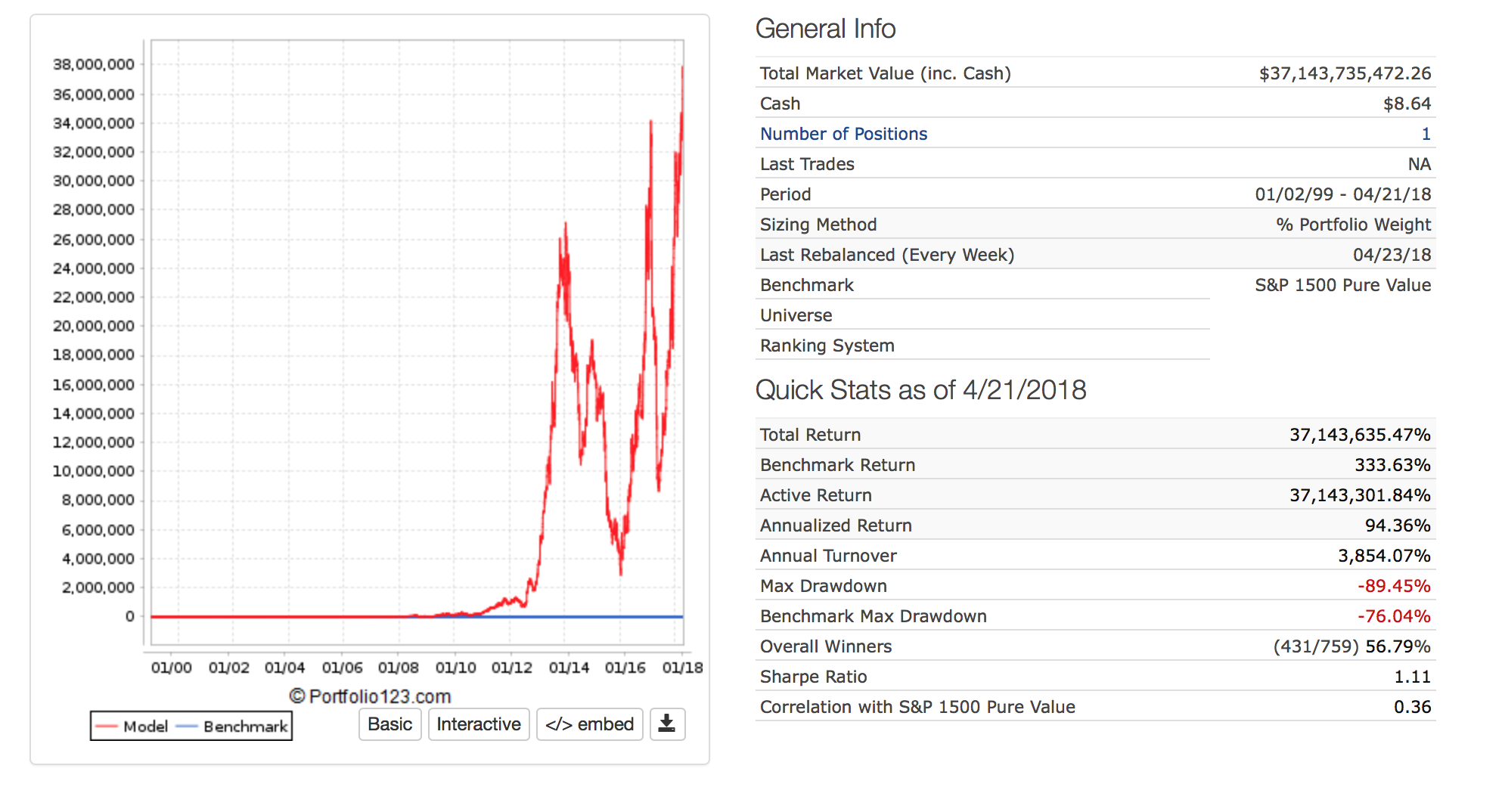
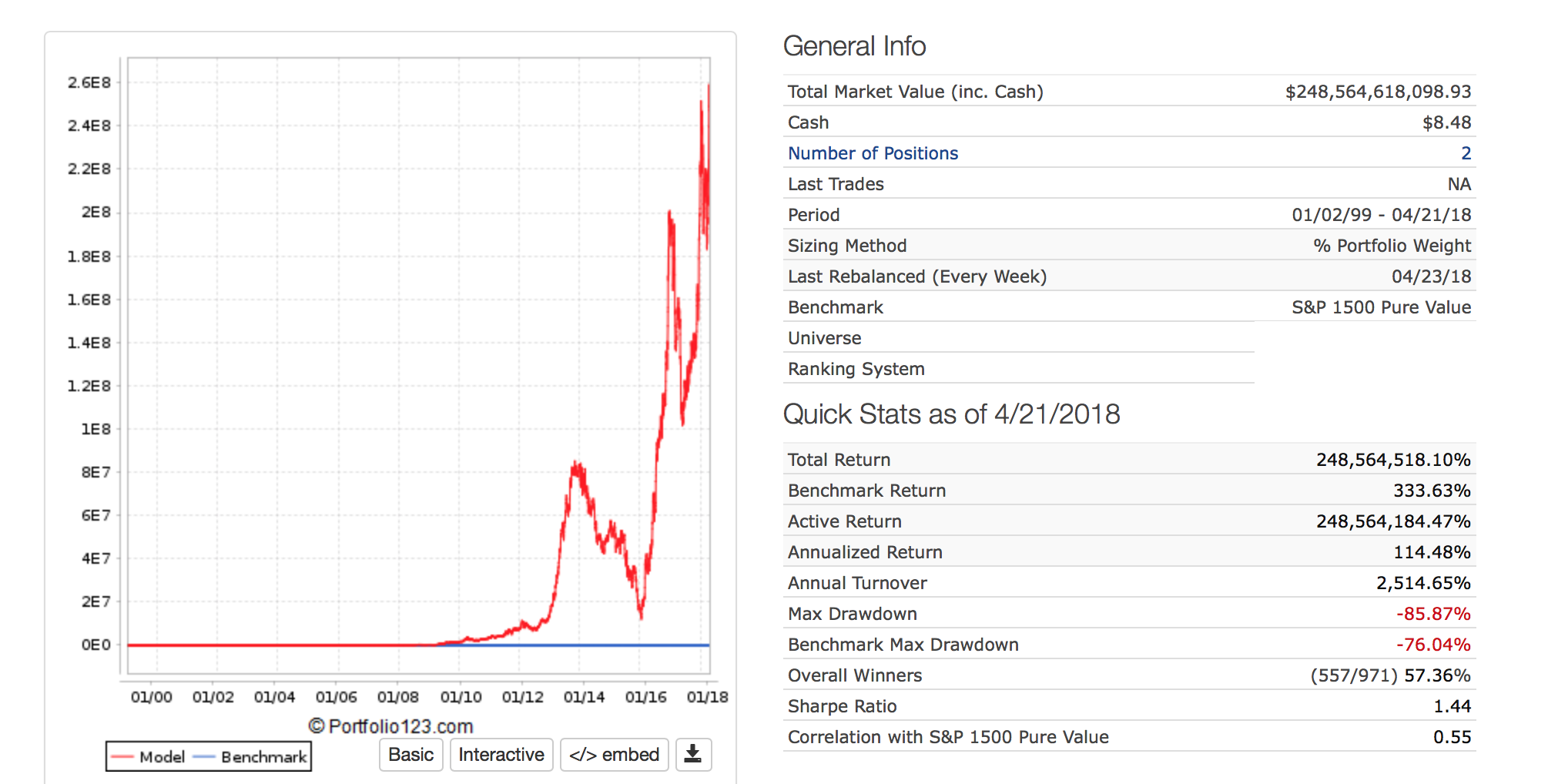
Yuval, here’s a variation of that idea from where I was toying around with your worksheet.
essentially: sets up a return distribution in deciles, with the a possible return segmented for each decile with the only difference being the best and worst decile having different returns. a,b,c have possible worst/best decile returns of -15% or +15% and e,f,g have worst/best decile returns of -10% or +10%. (I put a 1pp growth bias offset shifting the entire distribution by 1pp per period to the right so the actual range is from -14% to +16%, or -9% to +11%, so average expected monthly return is 1%. That variable in a15 can be changed to 0 to create 0% expected monthly return if desired to isolate the distribution shift).
To isolate the random effects, I’ve set the random seeds that select the return decile to be the same for both a,b,c and e,f,g → so the decile inputs will be randomized, but each group sees the identical random seeds for the return lookups. (column a gets same decile seeds as e, b as f, and c as g)
I’m using Excel 2003, so I hope everything translates OK to whatever version folks are using today.
What I find by pressing F2-Enter to keep recalcing is that a higher percentage of cases result in the lower range of monthly variances producing better geometric returns although the average expected return is the same. I did 100 trials and the scenario with lower ranges on extremes (e,f,g) had better results in 55% of cases - and the version with higher extremes (a,b,c) had better results 45% of the time. My initial gut impression was that the % wins for the lower variance version (efg) was higher than that, so unsure if that trial is representative. I can’t remember how to macro that up for longer trial, so that’ll have to do for now 
Anyhow, wanted to share this in case interested.
diversification+simulation+2_variation.xls (53 KB)