If you had an EBM app how would you use it? Personally, I would not fund an EBM model now. Maybe in the future if I learn more about them but not now.
Are EBMs better thought of as discovery tools (because of their transparency) rather than final production models for now? How would you use them with P123?
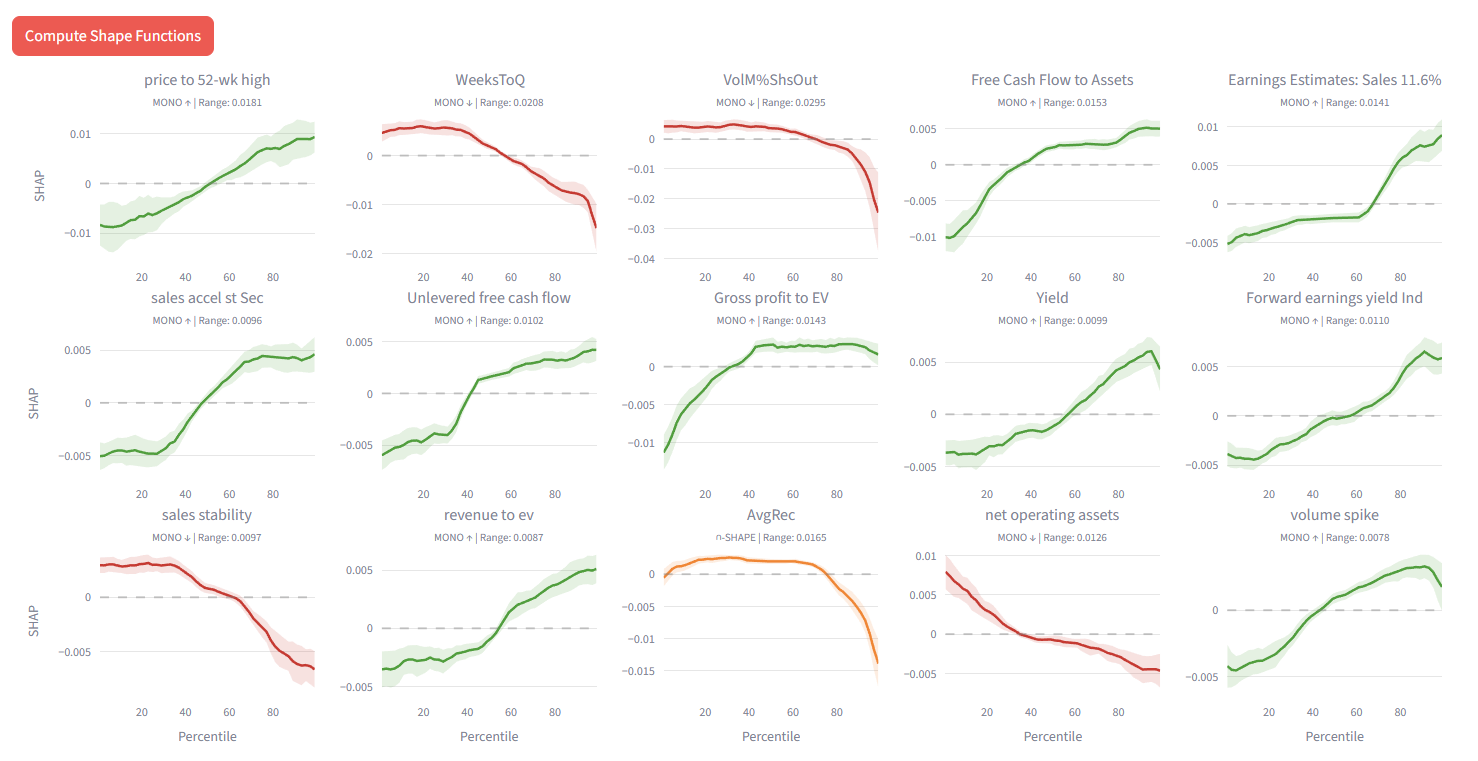
Maybe used with P123’s LightGBM for increased transparency? To search for interactions and anomalies? Maybe as part of a fundamental deep dive? To red-flag unusual situations or anomalies (like the Value Gap Anomaly) affecting a particular stock?
