[quote]
I would get far better results were I to exclude models that show signs of curve-fitting rather than robust backtesting (but that would have to be subjective and post-hoc, invalidating those results).
[/quote]Yuval, this particular model has a very objective curve fitting tell.
The oos flatline periods were not present in the backtests. That is clear giveaway that the buy rules were over optimized.
You have to understand that the original R2G system was designed to fail. The only way to attract subscribers was to put up the best performing simulations regardless of whether or not they made sense.
As for optimization, I am finding success by:
choosing an industry or subindustry that I expect to trend higher based on macro-economics (examples: cloud computing, defense)
find two or three best performing factors for the recent past (3 - 5 years)
create a highly optimized port using a ranking system with the optimized factors. Minimal buy/sell rules
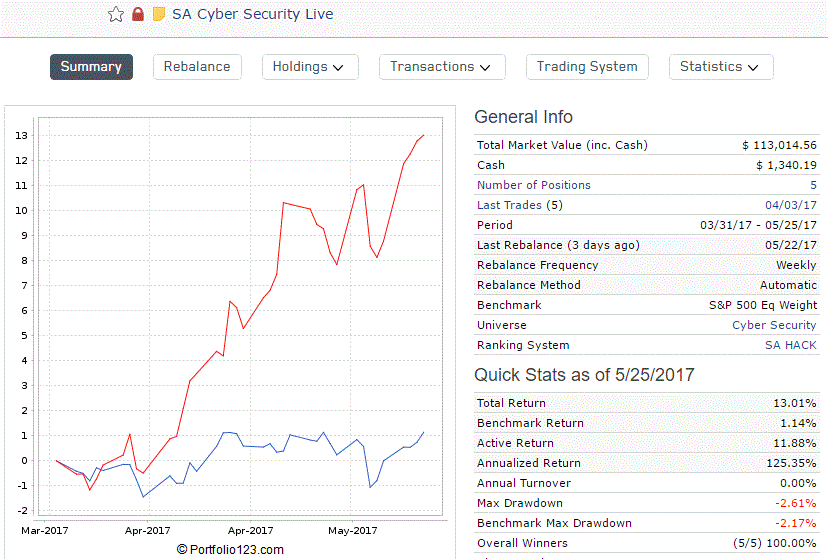
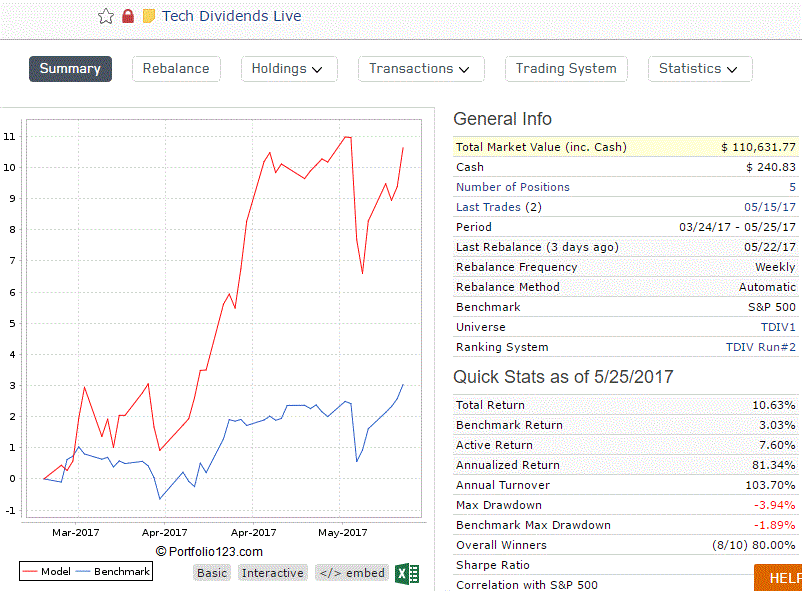
Also I have two private ports that have been running for a while: Cyber Security and Tech dividends. The underlying universe for both of these and also the Cloud Computing DM are inlists created from ETFs. The OOS for Cyber Security and Tech dividends performance graphs shown below.
Georg very helpfully told me that I could use a Simulated Book with one asset, namely a designer model. So I ran equity curves doing that and used Excel for the correlation studies. I wish I’d known of that trick before! It gives you both the complete backtest and the OOS results (without any distinction between them).
One more reason R2G (Smart Alpha) is a bad idea. My view is P123 should get rid of it, but Fat Chance, some people are making a living off of it, and Marco thinks this is the way to the masses.
