I am looking at moving from only ranking system optimization to ML again and I would like to be able to preserve the relationship between factor values for my ML models. However, ranks are evenly distribute and I have found that when I downloaded zscores the data always has a fair amount of points at my maximum value which I set to 10 std.
Any suggestions on how I can deal with this? Do I need to write a formula to normalize the data before downloading as a zscore? Or is there some way I can make sure the min and max zscore will all within the limits of +/-10 before I download? I know zscore has an outlier trim function, but I would prefer not to trim at download if I don’t need to.
@marco I assume the ML release will help resolve this, any news?
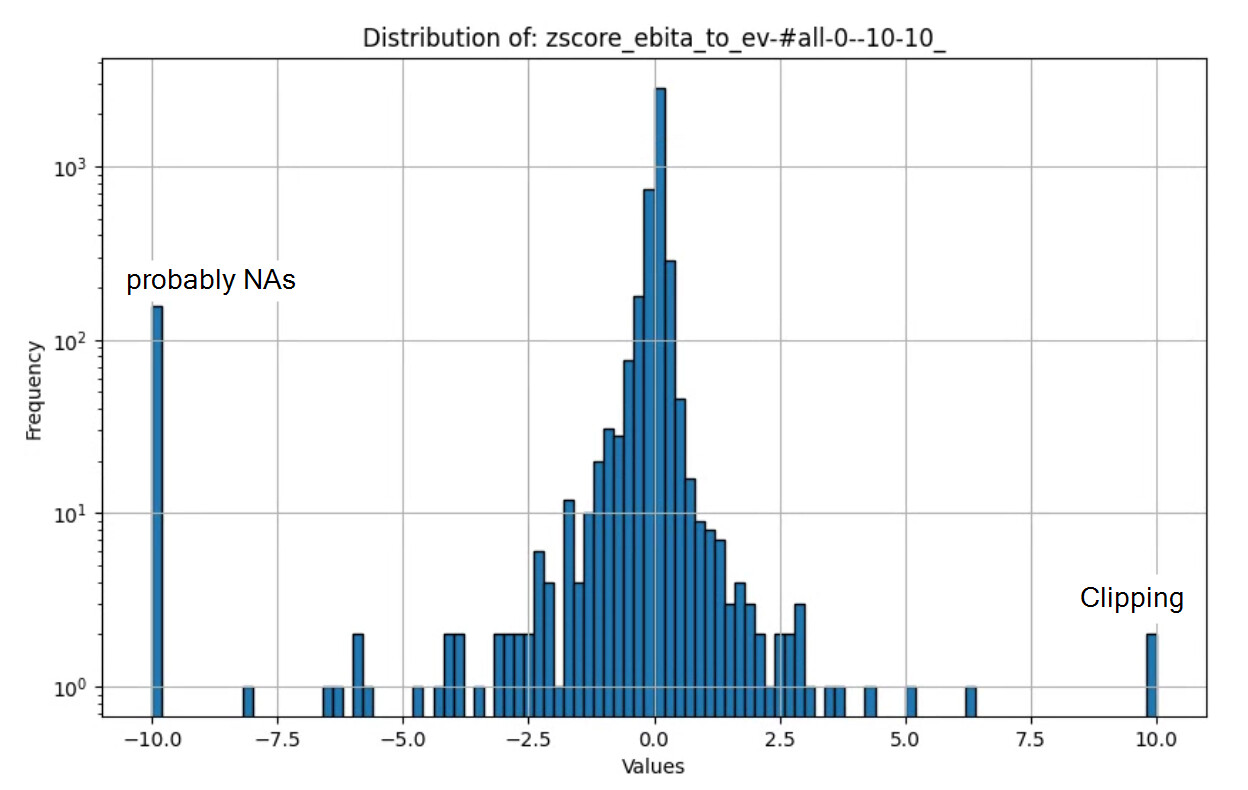
Example of why I am worried about this (yes I set the NA values to -10 so it is moving the mean off of 0 like it should be):
zscore(“EBITA”, #All, 0, -10, 10):
My understanding is that if you do not trim, then the most extreme raw values of factors will impact mean used to calculate zscore. Also -10 as NA may have some impact on the results…
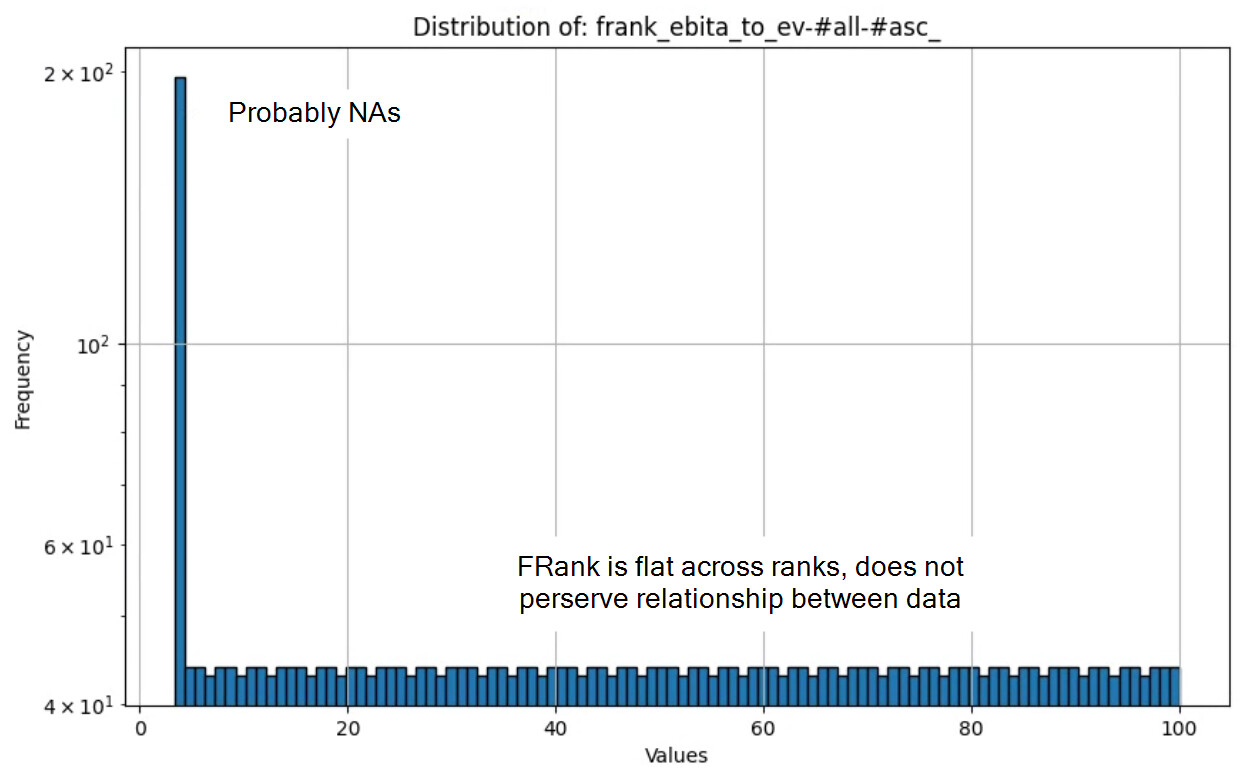
I played with ZScore and I could not fully understand how trimming is applied.
Maybe P123 should provide detailed formula (e.g., python code).
I’m not sure if this will work for you, but you can consider this formula:
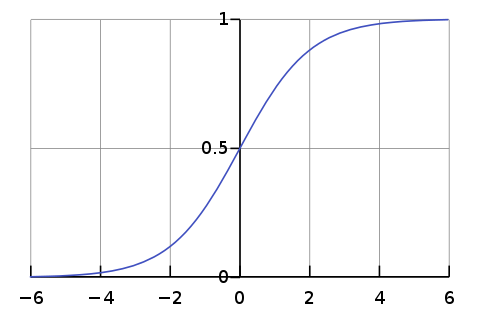
1/(1+POW(2.71828,-ZSCORE(“EBITA/EV”, #All, 0, 0, 10)))
This is zscore without trimming transformed by sigmoid function.