To screen new features to see if they might interact with your core features in a negative way? If pairwise interactions do not show up for that feature that may not be a problem. If an interaction shows up maybe that can be explored with EBM Shape curves and other methods. 3D visualizations as part of any app?
If you had this as an app with P123’s AI 2.0 what would you want to see? How would you use it?
Here are some additional Claude ideas:
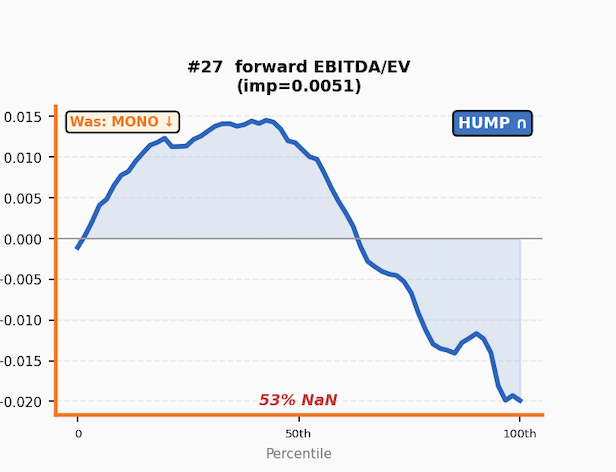
Regime monitoring. Train on rolling windows, watch shapes evolve.
Create composite interaction nodes in P123
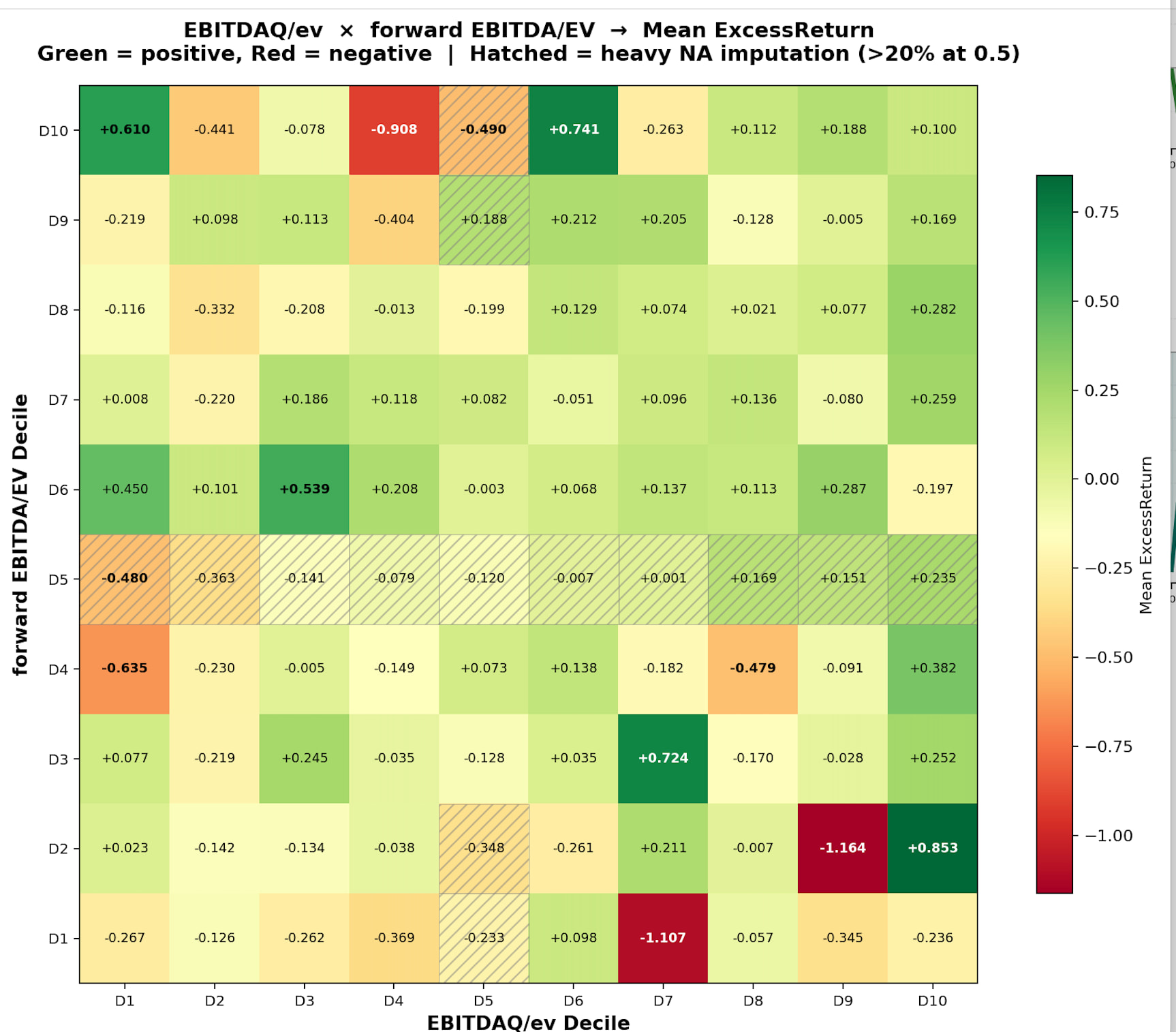