Overfitting with market timing is the most damaging, I think. If I overfit the rule of buy stocks starting with “A” because it captures AAPL on the backtest the port may not suffer too much. It probably will not outperform because the universe is too constricted. But I may not underperform unless stocks starting in “A” are having a bad year.
If I overfit with the rule of buy on a full moon and sell on the crescent moon I get the flatline with no performance. I am out of a generally rising market and I underperform.
But designers face serious pressure to avoid the drawdowns, I think.
Maybe I can look at “% invested” this weekend and see if this is actually an important factor and not just theory.
Maybe start by seeing if there is a correlation between “%invested” and the returns.
Yuval, thanks for sharing and bringing this back up as a topic for discussion. As we have discussed a few times on the boards before, I have been running statistical analysis like this for the past couple of years. My focus has been on monthly predictions, not annual, but I have seen similar results for short timeframes. One thing I will mention about your analysis is that you don’t really have a sizeable population to work from using simulations. I utilize the rolling backtest feature to create a decent sized database. My latest version has 695 data sets for 30 largely uncorrelated screens (5 stocks each), using a 4 week hold. Using that data set and looking at relative performance, I have found much higher correlations. Using raw performance has very little correlation. I only have 695 data sets because I use the first 5 years of data for development and roll it forward OOS to see how they perform. You could do the same thing on an annual basis, but I think the correlations will be low.
Your intuition on alpha is spot on. I evaluate my data using average return, Sortino, Sharpe and Alpha. Alpha has the highest correlation of the four. Sharpe is the lowest and Sortino and average are in the middle. All of them have the highest R-squared values around the 4 year range. I have tested longer periods, but the coefficients drop off.
Below is a data snapshot using 4 year Alpha to predict the next month’s returns. The R-squared for this data set is 82.6%. For perspective, the 1 year is only 11.4%.
In plain terms what this means is that if you invested in the top 3 screens based on 4 year alpha, then you would have an average monthly return of 2.71% vs. 2.1% if you invested in all 30 screens. The nice thing about this method is that is should avoid curve fitting and it will rotate away from screens as their Alpha starts to fade. Putting this together and updating it each week is a giant pain the a$$, but it is worth it for the additional 11% CAGR.
Not that anything in any of the text books should matter. Those guys are crazy. I guess it is just size (of the dataset) that matters after all. But,
rolling tests are not independent as the data overlaps.
You are taking something that may not have problems with being a time series (monthly data) and converting it to a time series–multiple 3 year time series. As you know the problem is that times series will often show correlations that are not real. Wow!
3)when you do rolling tests don’t months get included in the data more than once (in more than one rolling period). For a 3 year rolling average counting the same month 36 times!?!! Is that what you mean?
Counting a month 36 times will give you more data—no arguing that one.
Mike, just a rhetorical question: you should continue-on and don’t mind me. I’ll go back to my texts a figure out where they went wrong.
I hope things continue to go well with your investing.
Your post is really very helpful, and thank you for sharing your insights. I take it, though, that there’s no way to get rolling backtests for designer models, right?
I wanted to suggest two additional measures that I have found very helpful, equal to OLS alpha in my correlation studies: median excess return (the median of the differences between monthly return and monthly benchmark return) and LAD (least absolute deviation) alpha. If you’re using Excel, you can get LAD alpha by downloading a resource pack from real-statistics.com.
Thanks for the suggestion on the analysis. There is no way to do rolling backtests on screens from others. I have borrowed from some on P123, so my 30 screens are not all my own. It is a good tool to use for your own benefit.
Jrinne,
Your point about data overlap is a valid one, so let me add a bit more detail about how I do the analysis. Because I have to hold stocks for a minimum of 30 days, I basically roll 4 sets of portfolios. My start dates are 1/5/2004, 1/12/2004, 1/20/2004, 1/26/2004. After that everything repeats to your point. I also lag the data to account for timing of buys/sells so I am not using future data. I modeled the approach after many of the academic research papers that I have reviewed. I agree that text books and academia don’t always offer a realistic approach. My real world application is I turn 25% of my portfolio each week. I have also analyzed weekly data in the past, which doesn’t have the same data issues, and it also correlates well. I don’t bother updating it anymore since I cannot use it. I also did the same analysis from AAII data that was only monthly and found similar correlations. There is some overlap of the 4 time series sets that I use, but you would be surprised how uncorrelated they can be over time. If you want to test it for yourself, do 4 straight backtests using the dates above using 4 week holds and see how different the data is. One more key point, the Deciles in the previous post are not part of the data sets at all. They are single month returns from 5 weeks in the future.
