@plan_trader: well, yes, kind of. I had a closer look, and by itself, more holdings is NOT a predictor of future performance. But when you use it together with G/S/D it does improve the prediction of future performance significantly. I use the word ‘significantly’ here in the statistical sense, not in the sense that the prediction is a whole lot better.
To be more precise, I used LOG(holdings), which is the natural logarithm of the number of holdings. For 5 holdings, this value is 1.6, for 10 holdings it’s 2.3, for 20 holdings it’s 3. The reason I used the logarithm is that I would expect that going from 5 to 10 holdings adds relatively more ‘robustness’ than going from 100 to 105 holdings for example.
The regression found a coefficient of 10 for LOG(holdings). The way to interpret this is that going from 5 to 10 holdings increases LOG(holdings) from 1.6 to 2.3, and this number should be multiplied by 10 to see the effect on the nnual excess return since launch in percentage points. So for two models with the same G/S/D, but one has 5 holdings and the other has 10, the difference in annual excess return since launch would be estimated to be 10 * (2.3 - 1.6) = 7 percentage points. The difference between 10 and 20 holdings would be 10 * (3 - 2.3) = 7%. So doubling the number of holdings adds 7 percentage points.
However, the confidence interval for LOG(holdings) is approx 2.5 to 17.3, which is pretty large. That means that, statistically, this coefficient of 10 is pretty uncertain. It could be anywhere from 2.5 to 17.3. That means that the impact on return of doubling the number of holdings is anywhere between 2.5 * (2.3 - 1.6) = 1.75 to 17.3 * (2.3 - 1.6) = 12 percentage points. So the statistics are saying it’s kind of relevant, but the exact impact on returns is not very certain.
@hengfu: I also think many models do not have the right benchmark. I did not try to correct for this. If you want to take a more ‘pessimistic’ view on excess returns, I think you can just subtract another 13% from the Ann Excess Launch numbers. The correlation would still be the same though.
Whether a model is worth the monthly fee is an entirely different discussion, and depends to a large extent on the amount of money a sub wants to put into a model (keeping liquidity constraints in mind of course). The question of which model(s) to invest in is indeed more complicated.
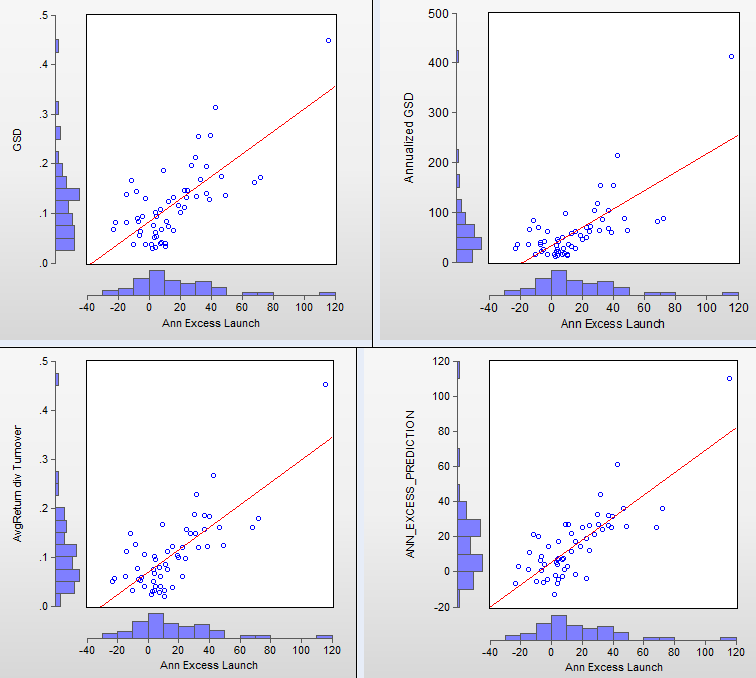
@MisterChang: I basically tested all the factors that are in the Excel spreadsheet that you can download from the page with the list of all R2G models. Specifically, the other factors I looked at are: AVG_RET_LOSERS, AVG_RET_WINNERS, COST, DRAWDOWN, LIQUIDITY, SUBS, TURNOVER, VIEWS, WINNERS, YIELD. I also calculated the average return (both winners and losers) and the number of trades per year.
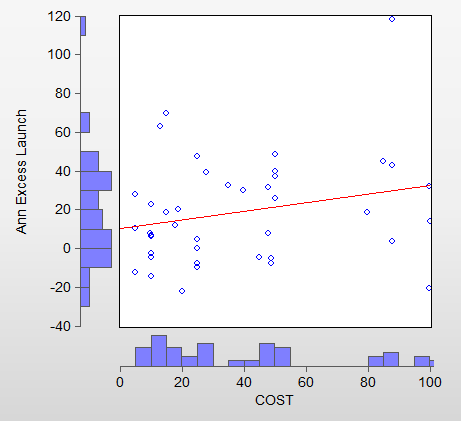
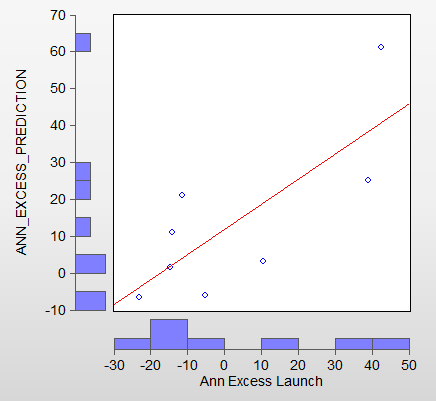
In particular, the cost (monthly fee) has no correlation with out of sample excess returns. This was a bit of a surprise to me. See the attached scatter plot. The red line shows a (slightly) increasing return for higher cost models, but this is not statistically significant. (Btw, I excluded one model with a fee of $250 in this plot).
