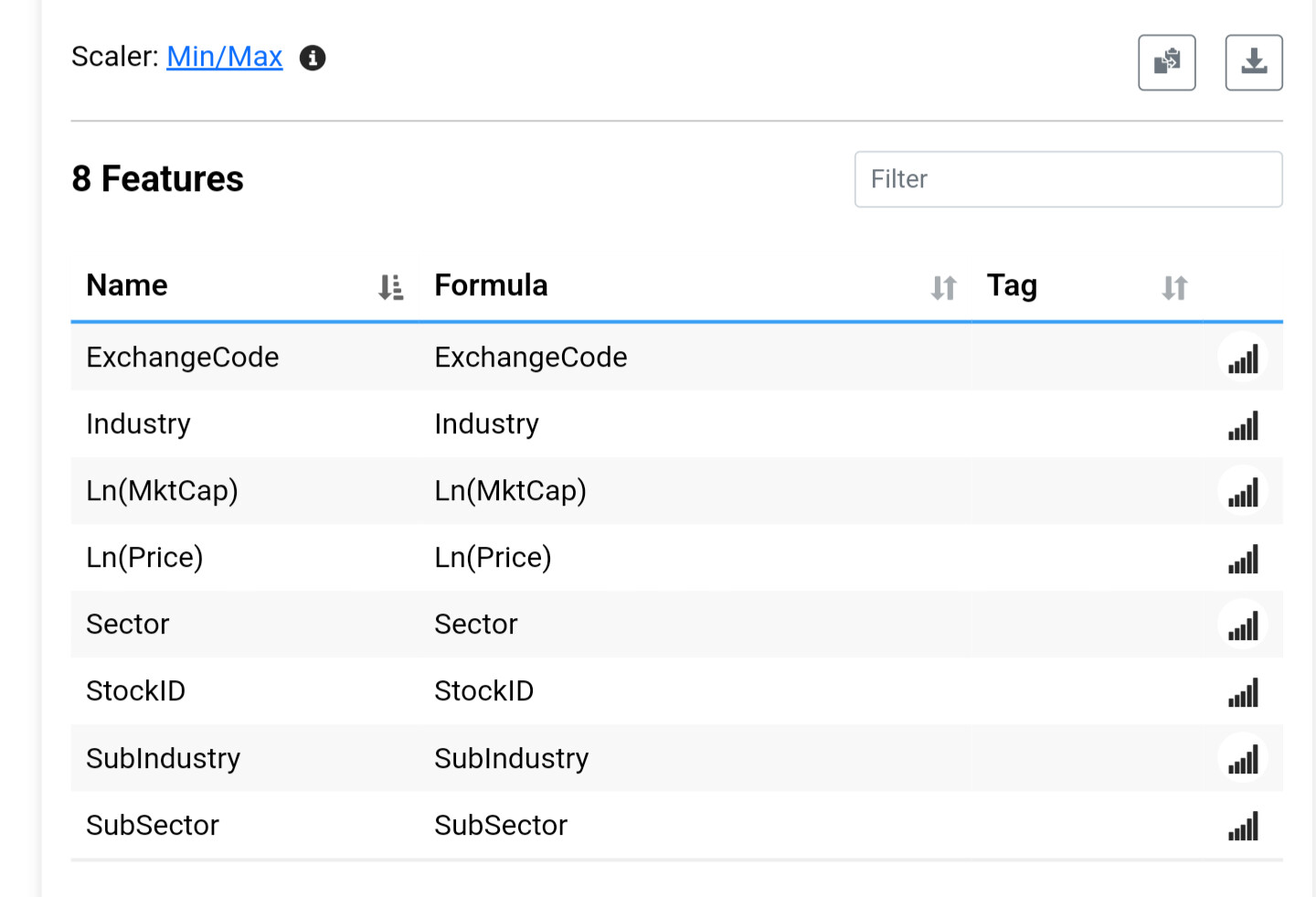
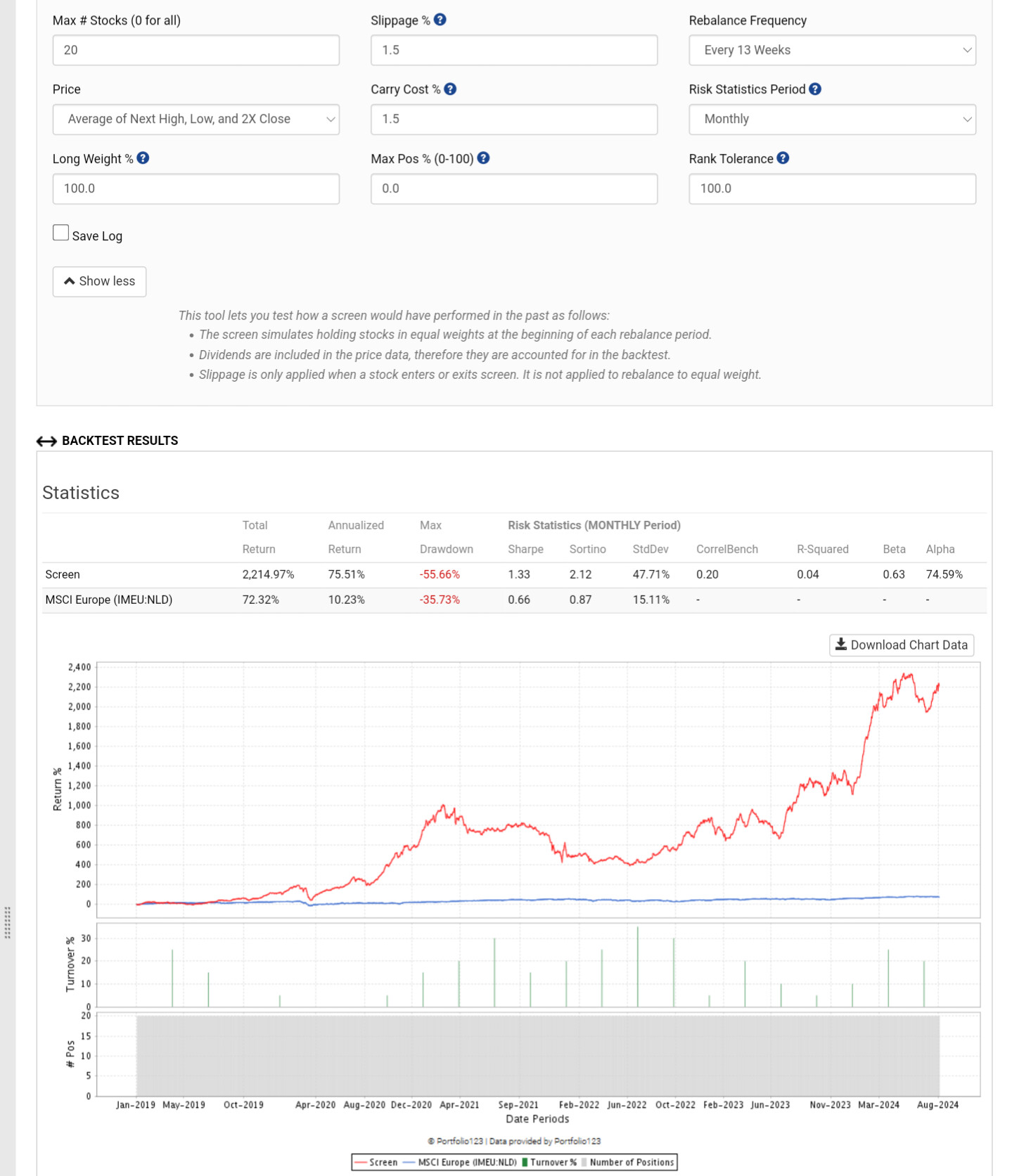
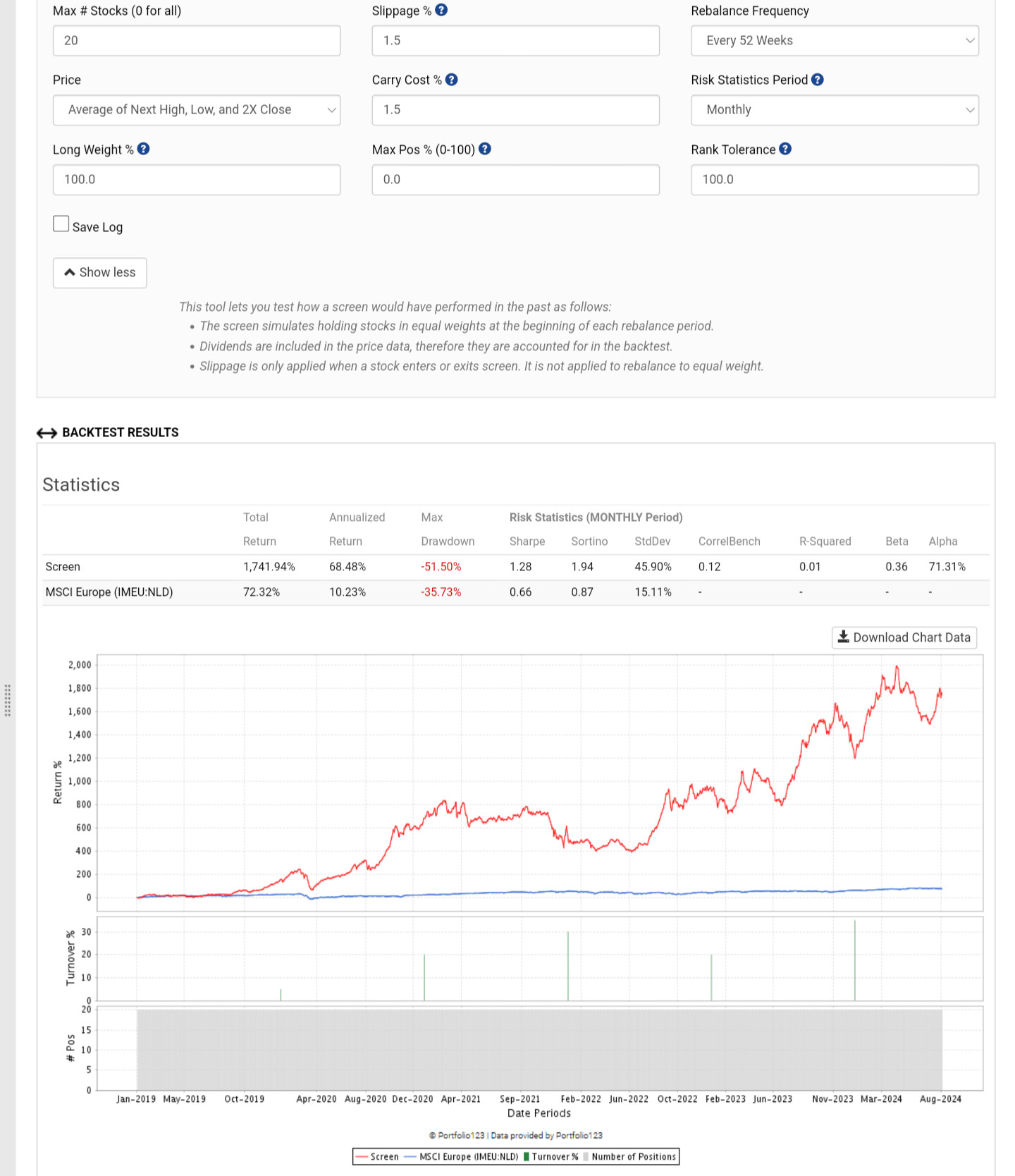
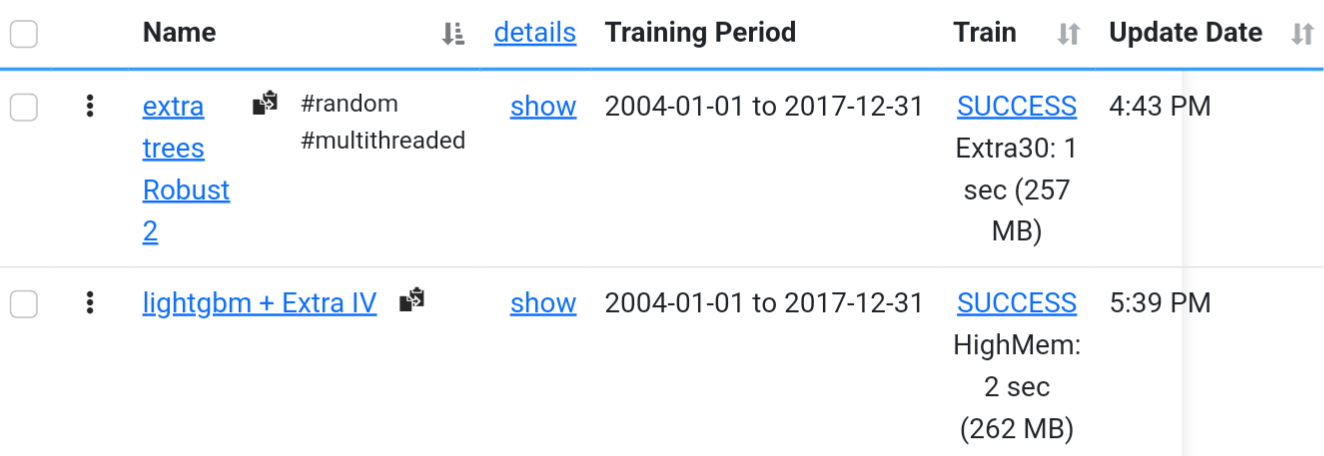
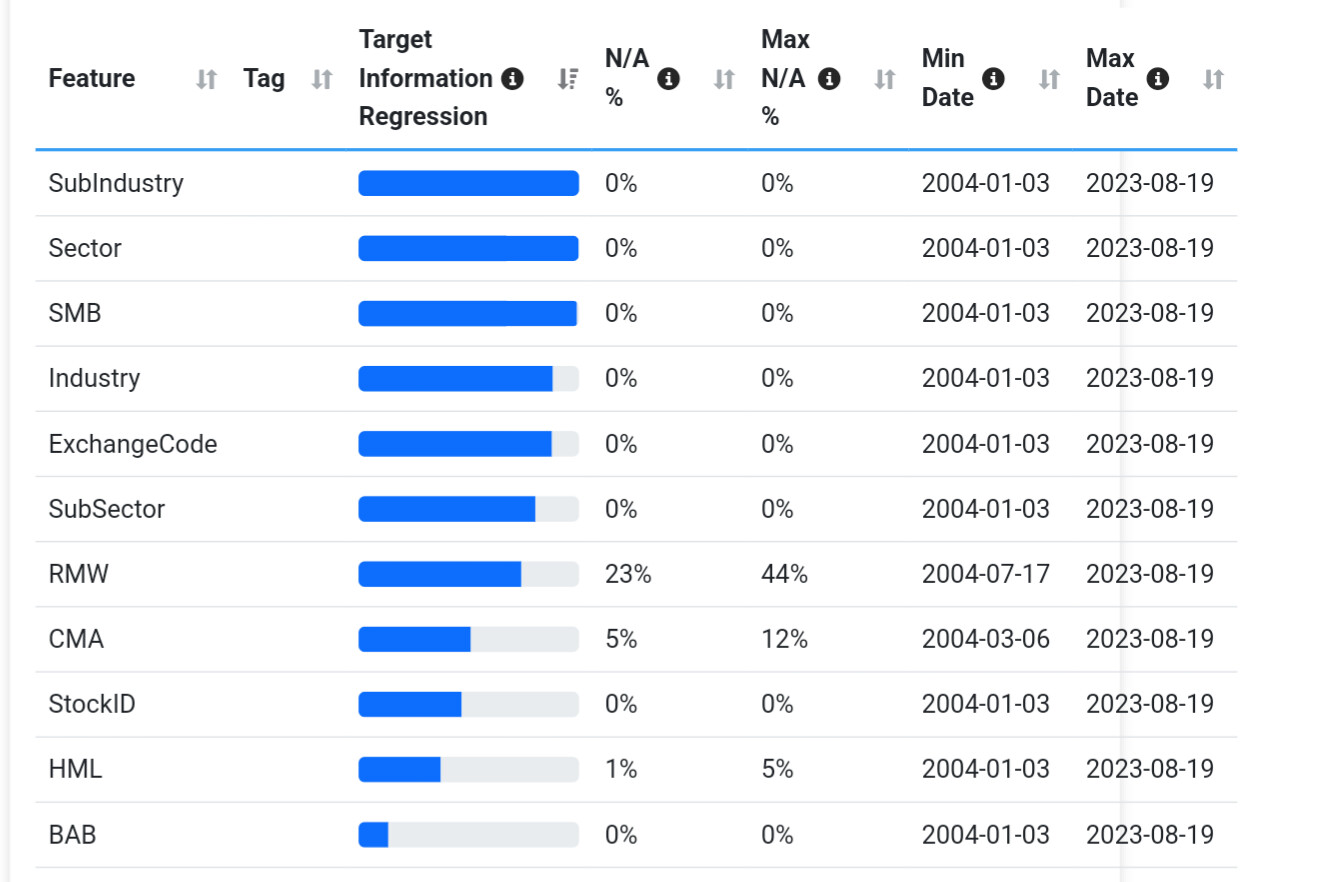
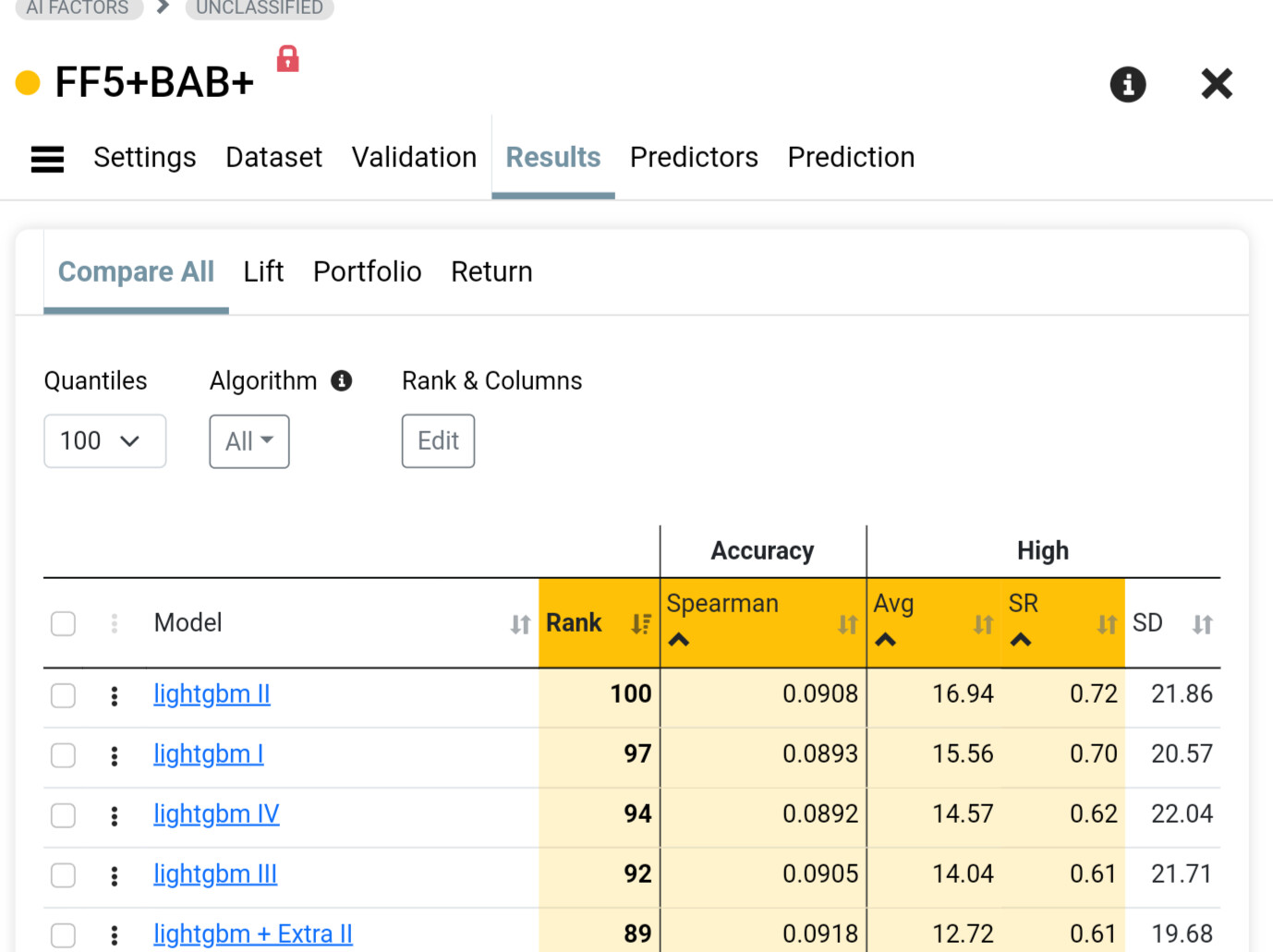
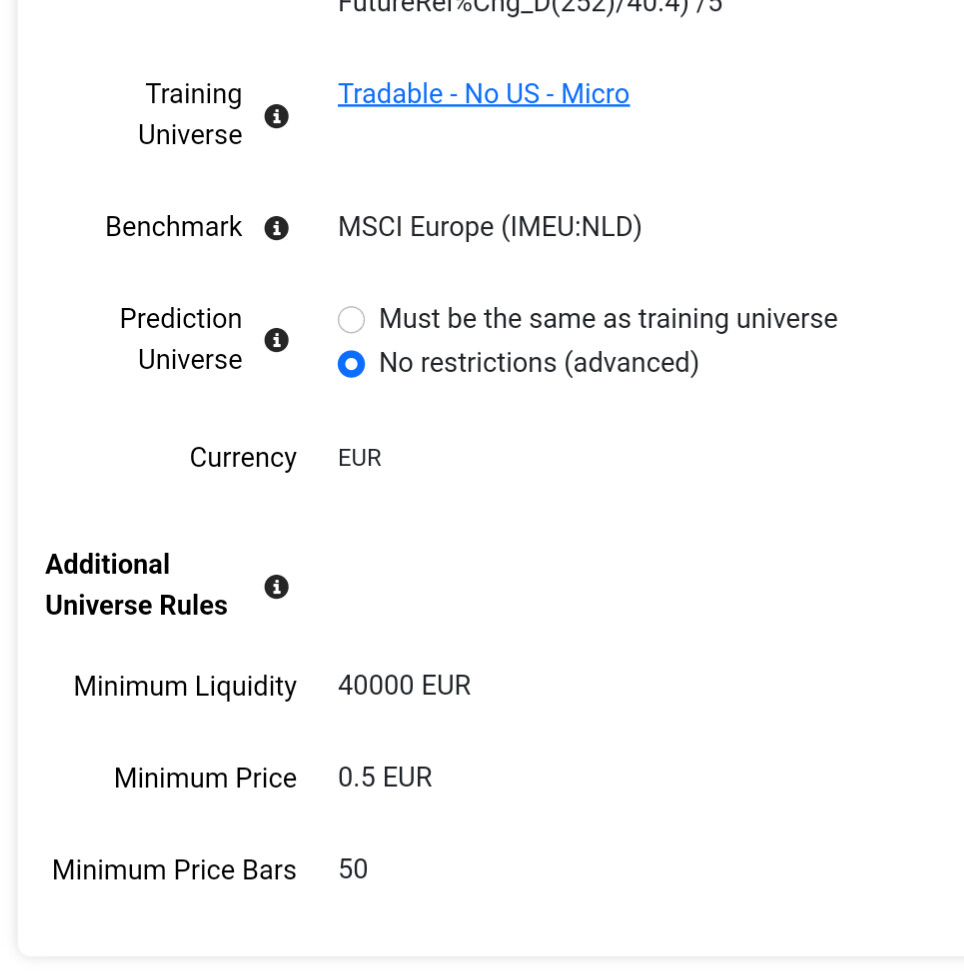
