I would need to see that high of a validated return or higher.
It would be nice to have at least screen-based validation. The top bucket of the validation sample is probably adequate but if you can do that a screen based on validation data (predictions) could be done (and concatenated as I have done here).
So then the main question—assuming I can just use the top bucket--is: Why am I getting better results that would literally force me to use the API?
I think despite a recent paper in the forum, I want a prediction of what matters to me most: What are next week's excess returns relative to the universe going to be?
There is more noise when you look at that, as the reduced Spearman's rank correlation would suggest. But at lease I am getting an answer to the question that matters most. And the Spearman's rank correlation is not degraded so much that the data does not tell me what I need to know.
So I do love the AI/ML!!!! But I might have to use my present methods (with or without the API) with less cost, and so far, better results at the end of the day.
The question in the headline is one I've been asking myself for months and I don't know the answer.
I've been using ranking systems since 2015 and have been very happy with them. I feel like they have the ability to take into account everything I want to know about a stock, and my results have been wonderful.
So I think I would need a clearly reasoned explanation of the advantages of AI/ML over ranking systems. Right now they're too much of a black box. No matter how much I read about the various algorithms offered here, they're not as intuitive as multifactor ranking.
I can design a ranking system to choose stocks based on simulations that mimic (to some degree) how I actually manage my portfolio. With AI/ML, I have to use predictors that focus on one thing (e.g. forward six-month return).
Now that could be extremely useful to me for stockpicking for put options, since I can't simulate that, and since what I really want to know when choosing a stock to option puts on is what the probability is that the price will go down more than 20% in the next six months. So for that, an AI/ML model might be wonderful.
I'd love to hear what other people think about this.
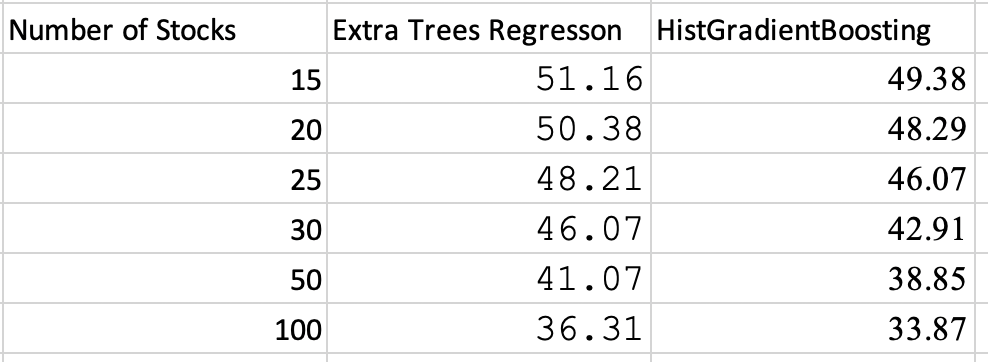
You can do 100 buckets in the Reports, so a 1500 stock universe will report using 15 stock portfolios. What size is your universe? Maybe you need 200 buckets?
I agree with @Jrinne that some sort of validation is needed for advanced users.
I was thinking about allowing to download dataset after pre-processing and python code used to train and validate models. For example now, when I use 'monotonic_cst' for RF, I do no know what is the order of variables in a X.columns vector. I need to know this to set array for 'monotonic_cst' e.g., [1,1,-1, 0,1 ...]
Secondly, related to Yuval concerns, still more transparency/enhancements is needed....Yuval may like to use linear model with time varying coefficients, which are exposed for each training period for users + ability to constrain parameter signs to be positive (it is now possible through using {"positive" = true} but not sure if this works). In the long term, time varying linear models should be rather a separate module integrated with live simulation or simulated strategy - (automatic coeffs update after X months or after VIX reached X level or 3 months portfolio return in below X% ). Plus allow to use variable selection (forward, backward, etc), plus more.
I agree. The number of stocks in a bucket remains fairly constant. So there is no real difference between a screen and the top bucket.
I use the easy to trade universe to train and like to have 15 stocks in a screen, sim or port. More buckets to make 15 stocks in a bucket with the easy to train universe would be nice.
Pitmaster makes a broader point. You can do buckets (as you have done) and screens (as I have demonstrated) with the validation data. You can also make Sims with that validation data and you do not have to retrain to do it. The data to do that is already in the validation data. Something for the future maybe.
In my specific case, I need to compare these k-fold validations (3-year embargo after the validation data) to what I get with P123's AI/ML. It would be my sincere hope that I would find P123 could ultimately beat my method (with such an easy to use interface), or provide comparable results and I could just sign of for P123's AI/ML at a price I can hopefully justify in a spreadsheet. Convince my wife to give up saving for that Hawaiian vacation and let me upgrade to P123's AI/ML. I mean by this, I want to sign up but I have to be rational about it. The costs show up on my business credit card (not sure if my accountant can call it a business or "Pension Fund" expense but I try). Even so, it cannot be entirely for fun. It has to make me money.
So let me not jump to any conclusions or have any basis, I hope. Here are my basic questions:
Can I compare what I have done here to the top bucket of an AI/ML model? The forward-looking-period is different. "Future 1 wk returns" for the stocks purchased for my performance (trained on the one-week excess returns relative to the universe)..
Probably redundant but stated more simply, Do I know which will make me the most money?. Do I actually know for sure?
When a P123 AI/ML model is fully trained and implemented would I be using a monthly rebalance or a weekly rebalance? i have used weekly in the past. If weekly rebalance, would it be good to have trained on "future 1 wk return"? Maybe but maybe we are not sure? .Not sure and limited in our ability to test this now?
If it turns out that I can compare the k-fold validations above to P123's k-fold validations and mine are better, what can I share with P123 to improve their AI/ML so I can sign up. If there is a difference: Why?
I heard Patrick O'Shaughnessy several years ago say that OSAM, after hiring a team of data science engineers, had more success using ML for things like future sales or earnings projection factors rather than to predict stock price action. Focusing on that and then plugging that into existing rankings, perhaps as a imported factor, might be a better starting point until the models/processes becomes more intuitive for those with more of a background in finance/accounting and less in ML/data science.
Cool. But then what do you do with that predictions of future sales using ML?
Plug in into a ML model, of course, would be my immediate response. This is called stacking.
You could also sort the predicted future sales and plug that into P123 classic ranking system. Or maybe make a discretionary call.
Not a bad idea no matter what you do with it or what you call your ultimate method. Maybe one would think they are a discretionary trader using some ML data.
Edit: what Marco suggest below is what I would call"Stacking" which is a very advance ML techinique. Nice!!!!! Maybe that is a reason to switch, BTW. I want to find a reason to switch and hope I find a good answer to the question I am asking myself above.
You just copy the predictor formula and use it inside the ranking system, just like any other formula. But the backtest will be slow, at least in the first pass. The second pass will be fast since the ranks are cached.
Ranking system ranks are retained for 5 minutes following latest access. We do intend to make improvements around predictions for a better experience in Research.