Dan has posted a format for downloading a csv file with DataMiner in a separate post: Thank You Dan! - #5 by Jrinne
Here is an example of some code that could be used with that download to test a random forest model with the ultimate goal of finding a model that could be used with a P123 port. Obviously this is just one example of a huge number of machine learning methods available thru Scikit-Learn:
I modified Dan’s DataMiner code a little for my ranking system but nothing you couldn’t or wouldn’t do yourself. The machine learning model (if you liked it after using the code below) could be used to predict returns of stocks. It would only be 2 or 3 more lines of code to predict returns once you find a model you like. You could then sort the returns to get the tickers with the best expect returns over the next rebalance period. You might then enter those tickers into in-list for a port and have P123 rebalance the port and keep track of the returns for you.
I used the csv file generated by DataMiner and uploaded it into Python without changing anything including the names of the column-heads for the Pandas DataFrame.
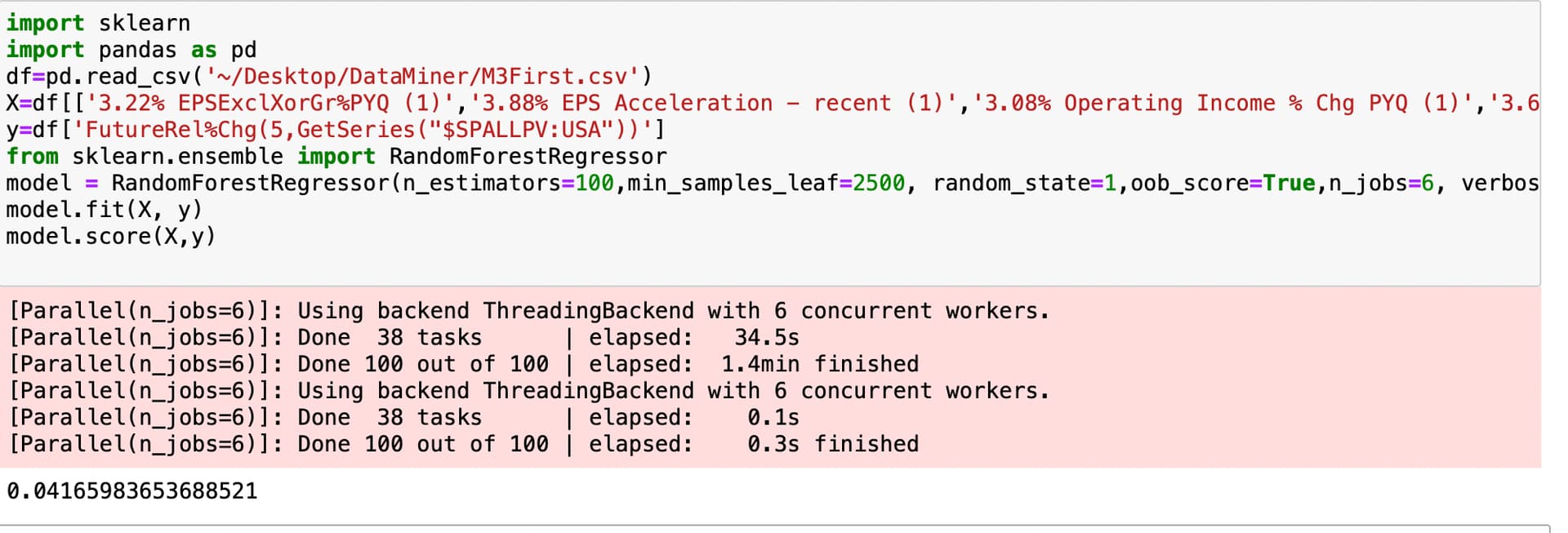
You can look up the meaning of oob_score yourself without my boring you (and determine its value and significance here). To be honest, I did not have a lot of credits and oob_score was just the easiest to use and perhaps somewhat valid without a lot of data. I am not claiming it is the best method or one you would end up using if you do machine learning in the future. You will want to use other/additional tests of a machine learning method; no doubt about that.
Also I am sure that ChatGPT and Bard know what an oob_score is. They can explain this better than I could and help you with any additional coding you may be interested in for testing or validating a random forest or any other machine learning methods. And answer any additional questions you may be about machine learning that matter.
Only for those interested in machine learning and/or random forests. But you can see that is not a lot of coding (thanks to Dan doing most of the coding to get the Pandas DataFrame I needed).
Specifically, 3 lines of code once you upload the csv file, define the DataFrame and import the libraries.
You should have no trouble getting started on your own model with ChatGPT’s help. But best of all is that you can find out for yourself what works for you with ChatGPT and Scikit-Learn. This is only one of a huge number of possible methods and not necessarily one that anyone (including me) would actually invest in:
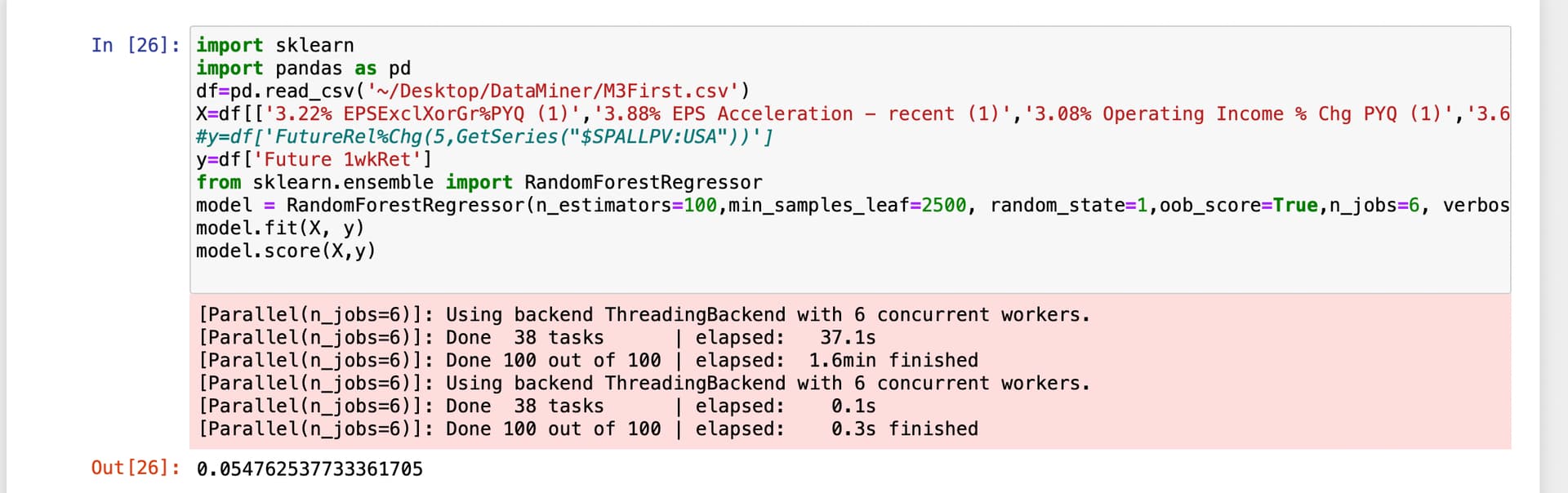
Edit: I was surprised to find that raw returns gave a better oob_score than excres returns to this benchmark. IMHO, an oob_score of 0.055 is not bad for noisy stock data. But again this is a poor sample (I did not have a lot of P123 API credits). And I could learn a thing or two about machine learning still which I am working on this morning. A start and not a final anything but it would be nice if raw returns were adequate!!!:
Jim