Once the validation is complete, is the model (algorithms) optimally adjusted to the underlying data or the specific target, universe and the universe in this one test?
So ,if I start testing on a new target or with a different universe, do I need to restart the process with the algorithms, or do the already validated algorithms from the first round have relevance for the next test?
Thank you, I was aware of this solution, but what I was actually wondering about is: When a model has been trained on a specific dataset with a certain number of features and a target, let’s say that Extra Trees III, for example, turns out to be the best model, is this model so specifically tailored to the features, dataset, and target from the initial training that it has little transfer value when applied to another training dataset or with different features?
In other words, if Extra Trees III is the best model for one dataset, is it general enough that it can also be effectively used in other tests?
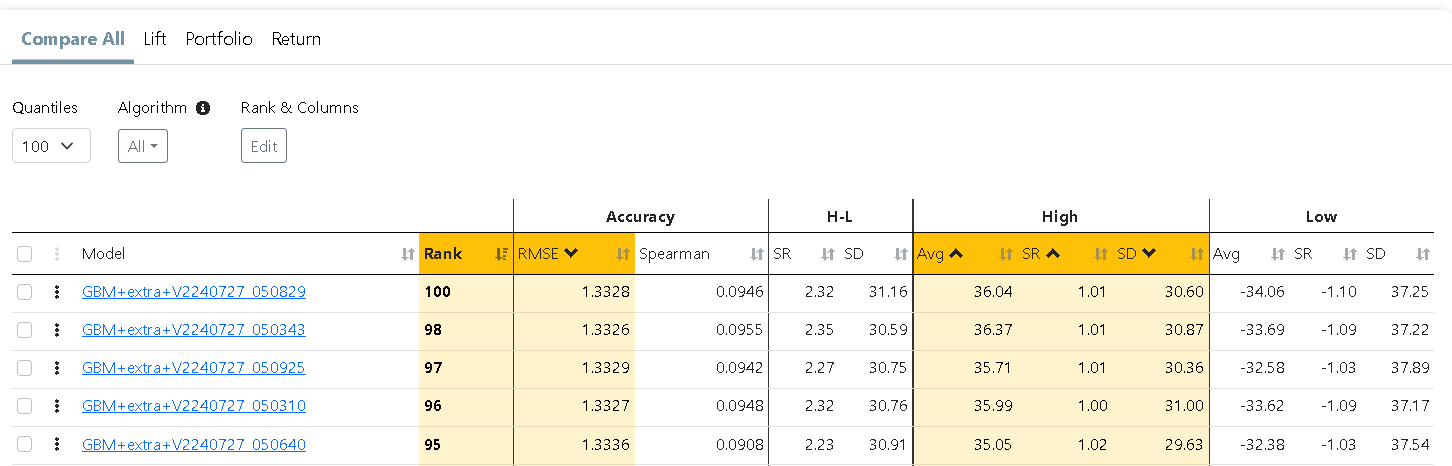
You need enough different datasets, objectives, validation methods, normalization methods and feature sets to test the robustness of this. I'd even have different optimal models with the exact same feature set, objective, validation method, and set of features just because of the different normalization methods: one with absolute hegemony of the linear model and one with absolute hegemony of LightGBM. Therefore, the best choice is best made by averaging many different good models, rather than optimizing methods/parameters with your In-sample data.
In my experience, individually the extra trees, LightGBM and linear models are always the best, just the ranking varies. But neural networks have good stochasticity and are best used for model averaging. The best model for actual trading is probably a combination of a few extra trees, a few LightGBMs, a few linear models and a couple dozen neural networks. All of them have the best parameters settings.
Yes. The model is "optimally adjusted" in the sense that I think you cannot use it with different features or a different target.
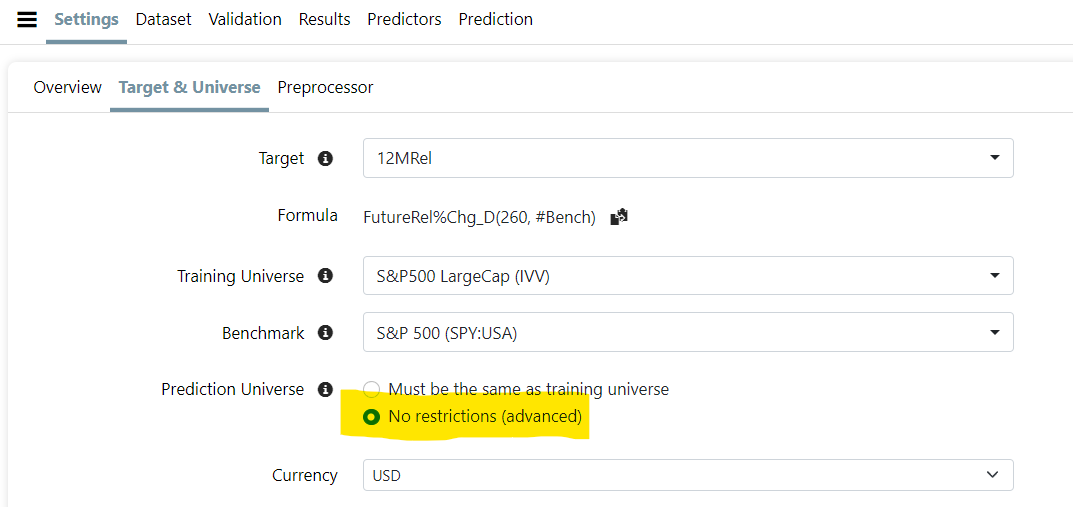
I do think you can use a somewhat different universe if you do not change the features or the target. Personally, I train a model on the Easy to Trade universe but fund a model using a universe that is slightly more liquid that the Easy to Trade Universe.
It is my belief (with little proof) that the benefit of training on more data points with the Easy to Trade universe outweighs the possibility that the more liquid universe is a lot different. I would be hesitant to say whether I could fund a model that uses the SP500 universe that has been trained on the Easy to Train Universe. But probably not.
For example, analyst recommendations are probably factored into the price of SP500 companies quicker and/or incorporated into the FactSet data quicker—making those factors behave different for different universes. Different in ways I won't speculate on here, but making models for a large-cap universe different than a micro-cap universe.
Neural-nets can use "Transfer Learning" where the features and target can be different but that is not applicable to P123 yet I think. Probably not an upcoming feature either, I would guess. I mention it largely because it is just plain cool and because it is the only exception I am aware of. The exception to using different features or targets in training.