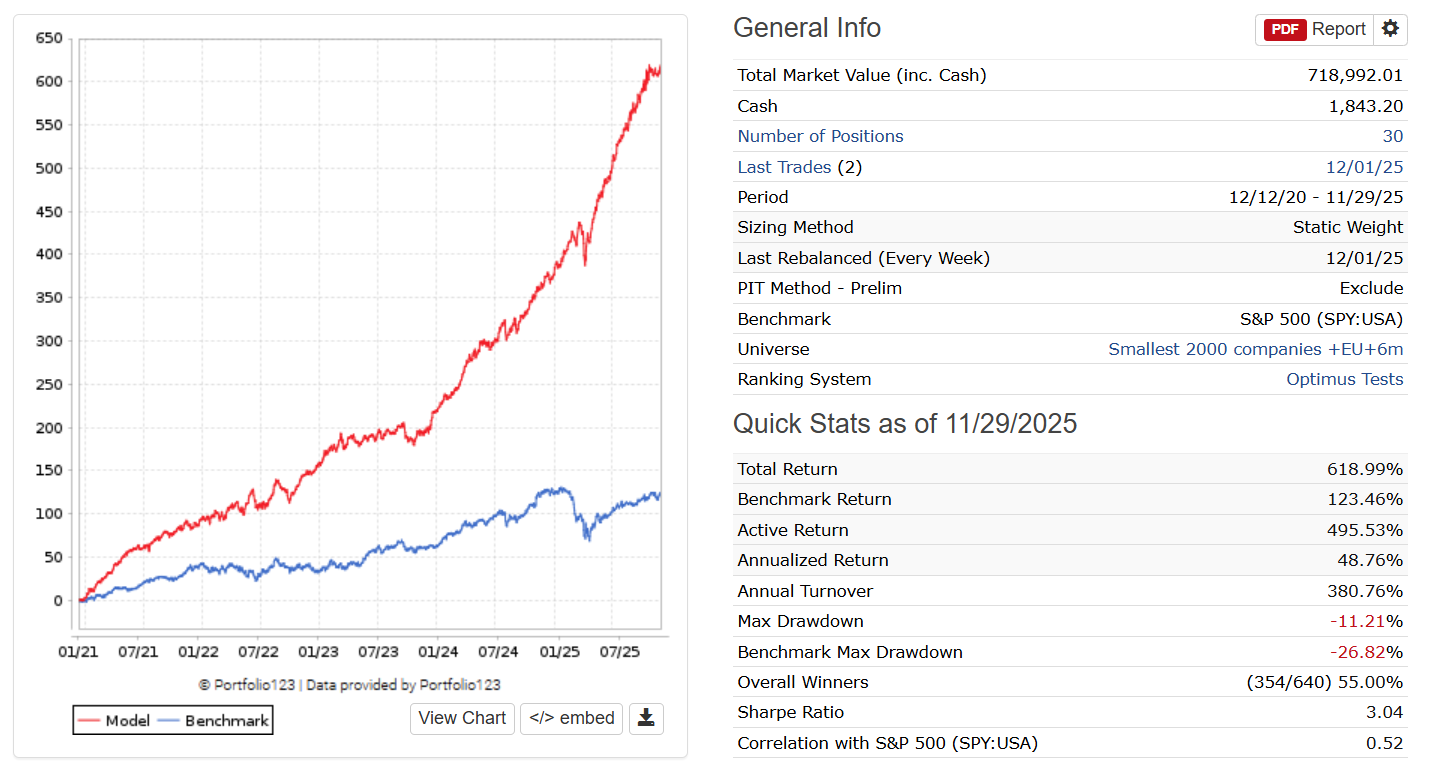
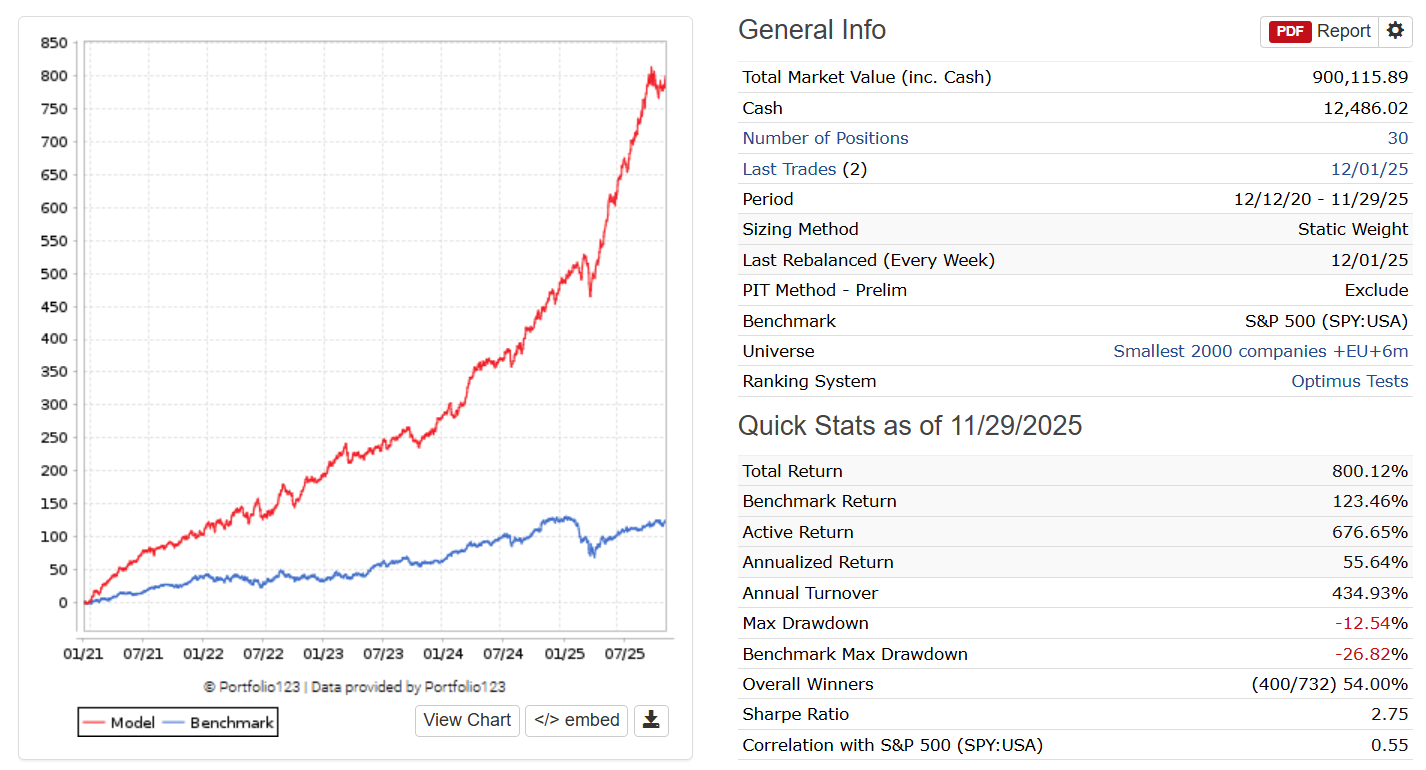
Hey everyone,
Wanted to throw out a feature request that I think could really level up the AI Factors platform — specifically, adding support for LightGBM’s rank_xendcg objective.
Here’s the quick rundown:
Why Bother?
Most of us are used to optimizing stock return models using RMSE or similar regression losses. But there’s some pretty convincing research showing that ranking objectives actually perform better when you’re building systematic stock selection strategies.
Poh et al. (2020) showed that using LambdaMART (an implementation of LambdaRank) can improve out-of-sample Sharpe ratios by 3x compared to standard RMSE-based models. Pretty big jump. (Check out Exhibit 2 in their paper.)
Bruch (2021) took it a step further, introducing XENDCG (Expected NDCG) — it’s a listwise ranking loss that not only performs better but trains faster and more stable than LambdaRank.
Given that cross-sectional ranking (not point predictions) is the bread and butter of a lot of strategies here, I think this could benefit everyone.
What’s Blocking It Right Now?
When I try to set:
"objective": "rank_xendcg"
LightGBM throws this error:
LightGBMError: Ranking tasks require query information
Looks like P123 isn’t passing the group/query info that LightGBM needs for ranking objectives to work.
The Ask:
Could we get:
Support for rank_xendcg in LightGBM
Proper handling of the query/group data that LightGBM needs for ranking tasks
Why It’s Worth It:
It’s a cleaner fit for cross-sectional long-short models.
Faster, more stable, better ranking — backed by solid research.
Opens up a lot of cool opportunities for building systematic strategies focused on rank rather than raw returns.
Would love to hear thoughts from others — has anyone else tried using ranking objectives elsewhere? Curious if anyone’s worked around this limitation or if the dev team has thoughts on feasibility.
References:
Poh, Daniel, et al. Building cross-sectional systematic strategies by learning to rank. arXiv preprint arXiv:2012.07149 (2020).
Bruch, Sebastian. An alternative cross entropy loss for learning-to-rank. Proceedings of the Web Conference 2021.
Thanks all!
Henry