Could this analysis be fool’s gold? Sure, but I don’t have a better way to choose a handful of stocks from the 150 stocks I have available each week from my 30 screens. It does make me feel better that generally the correlations are low in the short run, go higher as you approach 3-4 years and taper off longer term. I am definitely open to suggestions if anyone has a better way to analyze the data.
Mike,
This seems like a great idea to me. At a minimum it should reduce slippage and it should reduce risk too.
With regard to statistics. I have made all of the mistakes that can be made.
I have become very conservative. I take the assumptions seriously.
Personally, I would average together the weekly results—for each week-- for all 4 of those ports and compare the averaged weekly results to the benchmark’s weekly results. That is a direct measure of what you are doing with your money and avoids most problems with assumptions. If you cannot get the information you want out of that at least consider that the information you want might not be there.
More generally, there are some pretty smart people doing designer models. To point out that there are problems with these models and claim we are going to solve them by adding more complexity to our models or our statistics is not the direction that I want to go. I do not think it will work. How could it possibly be a solution to the problem of overfitting?
I will be going toward the basics and simplicity.
Very thoughtful post. I’m pretty sure you are making money and really do not need my $0.02. These are just some of my biases.
Hi all, I’m a long time investor but am new to learning portfolio123 (in trial now but am probably going to subscribe). This is my first post in the forums here.
Your comment about lagging data like in academic papers caught my eye and wanted to ask for elaboration if you could. Is there some concern among users that something about the portfolio123 databases might be looking into the future? I understood the database to be carefully constructed with an eye for correct point-in-time data, but if there are concerns I’d appreciate understanding the concerns about need to lag.
As to OP, my thought is: in my limited experience it’s so easy to curve-fit and not be aware we are doing it. Just tinkering around in my trial period here I find myself doing things akin to curve fitting - essentially trying different combinations of an idea and seeing what works better (certainly something will fit the data better). As powerful as portfolio123 is, it’s hard to just code an idea, test it once, and if it has some alpha leave it alone w/ only small tweaks. I worry that much beyond that I’m getting into curve fitting territory.
Just my two cents: optimizing your results and curve-fitting can be two different things. When you optimize your results, you go back and retest with different numbers of holdings, different time periods, different universes. You look not just at raw returns but at alpha and maybe some other numbers. You change things up a lot and see if your thesis still fits. Then your optimization can be non-problematic–robust, in a word. If you stick with one set of data–say you optimize a 10-stock portfolio over a five-year period in a specific universe–and you don’t apply what you’ve done to a somewhat different data set, then you’re curve-fitting. Robust optimization can be very good for successful investing. Curve-fitting can’t. My advice is to optimize BIG: huge portfolios (50 to 100 stocks), huge universes, very long time periods, rolling backtests. That’s the best way to discover what works IN GENERAL. Then you can narrow things down to more specific situations.
I hear you I’ve heard one trader say he wants his models to be like “loose fitting pants”. Not perfectly tailored, but baggy and flexible.
As a trial member I only have 5 yrs to work with now on the backtester, and I realize how limiting that is, but it’s surprising to me how well backtests on even extremely simple models with only 1 or 2 key ideas can systematically perform on large # of stocks meeting the criteria. So big, wide, and simple has real appeal to me, but I’ll know better once I join and can test back to 2000 or so.
I think the chart of one of the strategies above that went flat after the backtest period illustrates how easy the danger is when optimizing though. Based on the flat area of the backtest around 2008/2009, I wonder if the modeler made an assumption around market regime like “I can avoid these drawdowns if I go to cash (or different signal) when the market is below a certain xday MA” It works great during the 08-09 financial crisis, and everybody uses a 200MA, why shouldn’t I? With hindsight it seems reasonable, even prudent, to get out of a market during a decline like that. But ever since then large pullbacks have been a prime buying opportunity.
I used a similar rule in a short term trading model to trade differently in different regime (with the down mkt regime being heavily dominated with what happened in the crisis), and I’m still uncertain whether it’s prudent, or whether it’s curve fitting. There’s just not enough of those type events to know. Reserving out of sample sometimes doesn’t help with that. Also, the model I built relied on a volatility regime that’s just not happening now. (I duplicated the basic idea here in port123, and the past year or two of low vol don’t fit the model’s signals well at all).