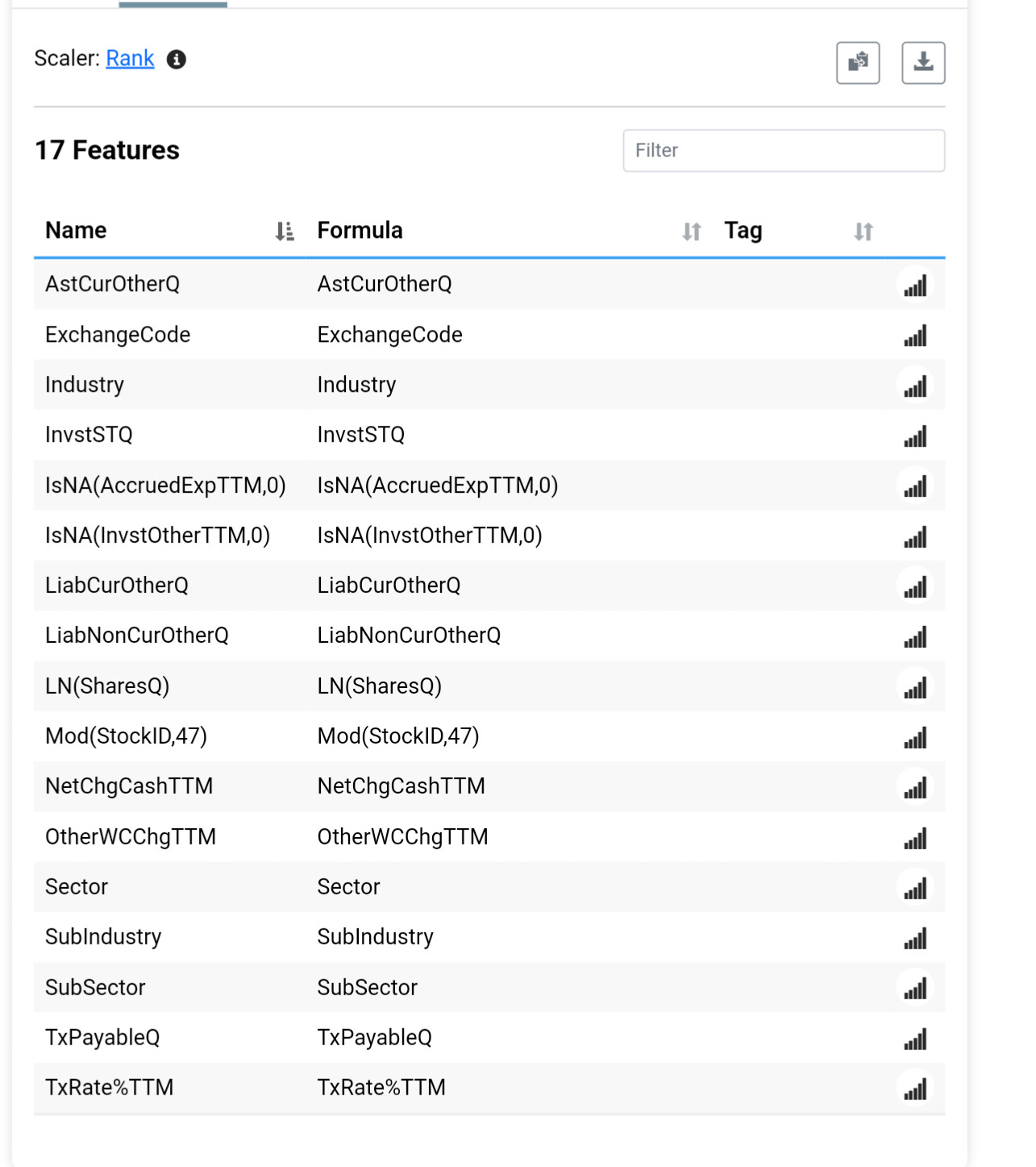
Several things don't make sense with your features. Most of them are categorical which is not supported at the moment. They are being scaled like any other factor. In addition you have StockId which is probably causing the model to really like certain stocks.
