminder according to Jeffrey’s scale “not worth more than a bare mention” yet but close to three. Time will tell what happens with more out-of-sample data It is what it is:
Independent of the Bayesian statistics, the ML is always better than 2x of the original version.
Second, if one uses the factors without ML they will not make a great strategy
Now I do not understand at all, why I can’t get an ML signal from the Small Cap Focus to improve it at least onto that same level…
Some other topic, regarding Spearman correlation.
I found in the book from Stefan Jansen… How to evaluate if a factor produces forward returns. It looks like the “standart” is Spearman correlation (AKA IC) . “An IC of 0.05 or even 0.1 allows for significant outperformance…” This IC is built into Alphalens from Quantopian. Just peaked into the code on GitHub, looks like its stats.spearmanr what they are using for IC.
It’s been discussed a few times. But future enhancements of the “classic P123” will have to be carefully designed to combat curve-fitting head on. It’s a big problem with our tools now. You have to know a great deal to use them properly, and with many cumbersome steps.
We have to put the user experience first. The latest upgrade to Rank Performance tool is a step in the right direction.
We’ll see after the ML release. Perhaps you will not want it so much and convert your ranking system to an ML model.
It uncanny how well the paper’s analysis aligns with p123 capabilities. Any consideration about inviting the authors to use p123 ML tools for critical feedback?
The one thing that’s missing from this paper is any comparison between machine-learning-based stockpicking and stockpicking based on, say, ranking systems or multiple regression. The authors could have easily optimized a ranking system and/or a multiple regression model on exactly the same data and then run it on exactly the same period. I really wonder what the results might have been.
It’s also quite disappointing that these models require an average transaction cost of less than 5 or 10 basis points to break even.
I remain bullish about the potential of ML models, but given the extremely low transaction costs required, this paper lessened rather than increased my confidence in them.
A quote from the paper: “A variety of machine learning models are trained on the binary classification task to predict whether a specific stock outperforms or underperforms the cross-sectional median return over the subsequent week.”
In other words they used classification and only classification with no regression in this paper. This is the most salient feature of the article, IMHO.
Everyone seems to think this is a wonderful paper to be emulated. Because of this almost unbounded enthusiasm, I wonder is P123 pursuing classification, regression or both in the beta release? Not only is it the most salient feature in the article but I think it is probably the most important decision P123 will make (will have made) if P123 is going to chose just one method (regression versus classification). If both, then I guess they will be including the better method (whichever one it happens to be).
I had assumed P123 would be going with regression but the enthusiasm for this paper that, again, only uses classification makes me wonder.
This is just a question that without a doubt would have been considered and answered by a trained AI/ML expert by now. Especially considering how close we are to the release. I am agnostic as to which way P123 should go on this. I don’t have an opinion and use cross-validation to guide me with each model I use in what is hopefully a relatively unbiased manner. Other people may have different results–including the author of this paper apparently.
BTW, if P123 goes with the classification method I would like to see Bier Skill Score as a metric in the rank performance test. I don’t see how you could use Pearson’s correlation for classification models.
Regression at first. We did discuss classification. Checking with developers again to make sure adding it won't require major work (it did not seem like it last time it was discussed).
Marco, wise choice I think. I would have done regression first too: see my post above… Thanks for the reply.
My take on the paper: might have been okay if the authors had included regression models as a comparison. But not pertinent to the upcoming P123 beta based on Marco’s reply above.