Anyhow, thanks for the thoughts. Really impressed with the port123 platform so far.
It is hard to “curve fit” with fundamental data. If you Google it or look at software packages curve fitting is literally finding a curve that fits the data.
We curve fit at P123 with a bunch of moving averages or technical factors. Visually looking at a curve then fitting it by controlling the stocks in a port with fundamental data is literally impossible.
Once you have fit-the-curve it is a matter of going long or short (or to cash) on this curve.
Curve fitting is market timing. It is easy to get it wrong.
Over-optimization of fundamental factors is different. It has different characteristics. One of those being that it is harder to over-optimize than it is to curve-fit. Over-optimization can be a problem, it is to be avoided but it is a different animal—one that can be tamed.
There will always be some over-optimization but this has to be weighed against the need to do some tests to find something that works well in a nearly efficient market. For sure, I will never get it perfect. But I think it is possible to add an edge to your investing, without over-optimization that is too damaging, in pretty short order.
I wish to correct an error of mine. This is a quote from Yuval’s post above.
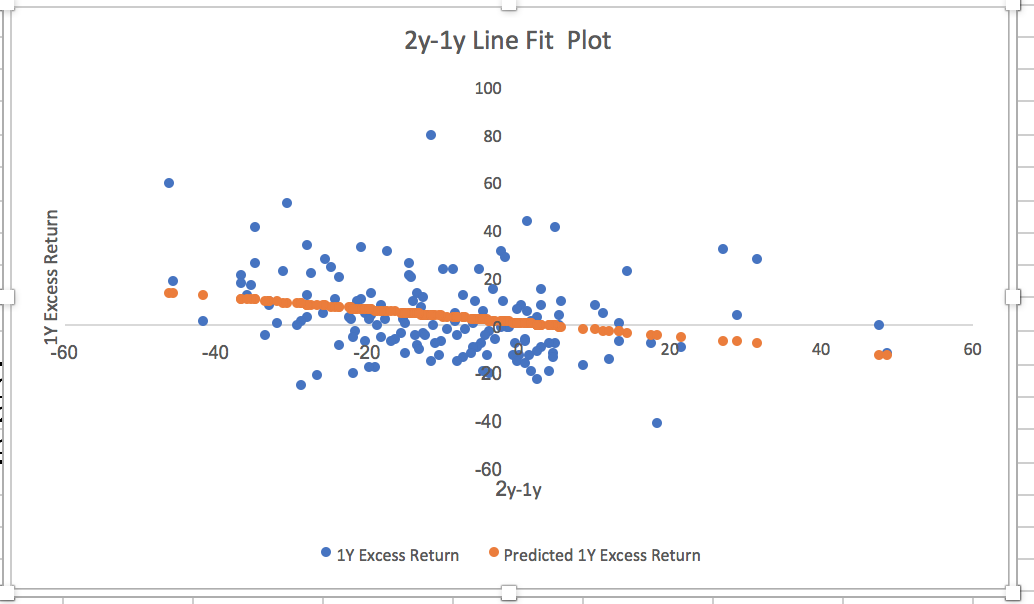
I found this to be very strange and of course interesting—if true. I replicated the regression based on the above math in my post: see the repeat of my image below.
The regression is correct but there is a math error for calculating the excess returns for the period 5/24/2015 to 5/24/2016.
You cannot take the 2 year excess returns and subtract last year’s excess returns to get the excess returns for 5/24/2015 to 5/24/2016. This is due to compounding.
Simple example. Suppose a stock beats its benchmark by 50% every single year. Regular like clockwork.
The excess returns for the last year will be 50%. But for 2 years it will be 125% ((1.50^2 - 1)*100). Subtracting last years excess returns from the 2 year excess returns will give you 75% (125% - 50%) excess returns for first of the 2 years (or the period 5/24/2015 to 5/24/2016 in this case).
So if we put this stock into our linear regression with the above rules: “I then took the 2-year excess performance and subtracted the 1-year excess performance to get the excess performance of the models during the period 5/24/2015 to 5/24/2016. I then did a simple correlation between the 1-year excess performance and the prior year’s excess performance.” then………
We would get a point (75%, 50%) in the scatterplot for this example using the incorrect math rules above. This is despite the fact that the excess return was 50% each year!!! I.E., the point should be (50%, 50%). This error leads to the false appearance of a negative correlation.
The negative correlation should be no surprise. It is expected in light of the incorrect math. The image below (and the negative correlation) is based on incorrect math and should be ignored. Sorry for my mistake.