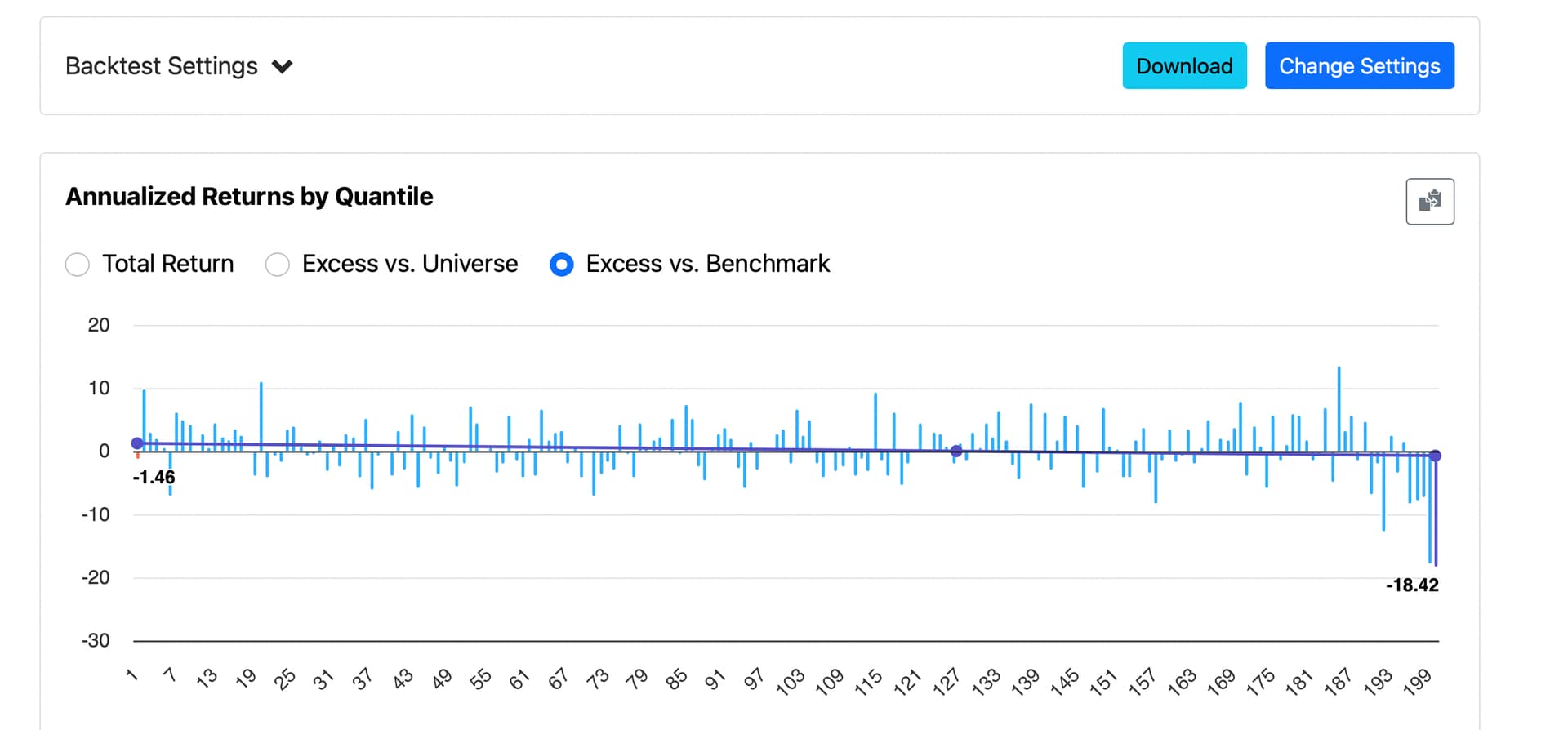
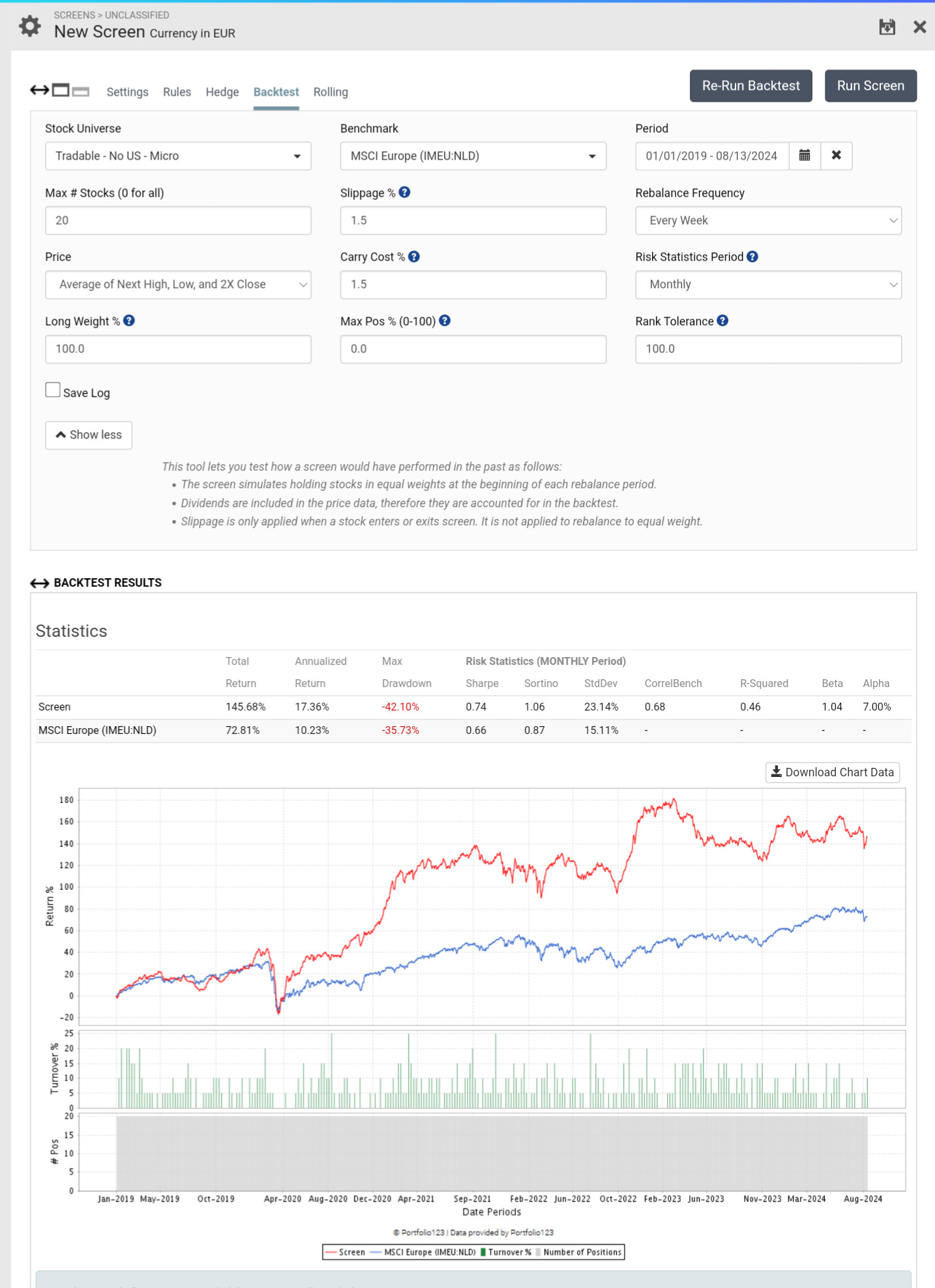
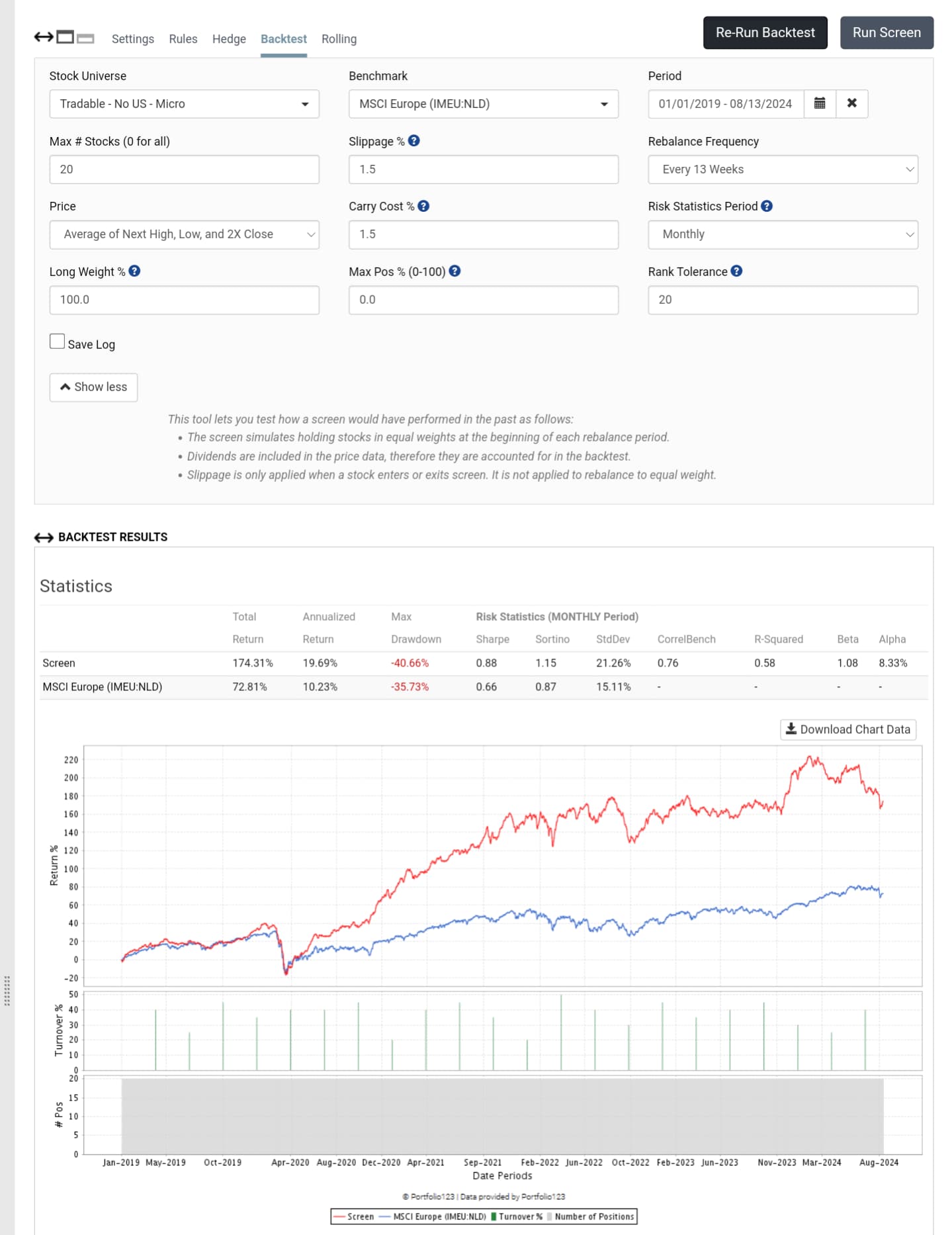
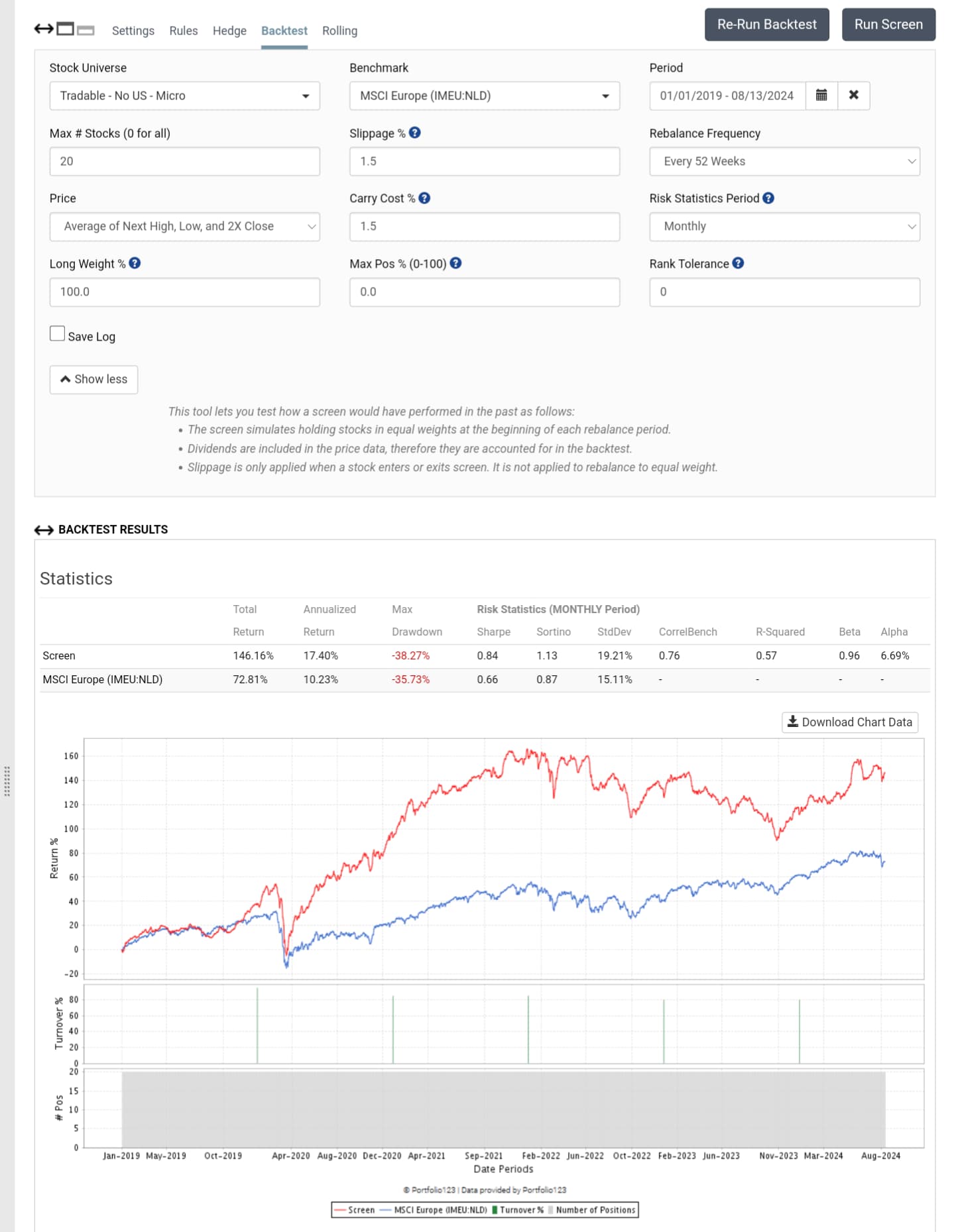
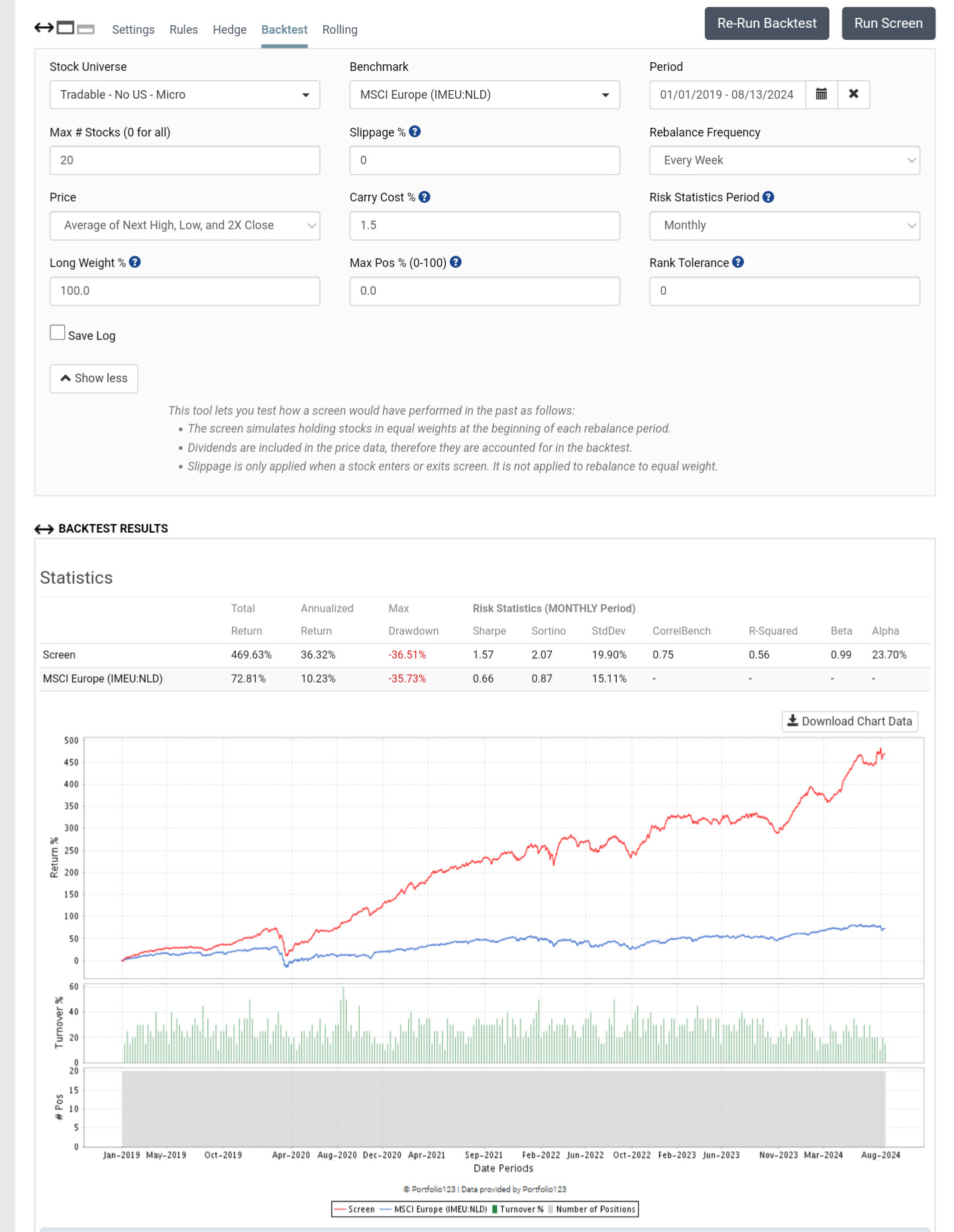
This is confirmed from the extremely low turnover, so changing the frequency won't change the results.
I've found before that these features surprisingly can be useful in some universes in another post, for some reason. However, I was shocked by this result
Cancel my initial thoughts on this. I can't understand how a stock id factor which as I understand it is just a number assigned when the initial stock was listed could work in any way especially if it went through typical Z or Min/max preprocessing could be of any use.
