Hello, about a month ago I posted about an impending release here: Preview of our v1.1 of AI Factor: intelligent features, grid search, categorical & macro - #15 by marco.
Sorry it's taking so long but time flies, and we're trying to make the upgrades as intuitive as possible. They are in the final testing phases. The main changes recently have to do with the way the different normalization options are presented.
See below for a preview. It shows some of the different normalizations for a feature "Earnings Yield" (EY). Currently only one of the highlighted features is possible: either normalize EY cross-sectionally (meaning vs. other socks) using the entire dataset, or within a particular date.
In the new version you will be able to easily do different normalizations of the same feature thereby communicating something different (and uncorrelated) to the AI algorithm.
For example "1Y Relative (N=26) + Date & Sector" is a two step normalization that first calculates a z-score (or rank) for EY vs. it's 26 previous values sampled every two weeks (so for a period of one year). It then normalizes that score cross-sectionally against peers in the sector.
What the above is communicating to the AI algorithm is this: how cheap a stock is relative to it's history, and how that historical cheapness compares to the cheapness of stocks in the same sector. This is quite different than saying to the AI algorithm if a stock is the cheapest in the sector.
Sounds too complicated? We realize that greater flexibility comes with greater complexity, but we think it will be worthwhile. AI algorithms benefit from uncorrelated features, and it's better to present a powerful feature like EY in different normalized ways rather than using different valuation metrics with the same normalization.
Well, that's the theory at least.
Let us know your thoughts.
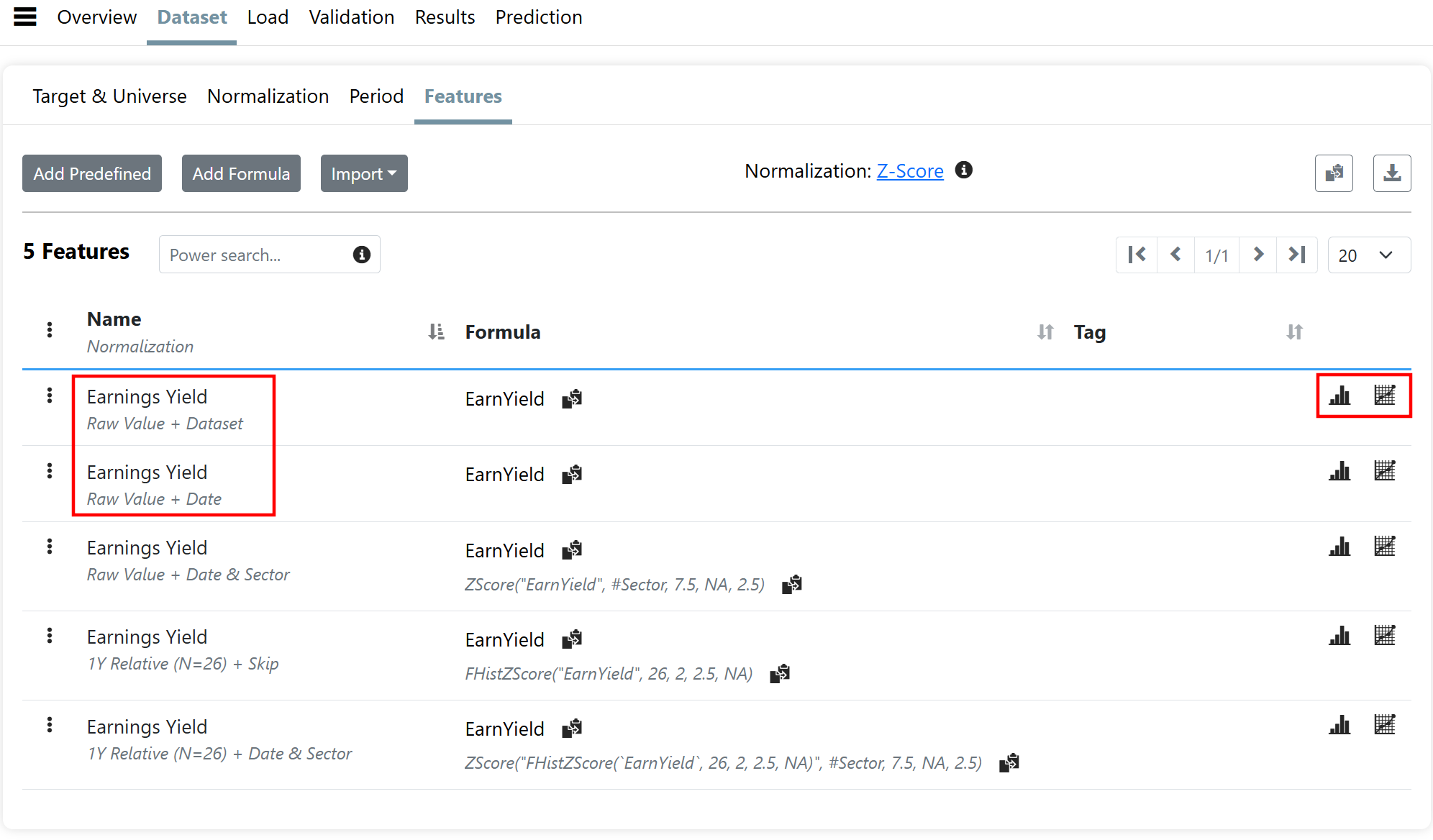
PS also note additional options to visualize the feature. You can now quickly visualize the cross sectional distribution for EY as well as the time series for a single stock