Thank you, Robert. I’m still struggling to understand how, practically, to measure factor-based risk and what exactly it means. I did read the two PDFs, but I got lost halfway through the second. They didn’t clarify that question, because they didn’t provide an example of how it’s done in the equity space.
I’m fuzzy about the basics. For example, if each factor has a time series that one regresses against, is it a time series of the long-short portfolio formed according to that factor? I couldn’t find any discussion of a long-short portfolio in those two papers. Also neither paper addressed the question of persistence at all.
There was another explanation I read of risk-based factors in Alphanomics, a book by Charles Lee and Eric So which I reviewed on our blog. Unfortunately, I no longer have a copy of that book. I wrote,
Lee and So then take on the idea that abnormal returns (pricing anomalies) are a compensation for risk factors. This doesn’t fit with empirical observations. There is a great deal of evidence that “healthier and safer firms, as measured by various measures of risk or fundamentals, often earn higher subsequent returns. Firms with lower beta, lower volatility, lower distress risk, lower leverage, and superior measures of profitability and growth, all earn higher returns.” In other words, these companies all appear to be less risky than comparable companies.
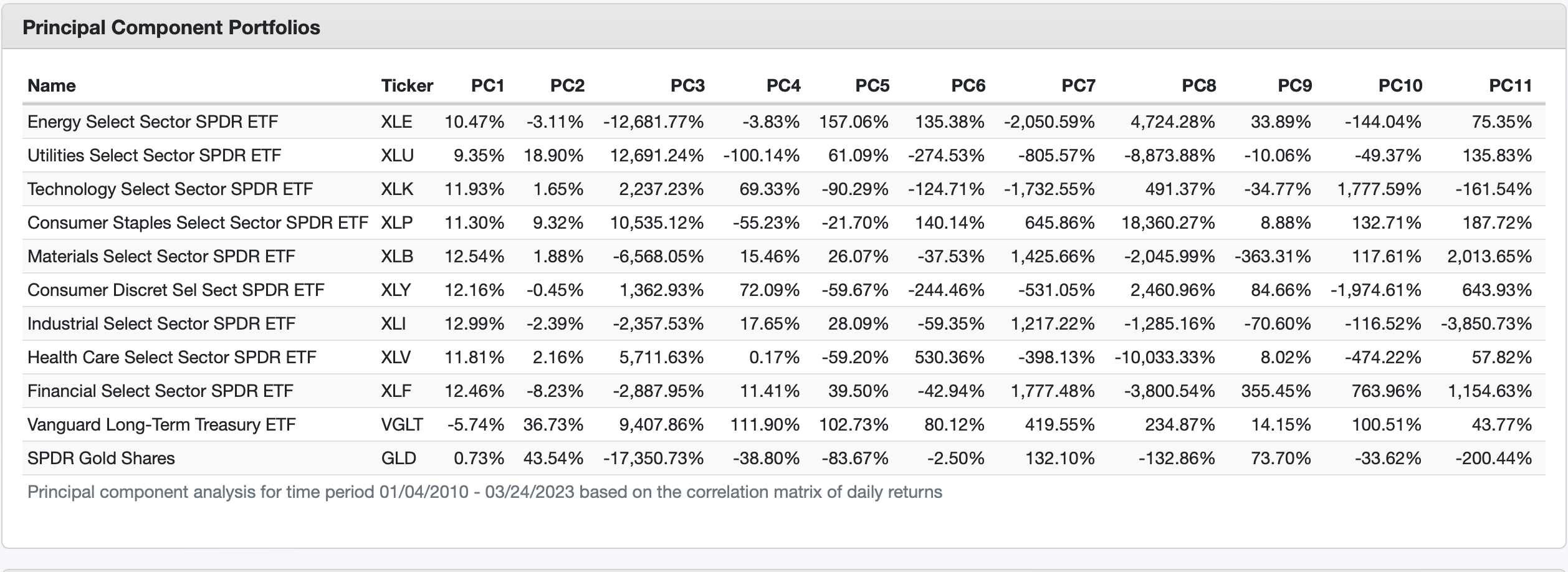
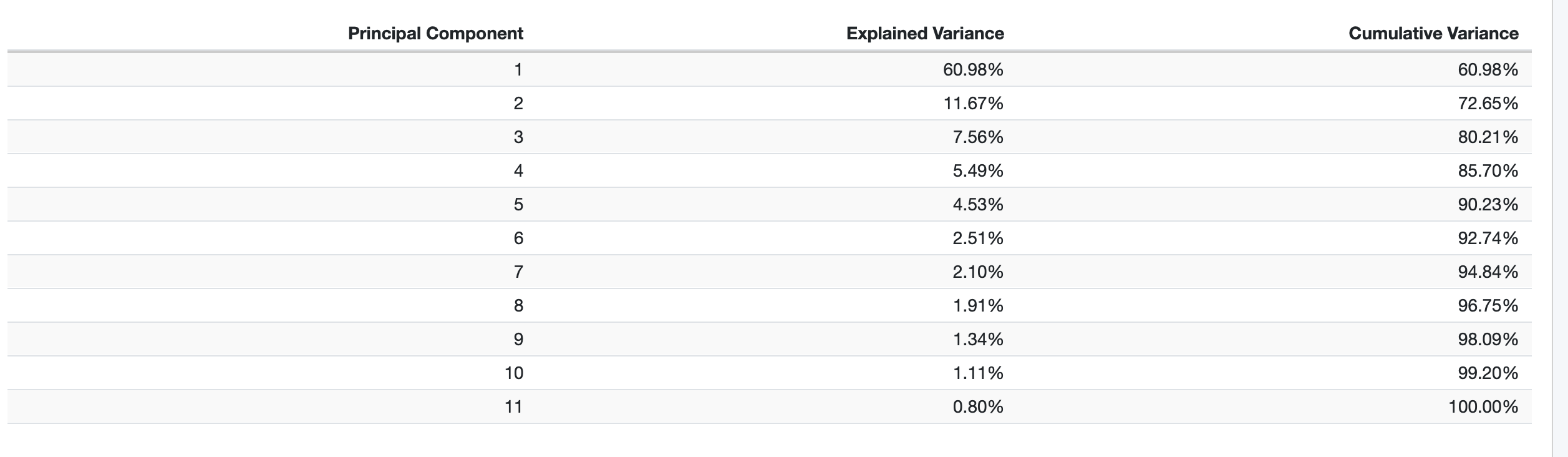
If I were to design a factor-based risk model, maybe I’d put minus signs in front of some of the betas rather than putting plus signs in front of them all (in Barra p 6, equation 1-2). Maybe I’d leave the plus signs in front of size and growth and put minus signs in front of low volatility, quality, and value, since those factors all diminish risk (obviously, high-volatility stocks, low quality stocks, and overpriced stocks are riskier than their opposites). But I’m probably misunderstanding what’s going on.
To be clear, I would never argue against the idea that we should offer some sort of factor-based risk measurement on our site. Personally, I’m extremely interested in a way to measure 4- or 5-factor alpha, because 21-day volatility as measured by 4-factor alpha has been determined to be one of the best factors in the non-US developed market (see The “Factor Zoo”: Some Thoughts on “Is There a Replication Crisis in Finance?” - Portfolio123 Blog). So any tools developed along these lines would be terrific not just for you and for other Portfolio123 members but for me personally as well.
To conclude, I’m determined to eliminate my confusion about all this. I hope by this time next week, I’ll understand it all perfectly. Please don’t feel obliged to help me–I know some others who can do it too. But I did want to thank you for trying to help and to explain where I’m at right now.