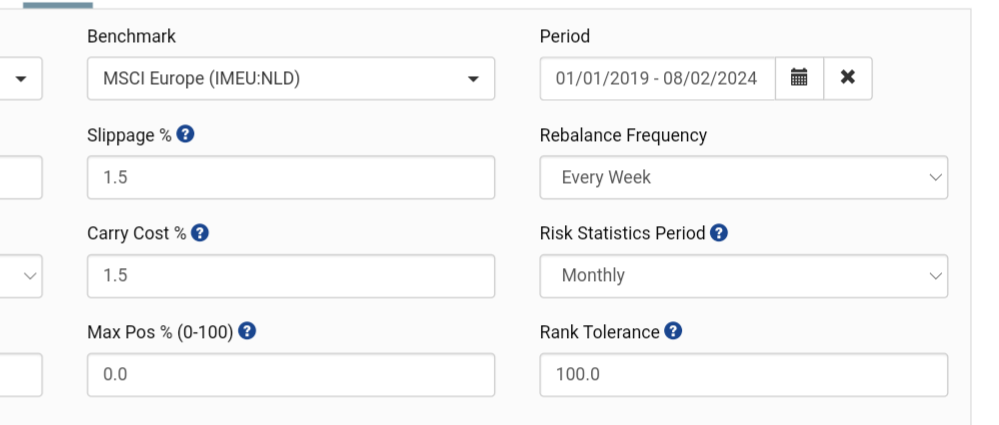
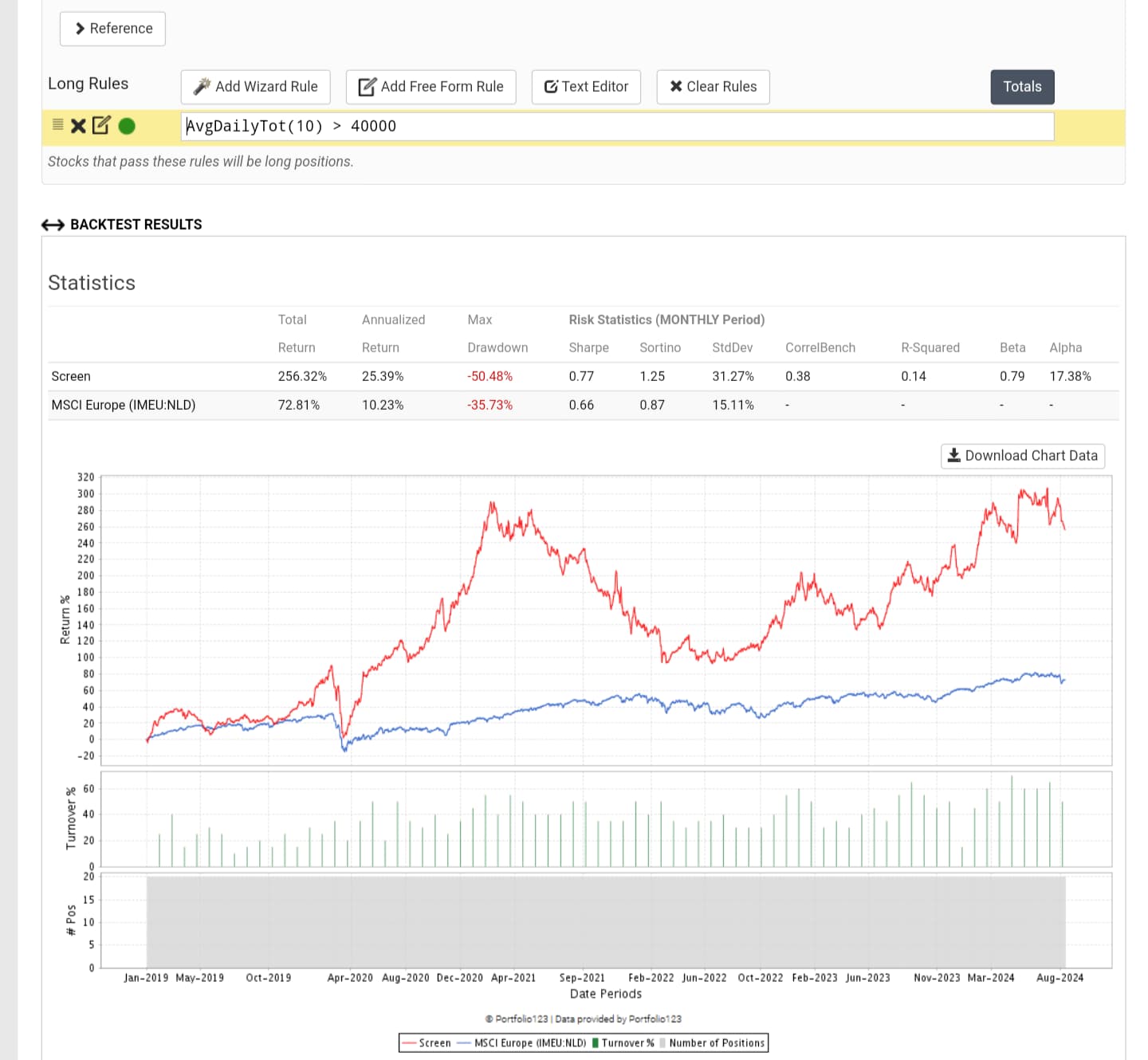
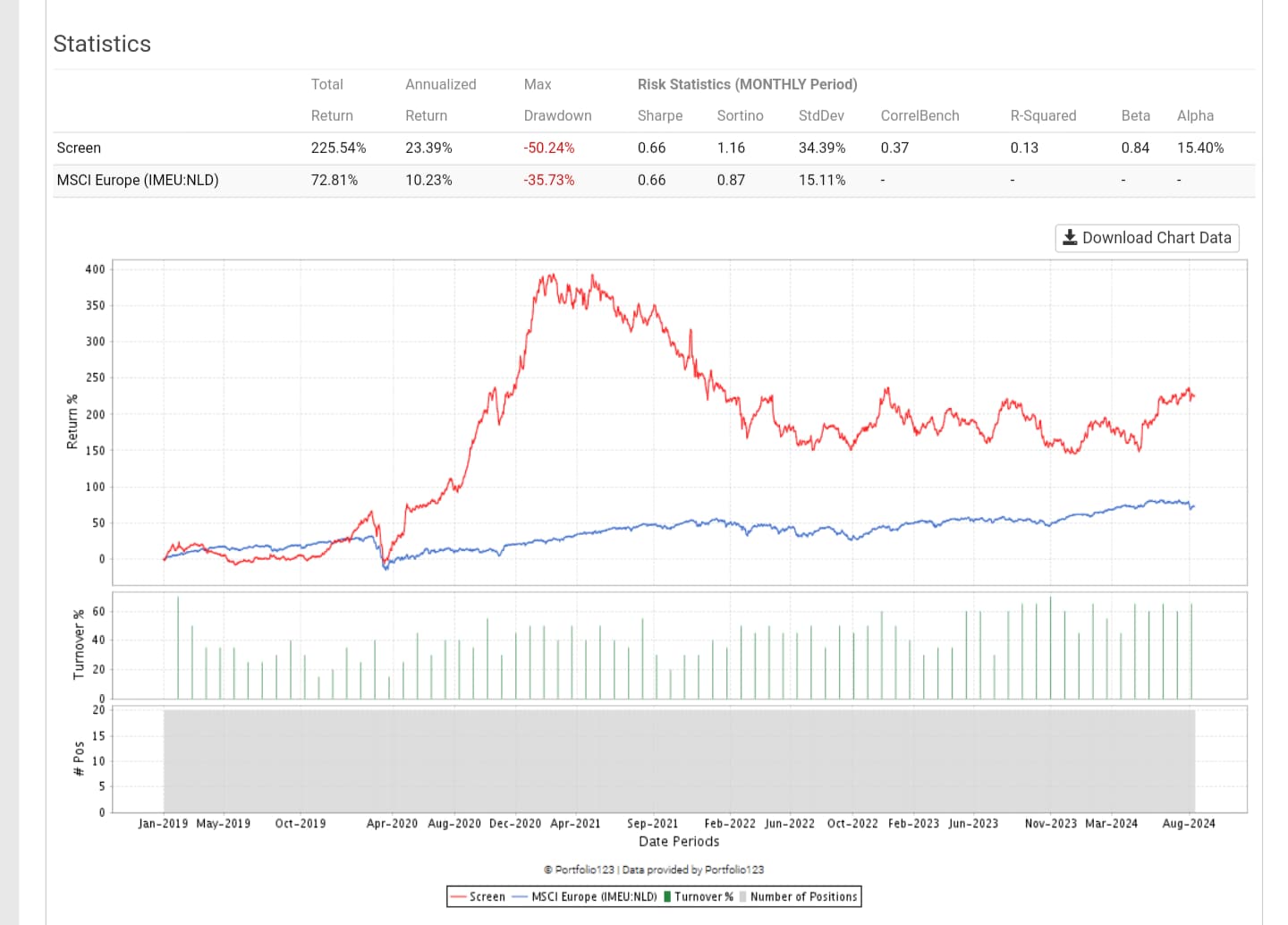
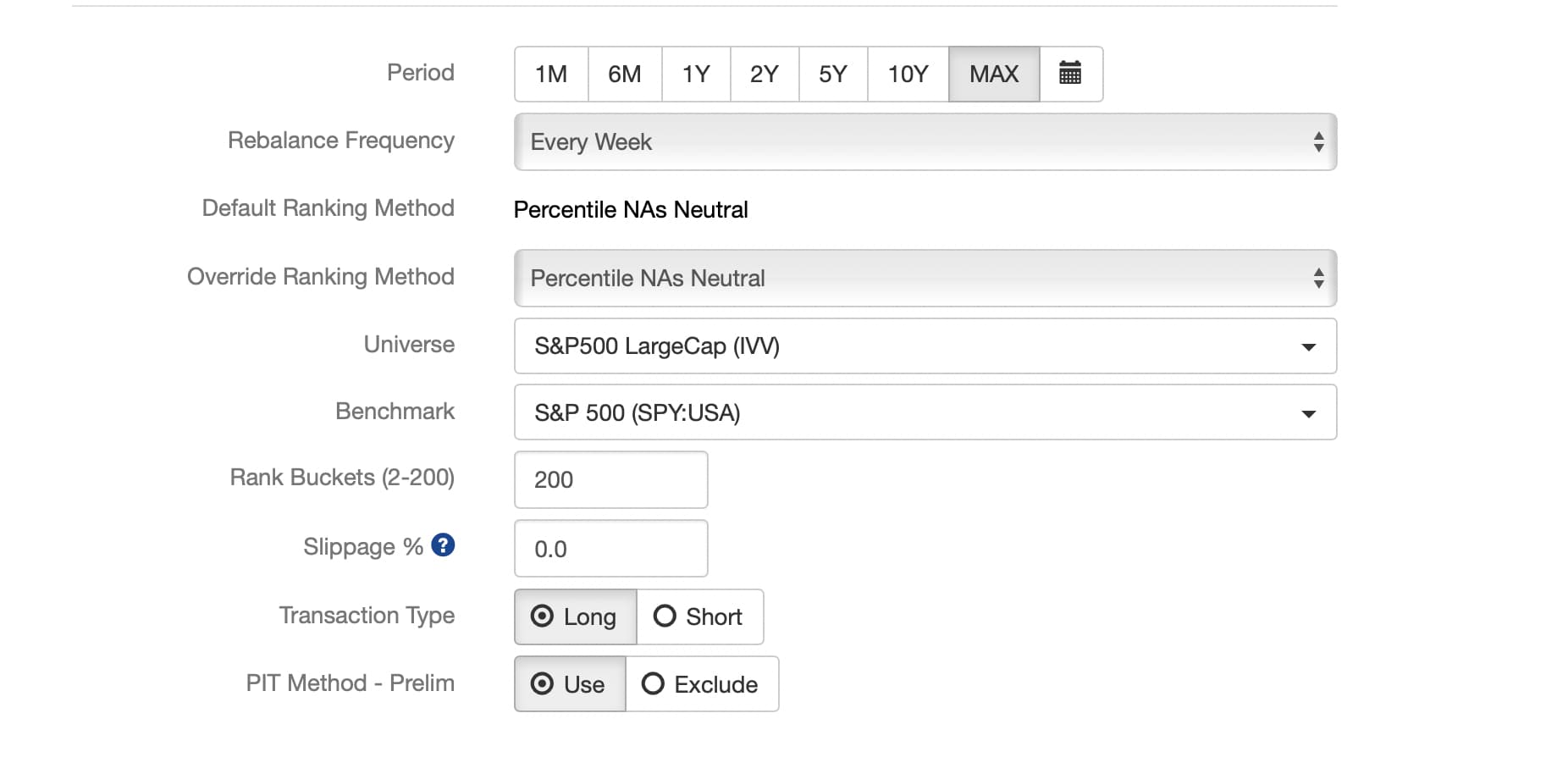
I had deleted the universe and the AI factors so I rebuild a less illiquid universe with stocks listed in the US (the former exclude those stocks) and the results would be somewhat different (e.g. the turnovers are higher and the returns are lower now)
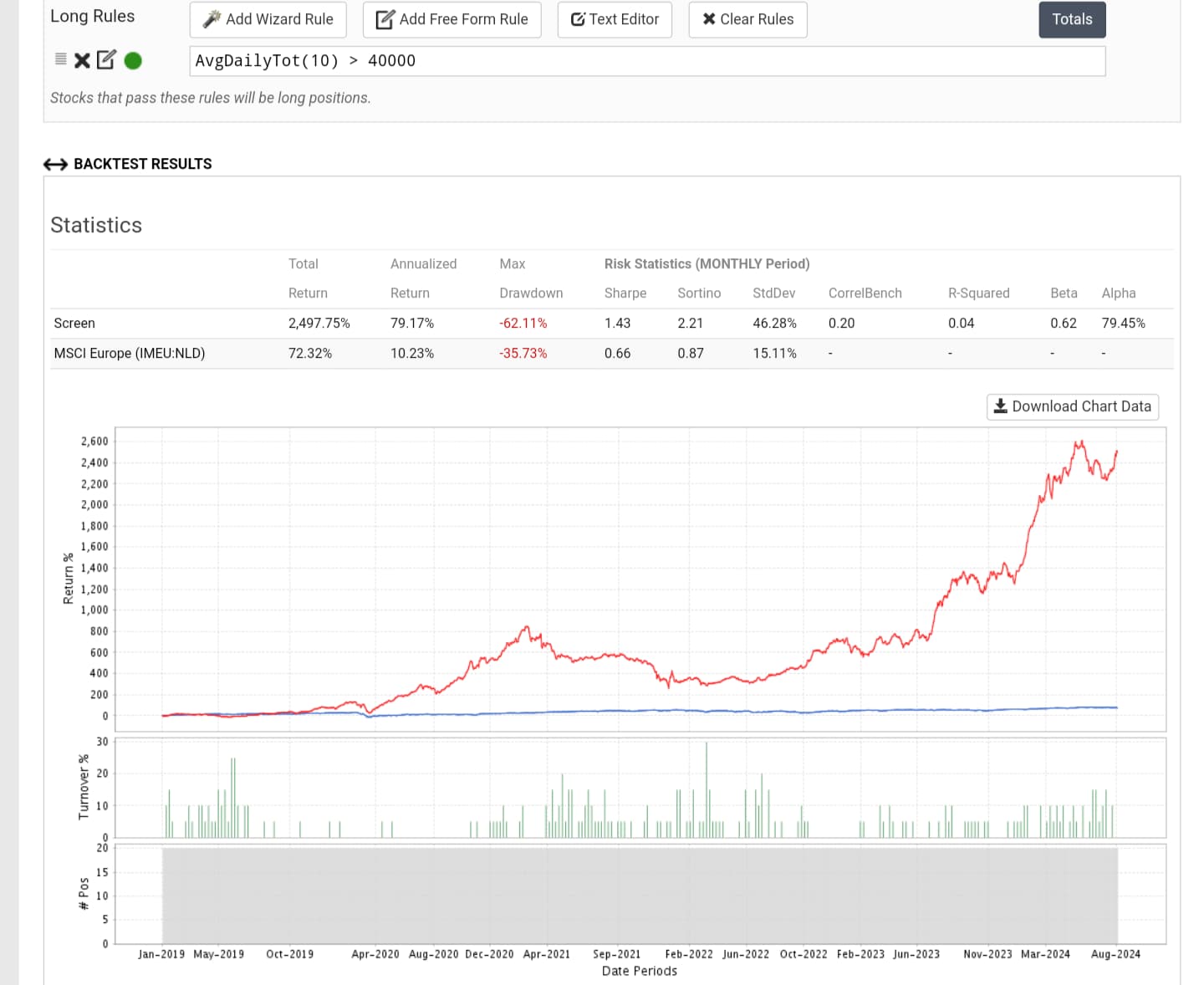
