Dear all,
Following my earlier post on Numerai 2023 performance, I am posting this so that we can avoid the mistake made by Numerai in their hedge funds when dealing with AI/ML.
As I understand from Jim @Jrinne, he is currently doing a number of things (outside P123) that are mentioned in this article including cross validation,L1 and L2 regularization, early stopping, bagging and boosting.
Here are some extracts from the article :
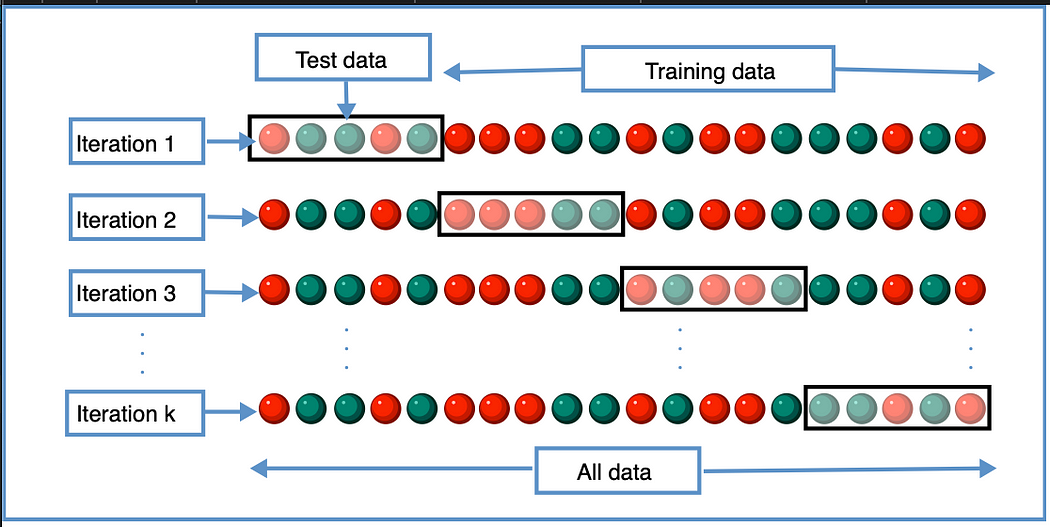
- Cross-validation:
Source:en.wikipedia.org
The idea is very simple, we take the training data and split this into multiple training/testing data sets. Using k-fold cross-validation, we partition the data into k subsets known as folds. We then train iteratively on k-1 folds and gets the result on remaining fold in each iteration. So in each iteration the model trains on k-1 folds and then we get the accuracy on the remaining fold. For all iterations, we average the results at the end to get the final accuracy.
d) L1 and L2 regularization:
A regression model that uses L1 technique is known as Lasso regression and if it uses L2 technique it is know as Ridge regression.
The main difference between them is the penality term.
1 .Lasso Regression:
Lasso Regression adds absolute value of magnitude of coefficient as penalty term to the loss function.
If lambda is zero then we get back to OLS and if lambda is very large value it will make coefficients zero hence it will under-fit.
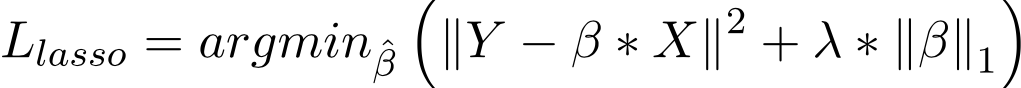
Source:geeksforgeeks.com
- Ridge Regression:
Ridge regression adds a squared magnitude of coefficient as penalty term to the loss function.
If lambda is zero then we get back OLS and if lambda is very large then it will add too much weight and it will lead to under-fitting. So we have to choose lambda wisely to avoid overfitting.
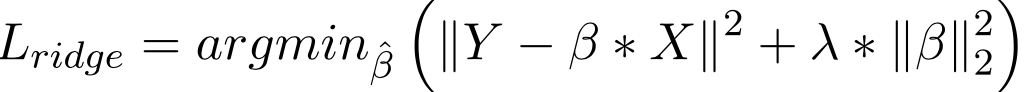
Source:geeksforgeeks.com
a) Early stopping:
While iteratively training the model, we could check how the model is performing in each iteration. Generally a model performance improves until a certain number of iterations, there is no point to further train it as performance might go down. Early stopping simply means to stop the training before the model starts to overfit the data.
