TL;DR: This is a nice feature. Extremely advanced and just plain cool. Please fix it.
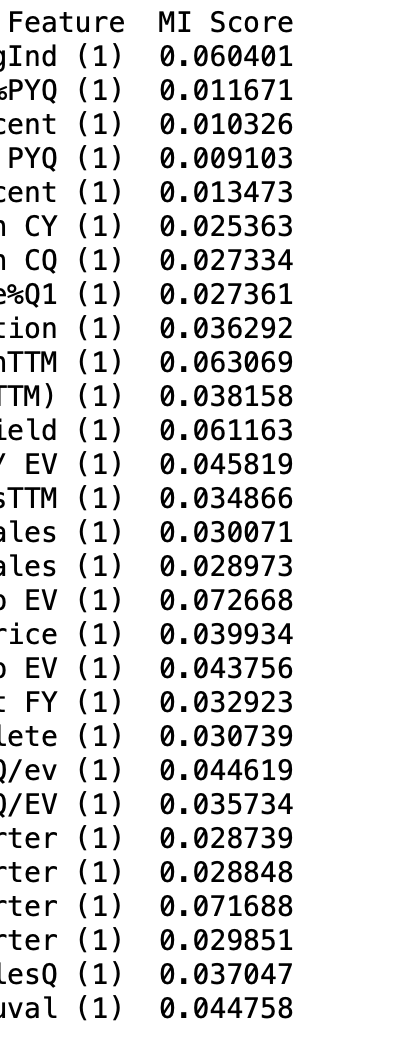
I ran it on some factors downloaded with DataMiner. I cut off the full feature names:
These number make sense and would be very useful!!! Specifically, the numbers for the factors in the post above were not zero and probably reflect their true importance. For sure, I do not need to be mislead into removing those factors.
Use my code and see if you get different results from AI Factor Beta if you have any downloaded factors to test:
from sklearn.feature_selection import mutual_info_regression
import numpy as np
import pandas as pd
# List of factors
factors = []
# Read data
df8 = pd.read_csv('~/Desktop/DataMiner/xs/DM8xs.csv')
# Combine data for training
df_train = df8.copy() # Use copy to avoid setting with copy warning
# Drop rows with missing values in any of the factors or target column
df_train.dropna(subset=factors + ['ExcessReturn'], inplace=True)
# Define features (X) and target (Y)
X = df_train[factors]
Y = df_train['ExcessReturn']
# Compute mutual information scores
mi_scores = mutual_info_regression(X, Y, n_neighbors=3)
# Display the mutual information scores
mi_scores_df = pd.DataFrame({'Feature': factors, 'MI Score': mi_scores})
print(mi_scores_df)