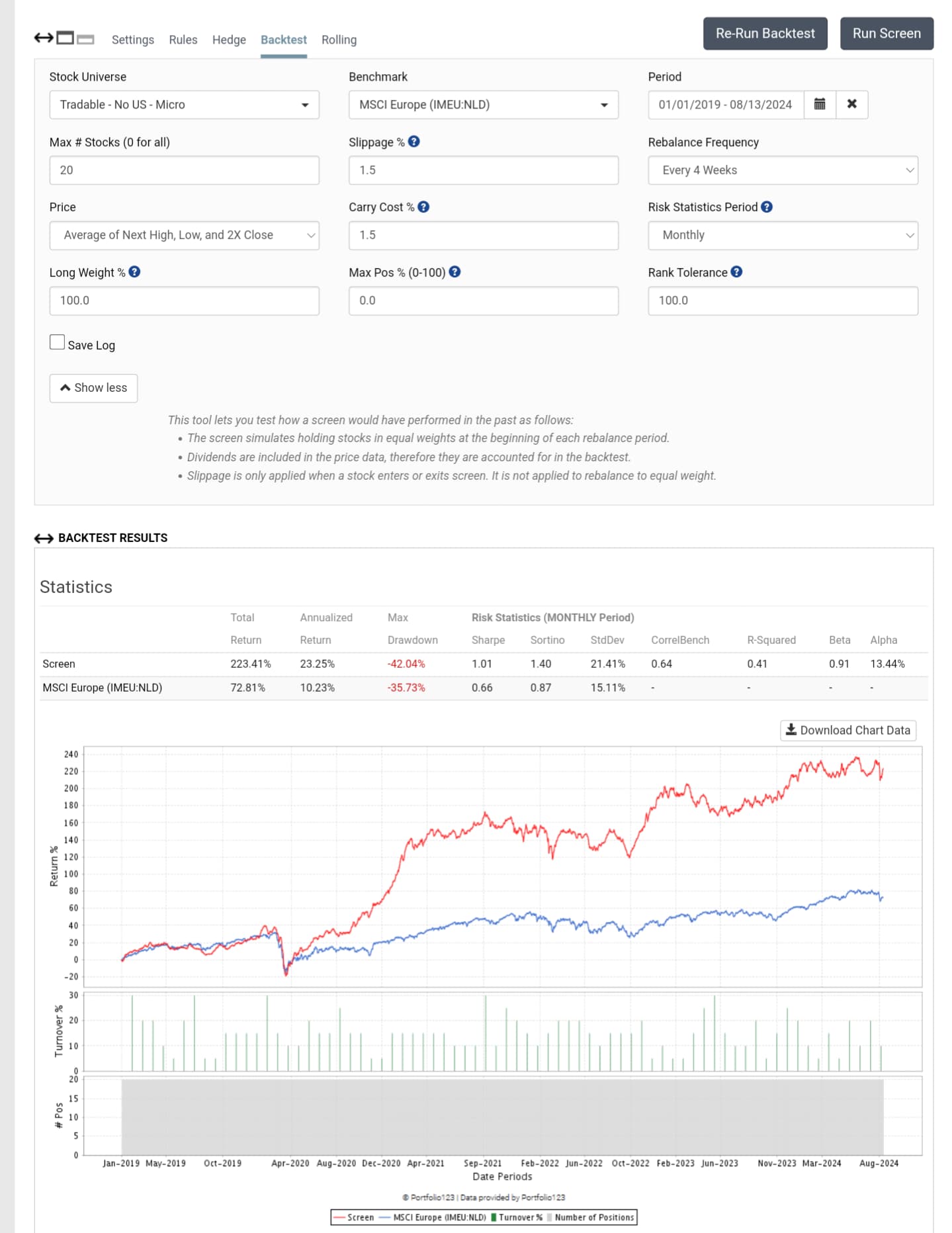
Even with a narrower (about 1/5) and harder-to-profit training universe and therefore much increased share turnover, it is still possible to generate excess returns under Rank and with conservative trading costs if the screen feature isn't broken and there is no data leakage
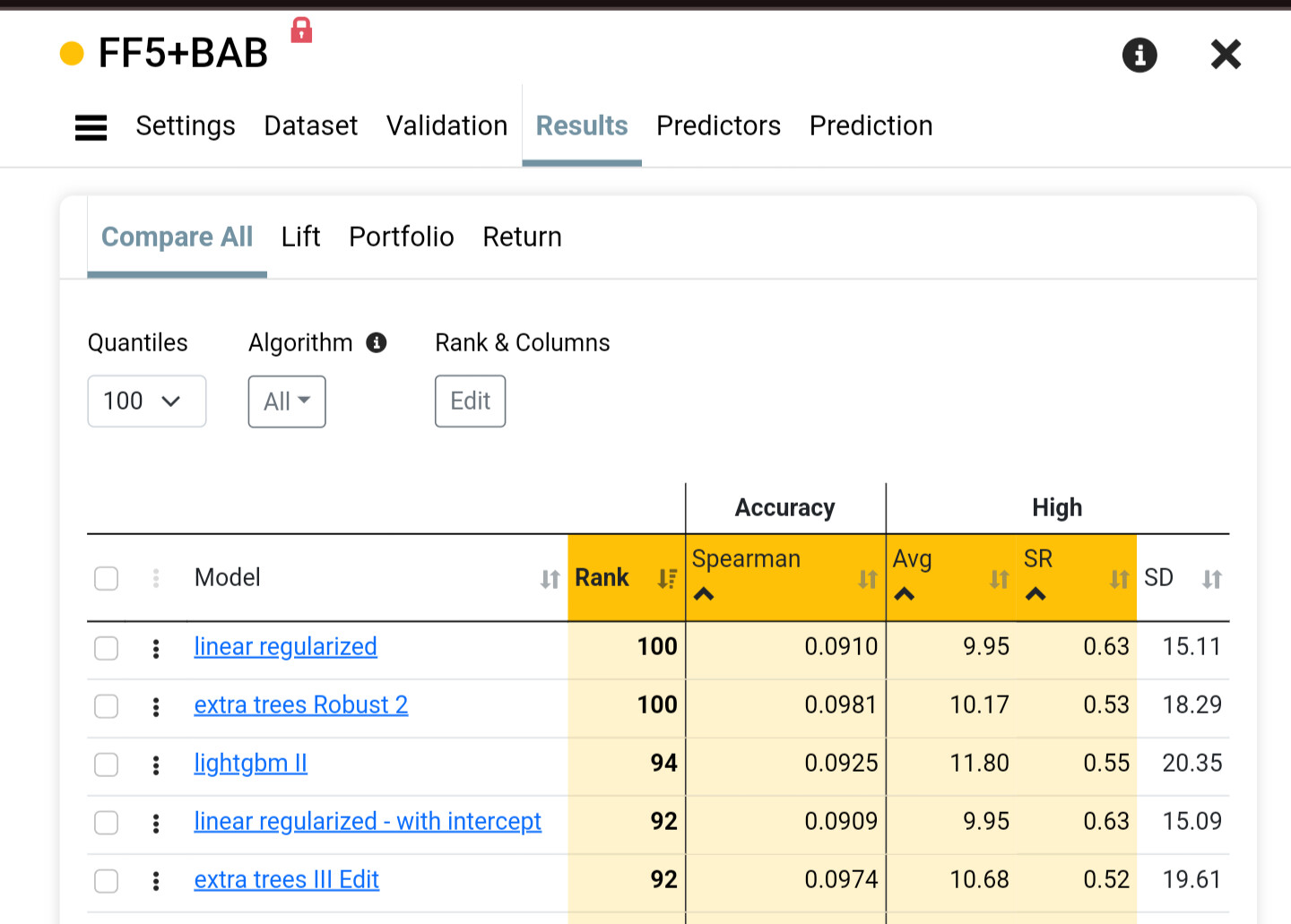
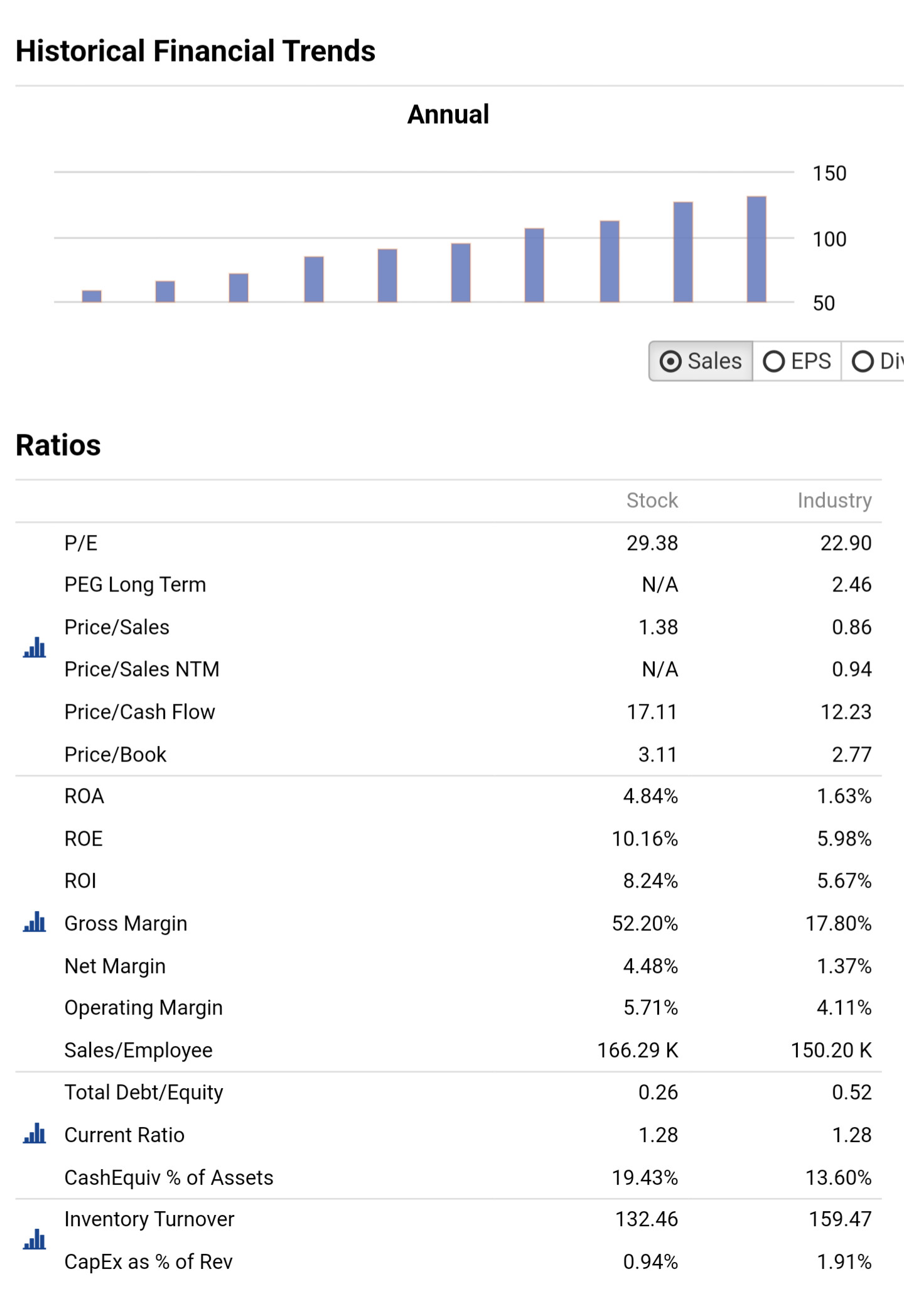
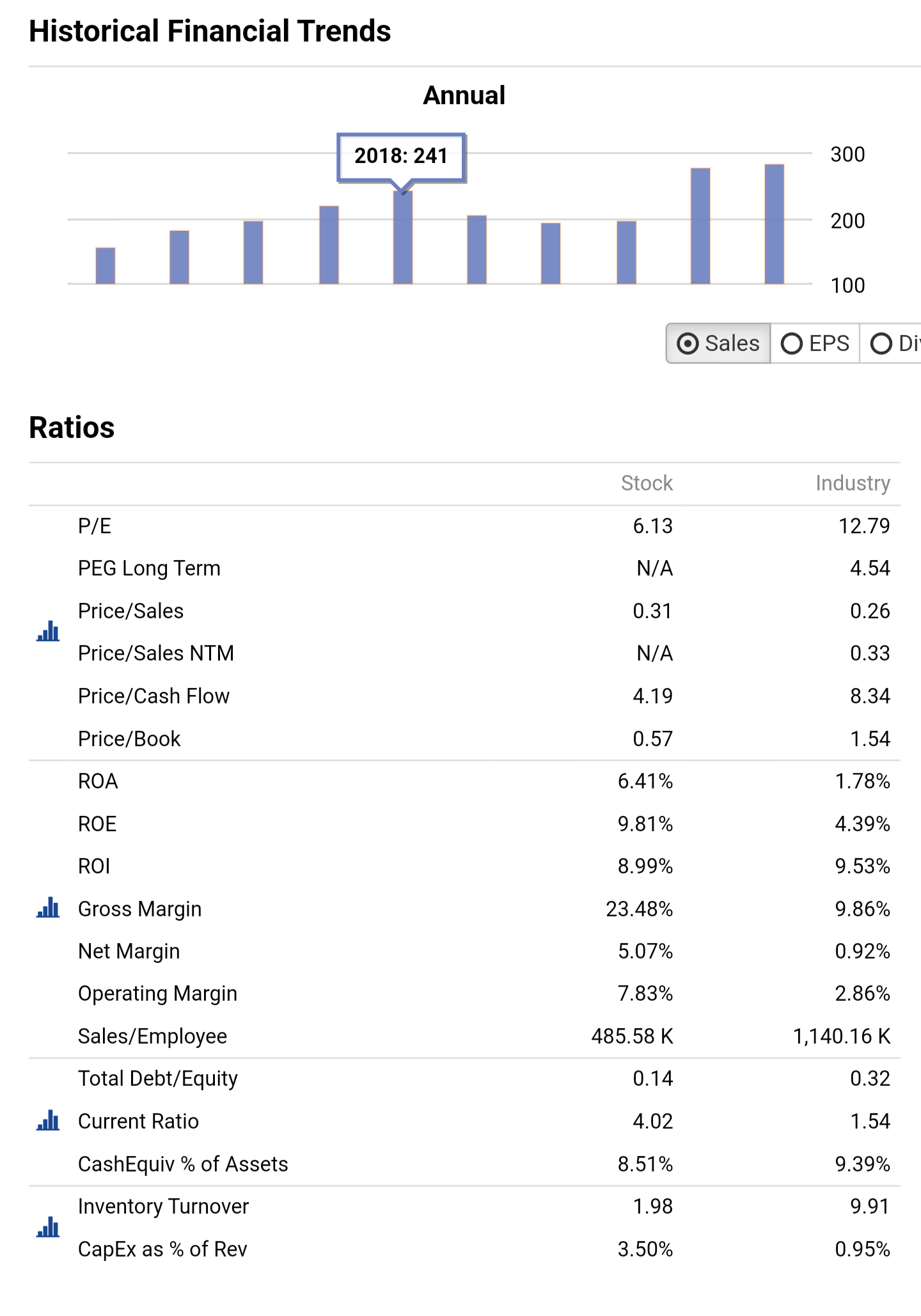