This will penalize extreme values both low and high, while still preserving the relationship between factor values.
I was thinking of something like this, but apply the zscore last:
ZSCORE(“1/(1+POW(2.71828,-EBITA/EV))”, #All, 0, 0, 10)
This may not solve the problem though as it might still end up with data at over 10 std from the mean... Also I realized it probably drops the NAs, so you loose that information.
I think this could be a good path to resolving the issue if P123 does not come out with other normalization options!
We’re putting the “Factor Download” through the final QA tests, it will be released this week. It’s a pre-cursor to our full AI/ML offering.
It has several normalization algorithms: rank, z-score and min/max, and has user configurable trim %. So relatively simple normalizations that probably will not fix your issue. The goal of this tool is two-fold: to offer a simple way to download ML compatible data , and to gather feedback. We’ll look into adding the sigmoid function as a built-in, thanks.
PS. Min/Max is probably what you need as it preserves the linear relationship between values so you do whatever normalization you need outside of p123. It scales from 0 to 1.0 with many digits of precisions.
Great news. I did confirm that the new download tool does not clip zscores! It should also preserve the relationship between data since it is an offset and scaling.
Here are two factors as an example were I calculated the min and max zscore (using chatgpt 4…):
Enterprise Value: Min = -0.168050, Max = 34.350542