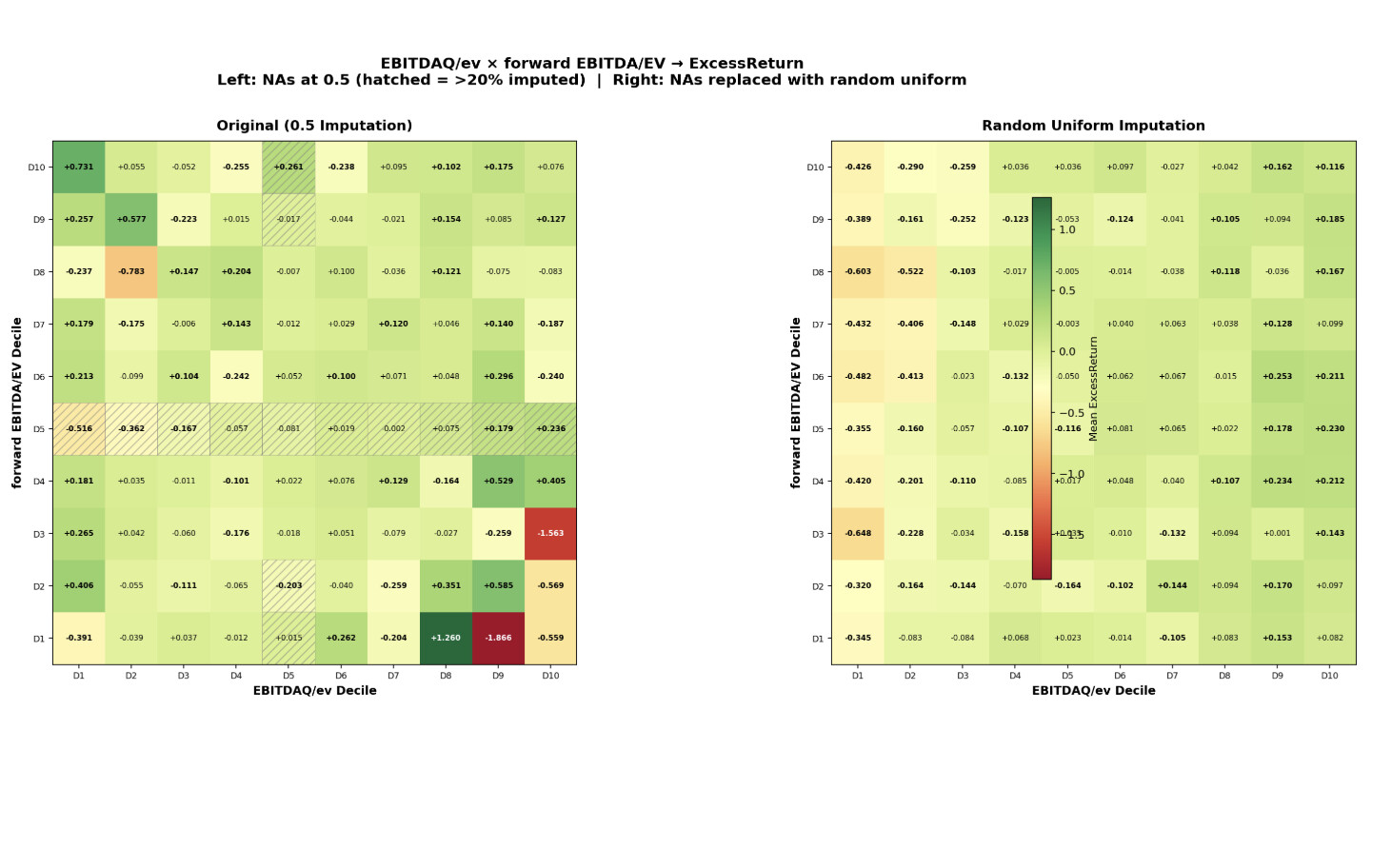
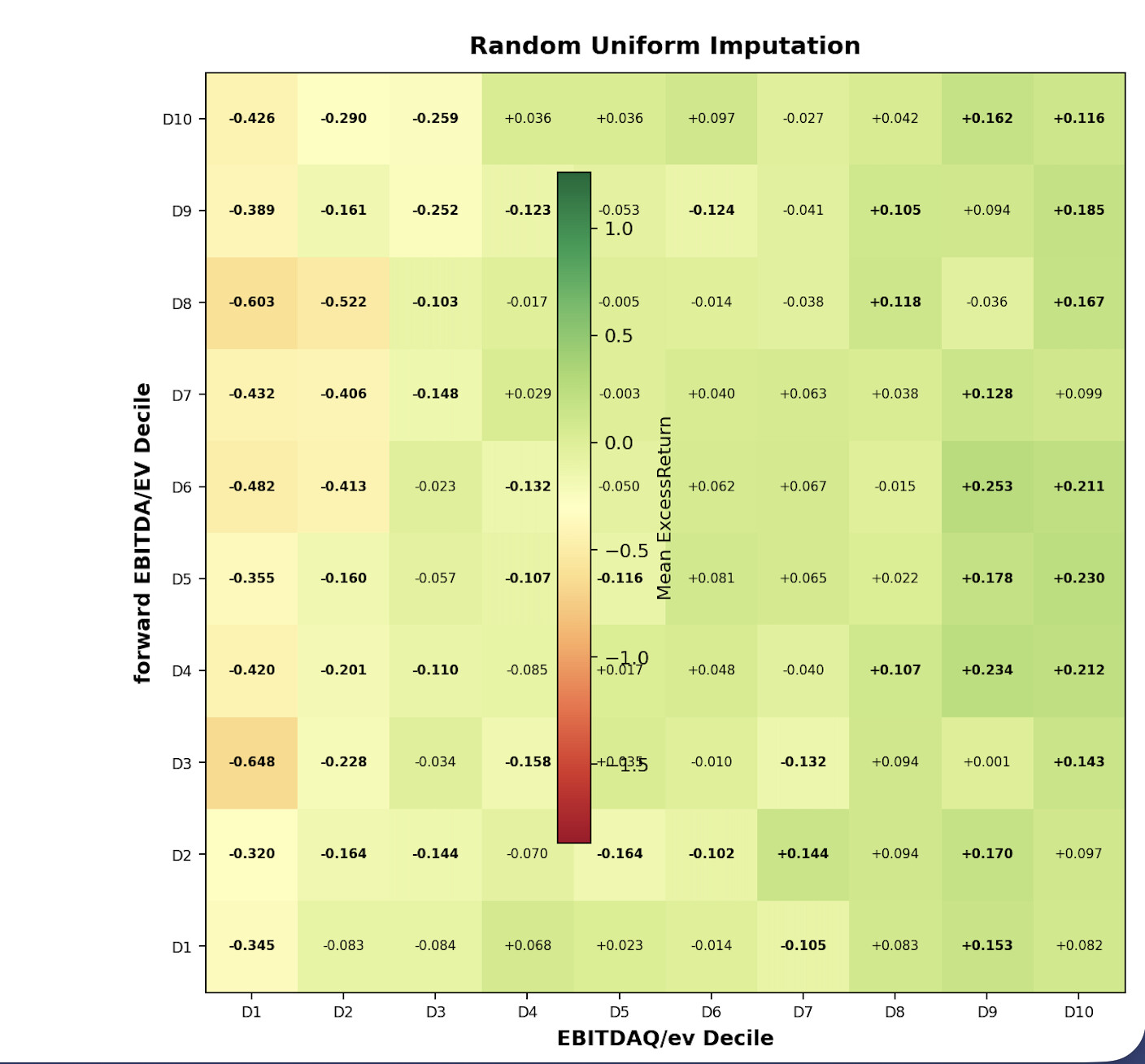
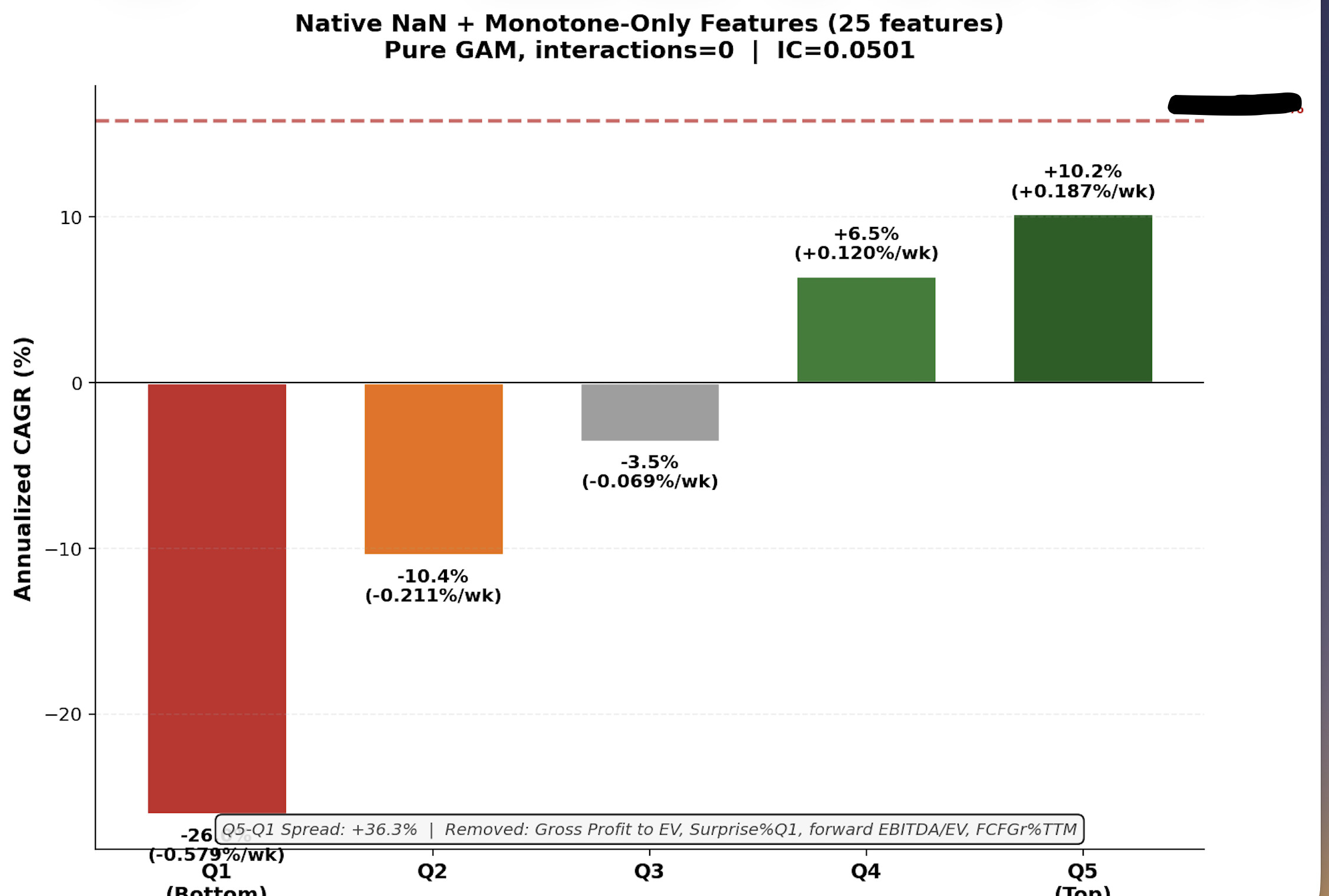
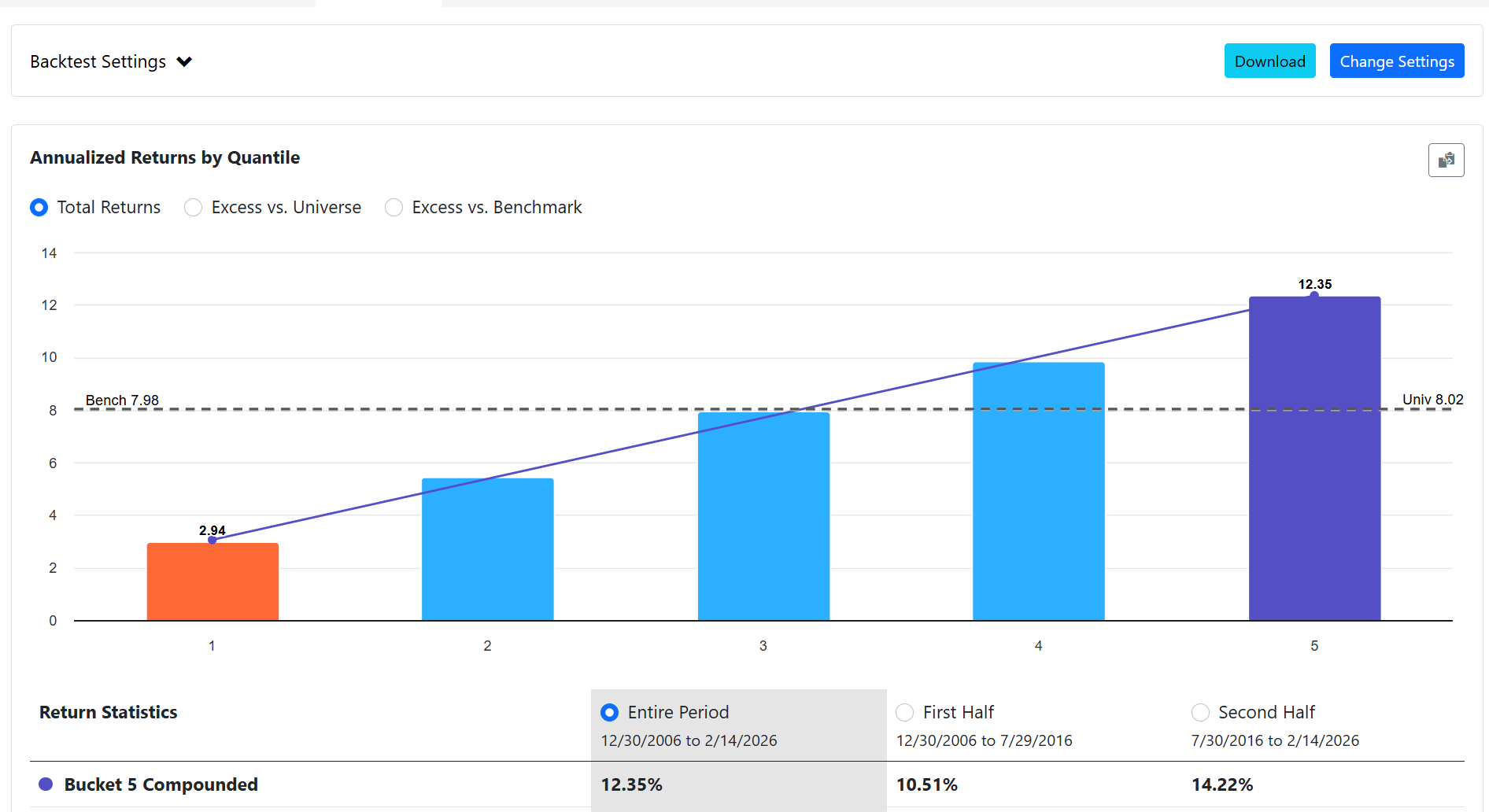
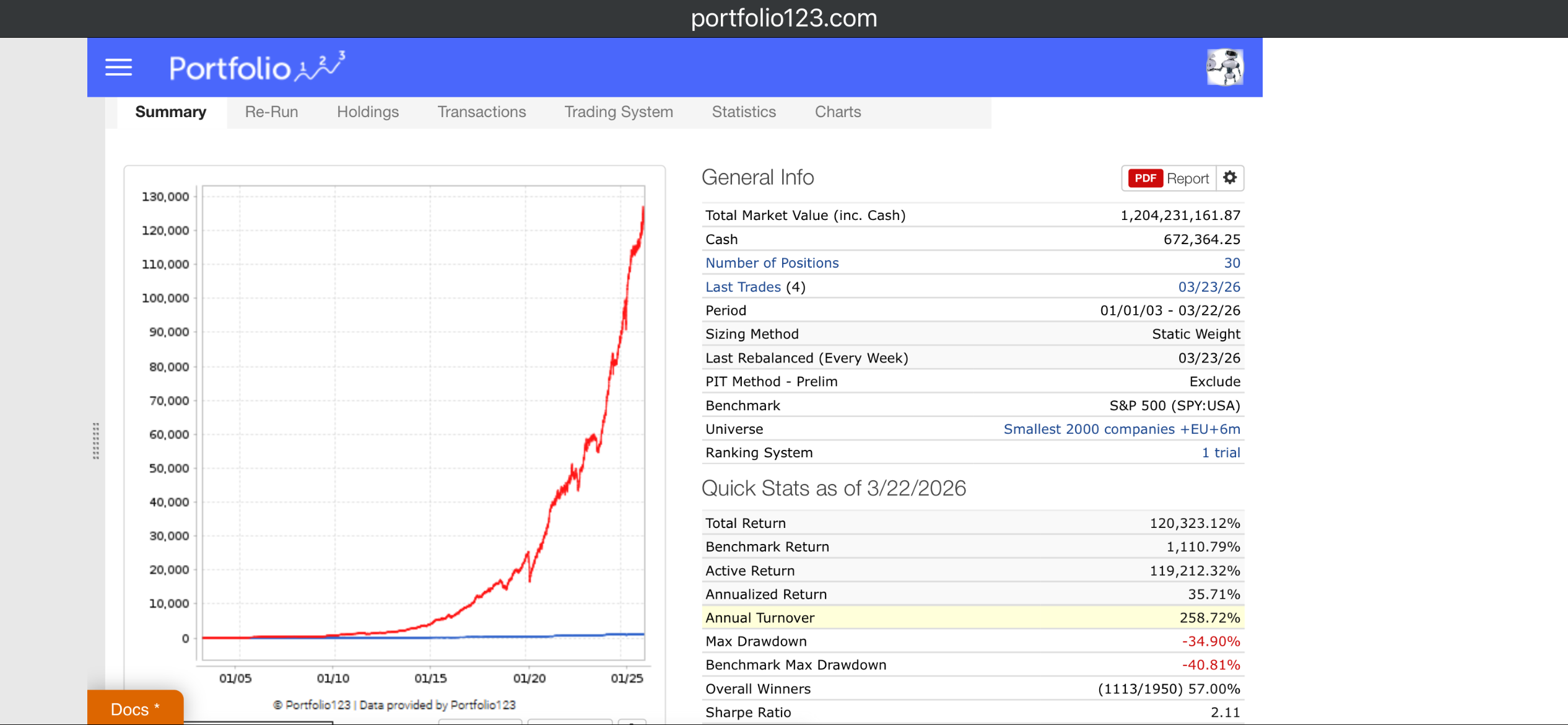
EBM parameters used above: max_bins=64, interactions=10, outer_bags=4, inner_bags=2, lr=0.01, max_rounds=3000, min_samples_leaf=100, max_leaves=3
Subsample to ~200K for training — larger datasets OOM kill the process.
In the weeds but maybe the most important thing. Claude expands the the curse of dimensionality below:
TL;DR: We don’t really have enough data to create a good non-linear manifold. Maybe exploring some corners is realistic but as a model it has problems.
Claude: "One caveat on interactions: with n features and decile bins you have 10^n [1 followed by 29 zeros] possible corners of the feature space. Your investable universe is maybe 4,000 stocks observed weekly. Most corners of the manifold will never be visited by any stock in your dataset — they don't just lack statistical power, they're empty. So any practical model has to focus on the low-dimensional projections where the data is dense enough to learn from. Full interaction modeling is probably unexploitable even in theory for most feature combinations."
Or a manifold projection (rank performance test) can be both a bug and a feature.