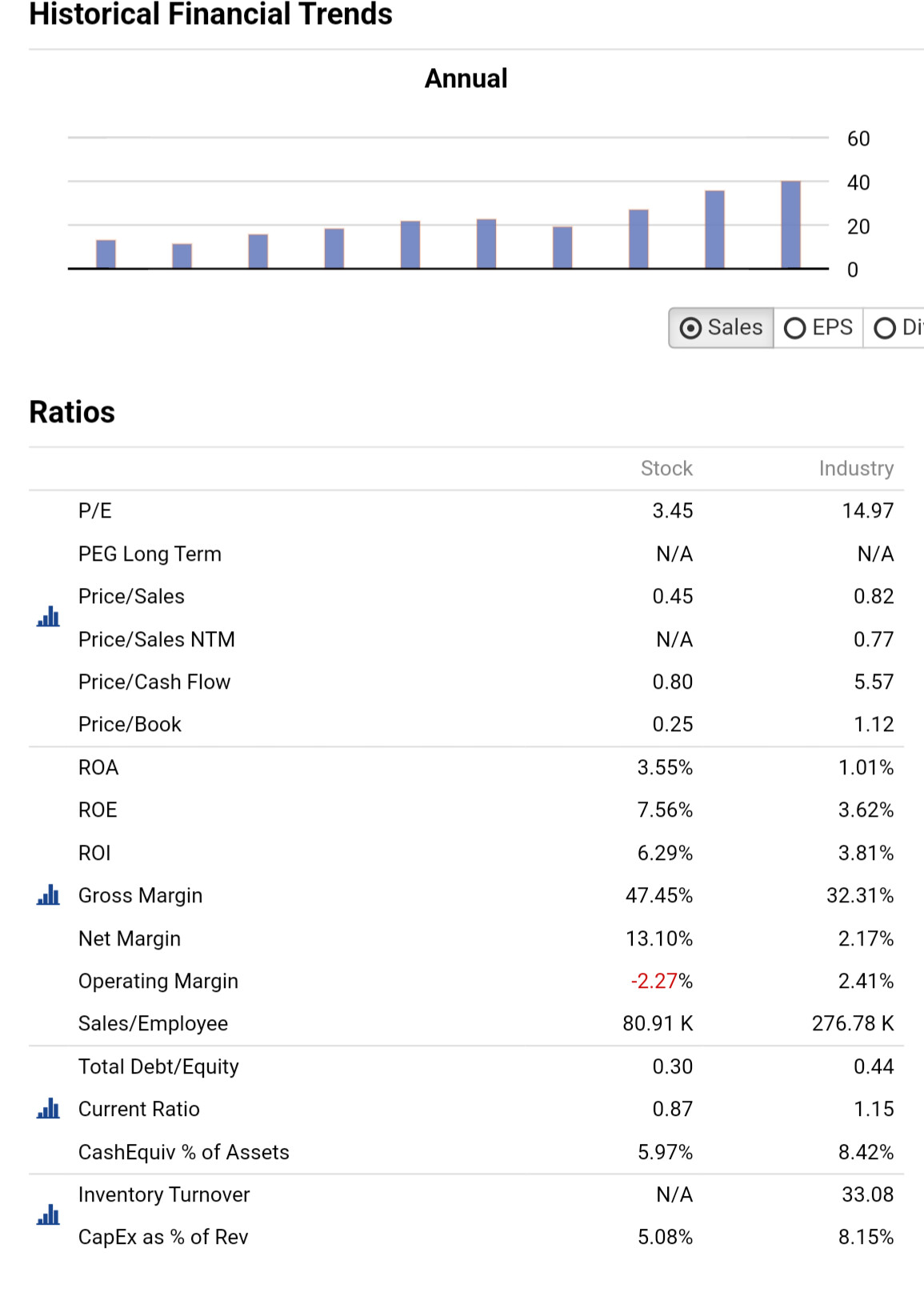
When cmparing models trained in the same North Atlantic universe, the same Min/Max by Date preprocessor, the same period and the same validation method,
BTW according to Claude 3 on my question of IPO survival rates. "Research has shown that new IPOs do indeed have a higher risk of failure or underperformance"
So just trying to gather information with a rank performance test.
