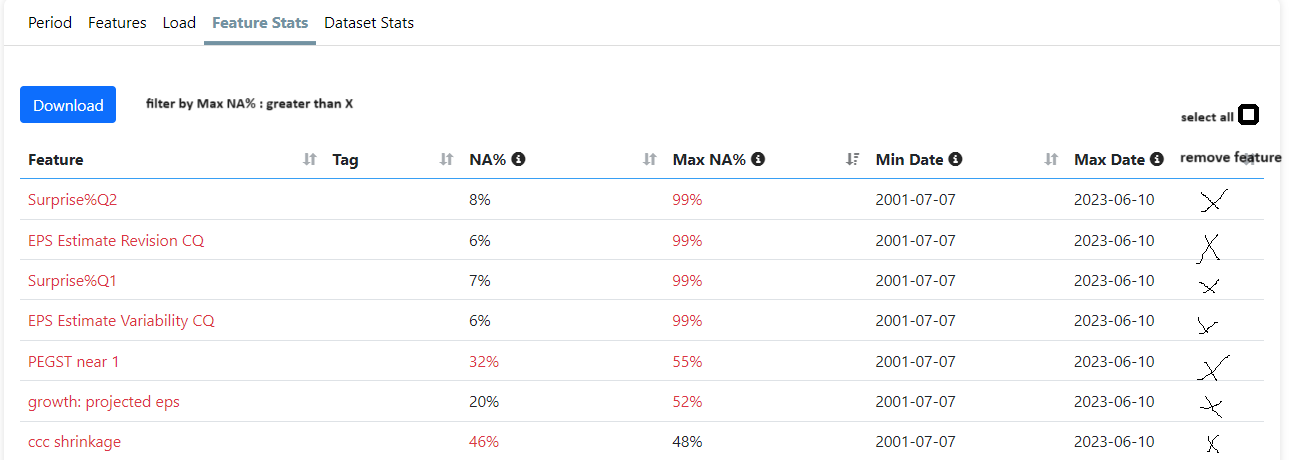
Also a problem for earnings estimate revision up until about 2005, I think. And others features. I had to remove a few features (two features). And/or change the data period for earnings estimate revisions.
i learned something about some of my factors and NAs are a problem and ways to deal with them, e.g., impute etc are important. .Something I am usually too lazy to do.
But I think this is also true: NAs are not as much of a problem with tree models as it is for a linear regression model.
Sorry to admit this but I asked ChatGPT about this. It would go along with "less of a problem" with tree models but I could not get it to say "no problem."
Still you could imagine a random forest (or HistGradientBoosting being a better example) making some of its splits right at the NAs bucket or empty bucket. Ideally, at times, splitting the data into NAs and not NAs (or zero buckets), And even recognizing the times where being NA is useful information.
For example, a small stock with no analyst coverage and therefore giving an NA for Surprise%Q could actually do better because of the lack of analyst coverage (and P123's AI using other data that is not being followed by a lot of people).. A tree model could, at least in theory, recognize this.
Anyway, no conclusions on my part but I am not convinced that the threshold for removing a factor should not be at least different when using a tree model.
@Pitmaster and @Marco, I have this idea for discussion. Why not give NAs a NEGATIVE rank and give the NA returns for those buckets. Therefore a tree model can always, consistently split on the NAs. as the number of NAs changes throughout the years. And use that information.
So again, embarrassed to admit but I wanted to get a first impression of my idea. As per ChatGPT: "
Negative Ranks for NAs:
"Assigning a negative rank to NAs could ensure that the tree models consistently recognize and split on NAs, treating them as a distinct and potentially informative category.
Consistency Over Time:
By giving NAs a specific rank (e.g., negative), you provide a consistent way for the model to handle missing values across different time periods, which can help in making more reliable splits."
Conclusion: You should probably do something like that for tree models unless I am missing something. Forget imputation etc.
Keep and use any information that the NA category or classification provides.
Jim