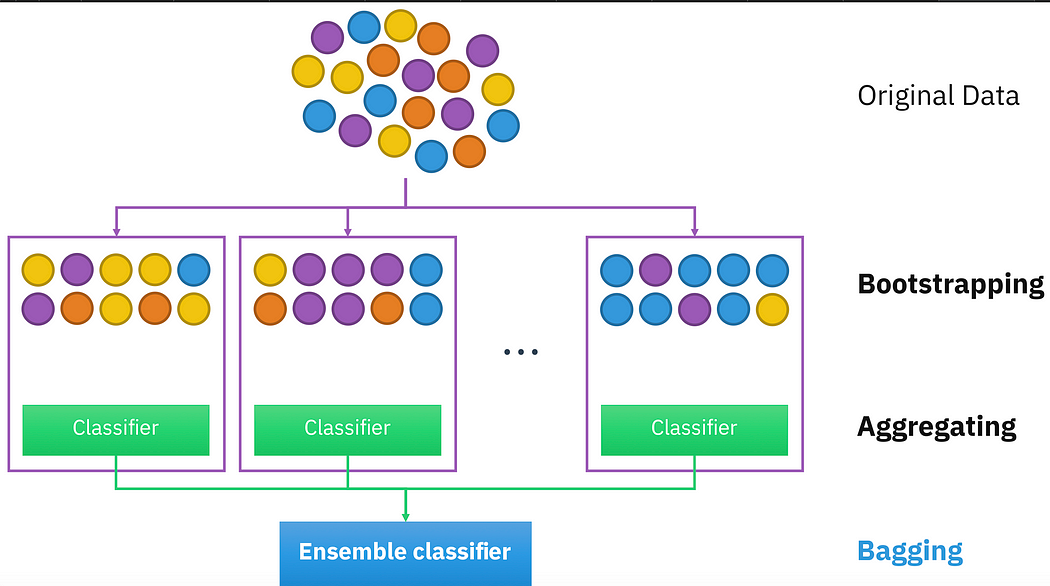
Bagging:
Source:en.wikipedia.org
It is also known as bootstrapping aggregation which helps in decreasing the variance and hence, overfitting.
a) It trains a large number of models in parallel.
b) It then smooths out the prediction by averaging out the results.
Boosting:
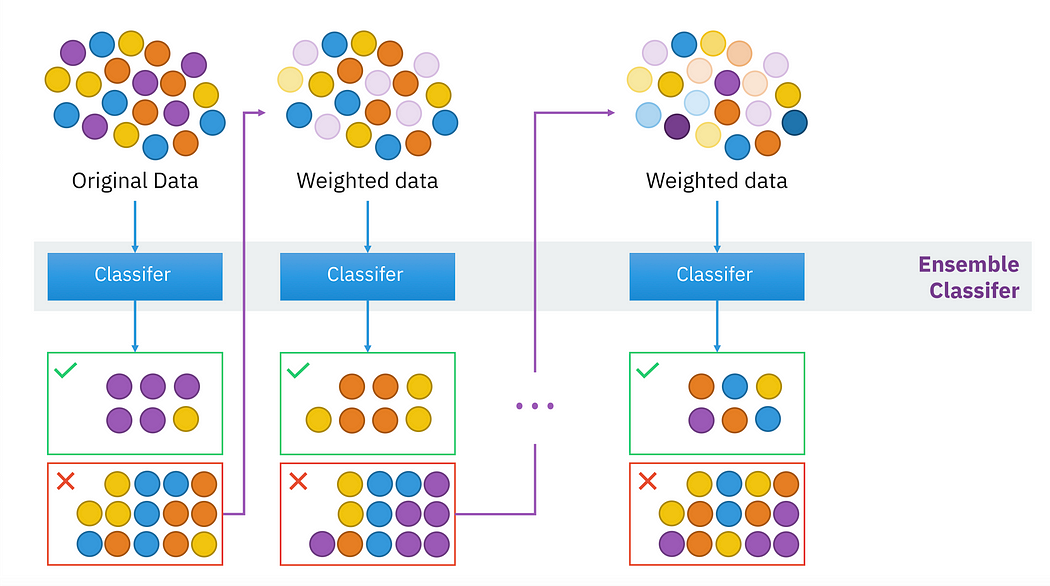
Source:en.wikipedia.org
The model starts with a weak learner and gradually we train it in sequence where the next sequential model attempts to correct the error made in the previous model. Basically, we create a lot of strong learner from a number of weak learners trained in sequence.
Regards
James
Link to the whole article :