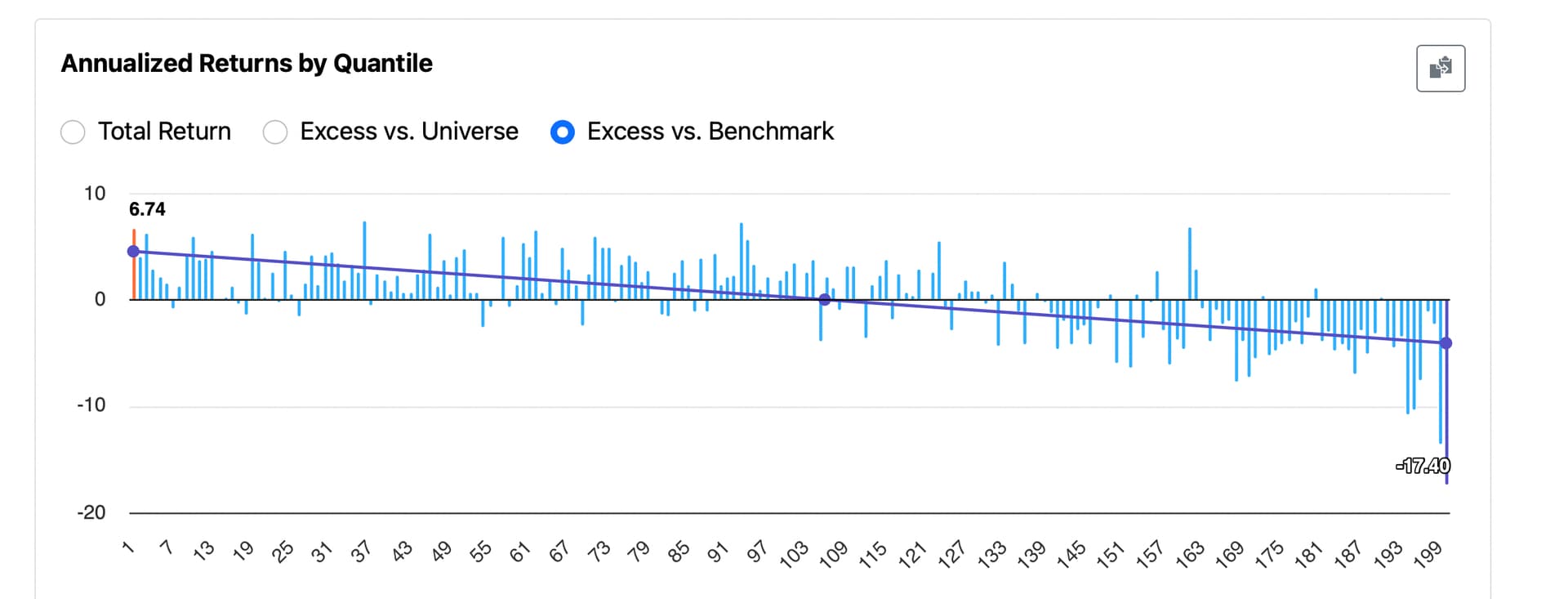
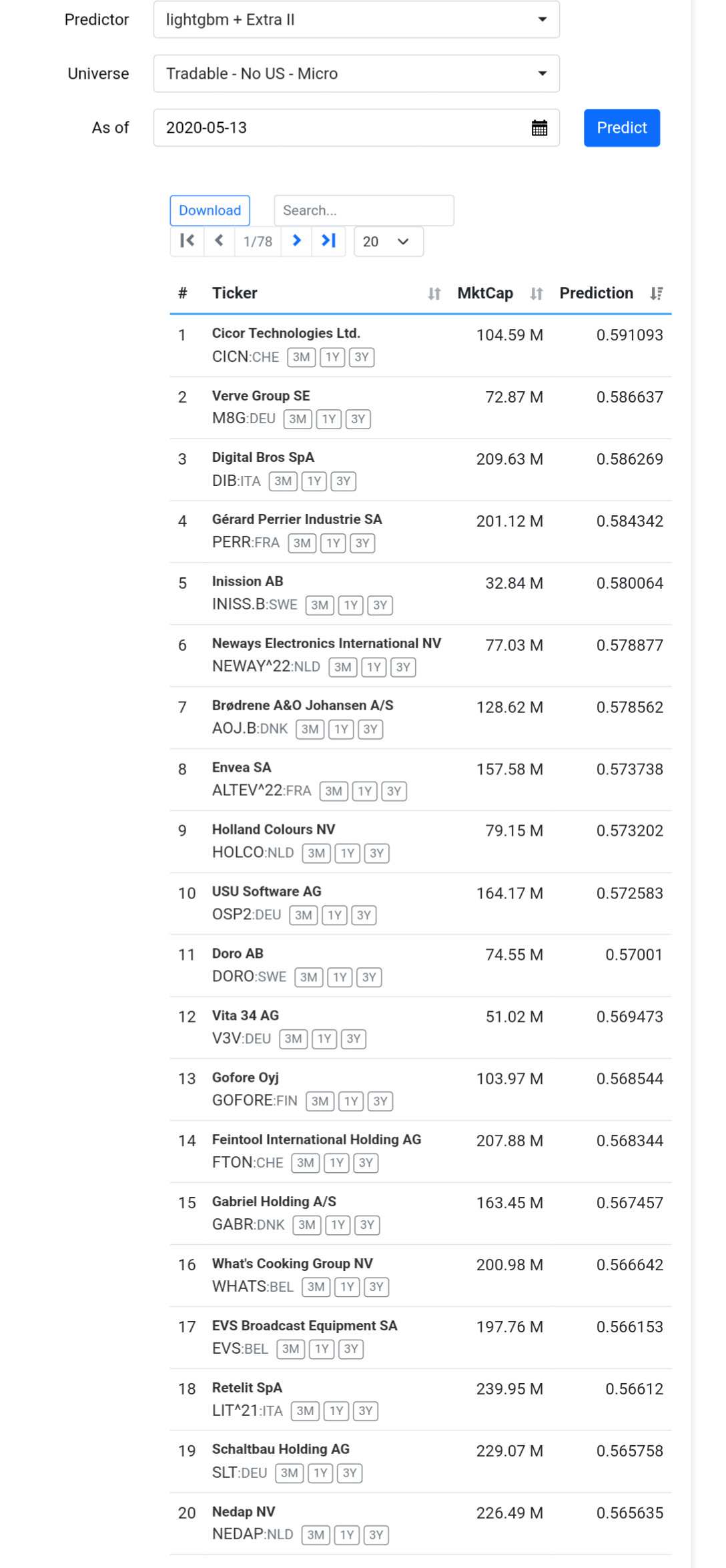
Seems random except for last buckets. StockID is not entirely random, correct? Higher numbers are newer additions? IPOs not too long ago? Not sure how long ago but the ML algorithm has the power to optimize the split. And the buckets suggest the top bucket (absolute newest) does the worst but that this effect persists for a while (at least 4 buckets).
The random forest ((or LightGBM) ranking system would tend to exclude band-new additions in a sim or screen if each new stock is given a higher number (lower ones already taken)?
My explanation is just a theory that may be falsified (or made less credible by a more plausible theory) in this forum with a later post. But for sure StockID is not as random as we thought or there is data leakage:
Try modularizing StockID. In other words, hide StockID as input and use only Mod(StockID,100) or Mod(StockID, 47). This will protect you from the IPO/recency effect. I can't imagine even the smartest machine being able to leverage Mod(StockID,47).
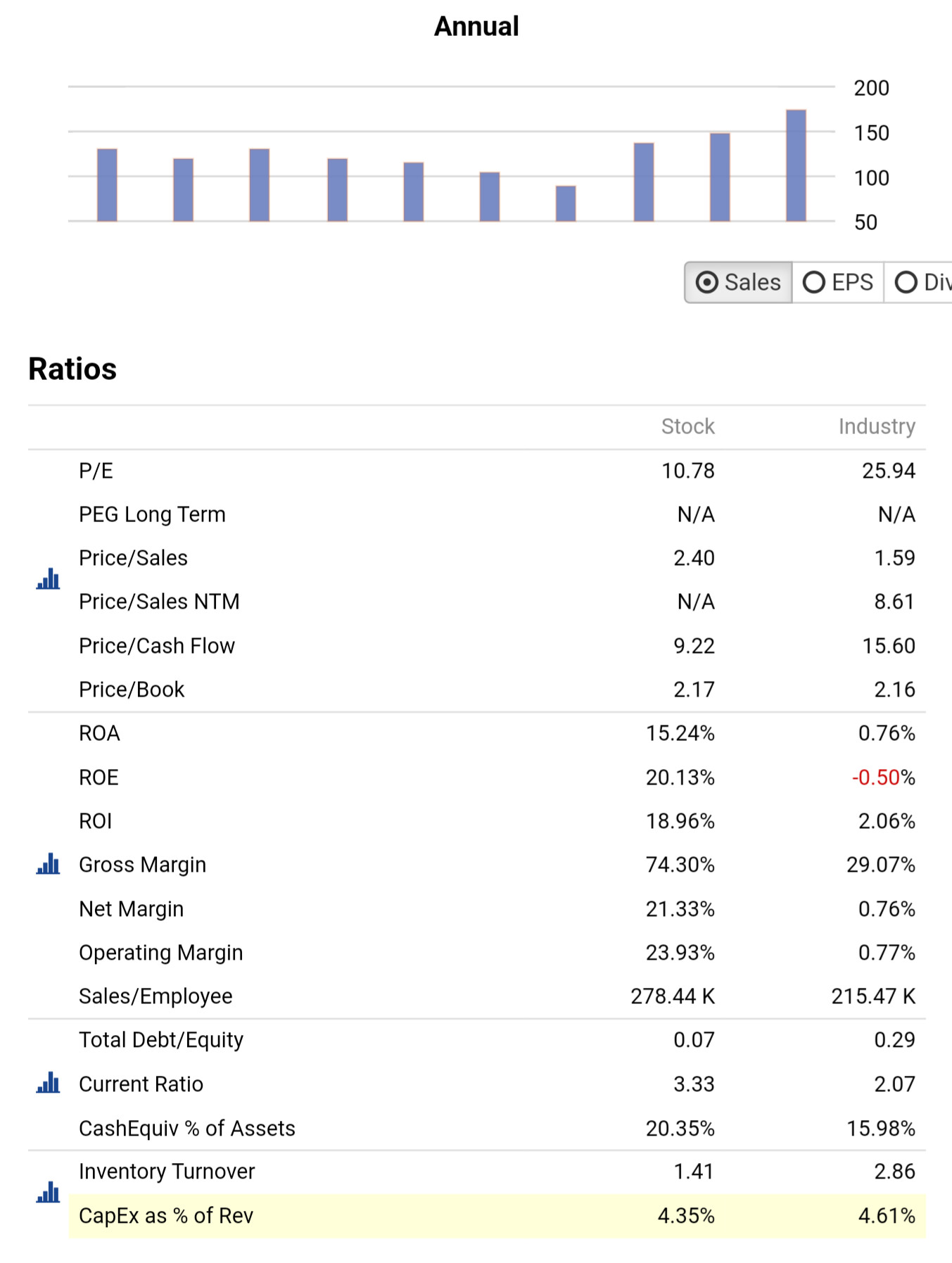
Combining industry/sector and price gives exposure to industry/sector momentum, which is an extremely powerful factor. If you really want to test for lookahead bias I propose using a bunch of fundamentals that don't really add up to anything, e.g. TxRate%, InvstST, AstCurOther, InvstAdvOther, TxPayable, LiabCurOther, LiabNonCurOther, Shares, AccruedExp, OtherWCChg, InvstOther, and NetChgCash. I would guess that any soup made up of those factors would have no persistency whatsoever.
Momentum too is a powerful factor, so excluding price and market cap might be in order if you're testing for lookahead bias. Alternatively, Price - Trunc(Price) might be useful if you can hide the price.
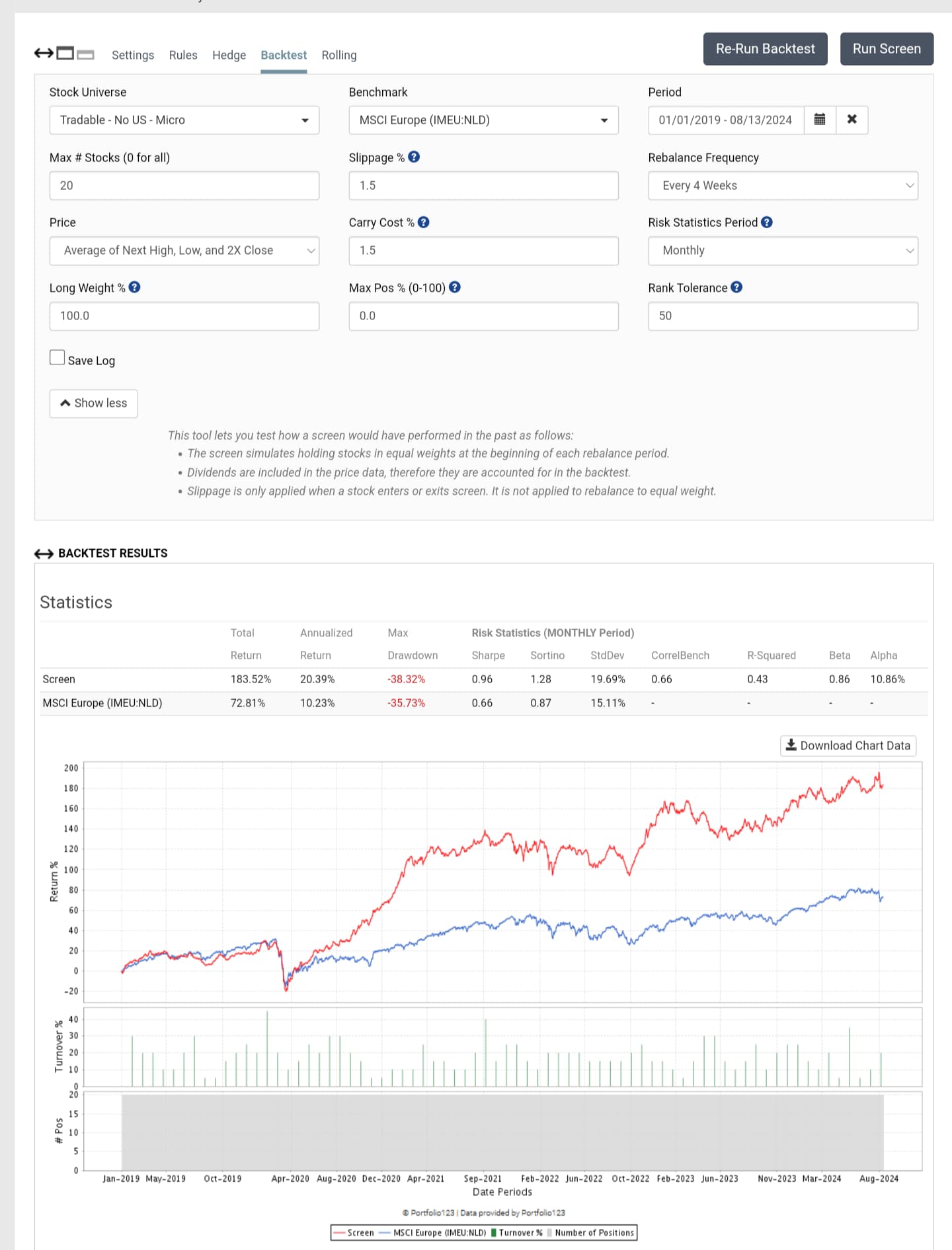
With rank tolerance set at 100% you're only selling stocks if they fall afoul of your screen or universe rules. Your ranking system is doing very little except choosing the initial 20 stocks and replacing the few that fall afoul of your rules.