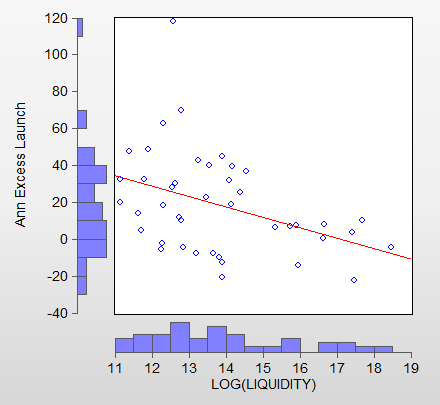
There is definitely a relationship with liquidity, but it’s not a simple linear or LOG(linear) relationship. Lower liquidity models definitely have higher returns, but the scatter plot shows that the points are pretty widely dispersed around the regression line, so statistically speaking it’s not very certain what the exact relation is.
@Tomyani:
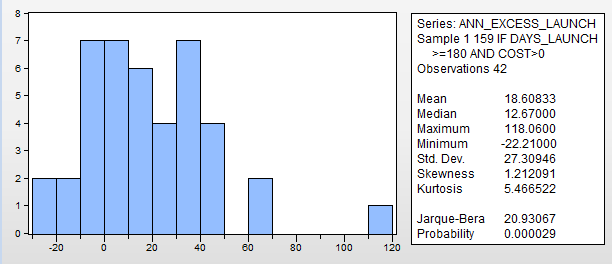
- see attached histogram with statistics
- If I use “liquidity < $1MM and turnover > 750” then the sample only contains 11 models (out of 42). This is really too small to draw any conclusions I think.
- I did not look into trading costs, but I did look at turnover and number of subs. By themselves, they had no predictive value. But turnover is the difference between simple AR and G/S/D, and it’s the reason that G/S/D works better than just AR. The number of subs would only make sense if you include liquidity somehow I think, but I didn’t look into that. There must be better ways to find impact on slippage (which is what I’d be trying to find by looking at subs).
Regarding your other points, all of which I agree with:
3) yes, market timing and hedging have been (barely) triggered, so this could be a very important reason why the correlation I have shown would not hold up in the future. Actually, I was thinking that if R2G models all have very high beta, than the results I got are what you’d expect, but in a down market the models would incur very large losses. Especially if the market timing / hedging does not work out of sample.
5) The correlation gradually breaks down when I include models with more recent launch dates. There is basically no correlation whatsoever for models that have been launched in the past few months. I don’t know whether that is due to random short term fluctuations or the fact that the market is at the same level as it was a few months ago (ie correlation only holds in bull markets because of high beta).
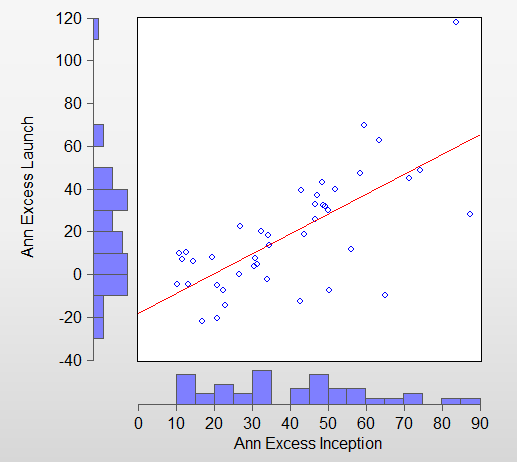
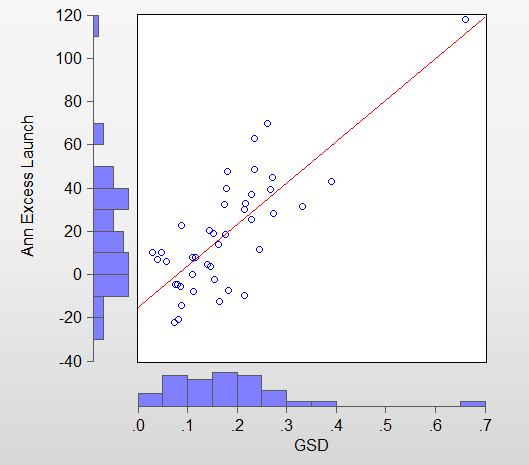
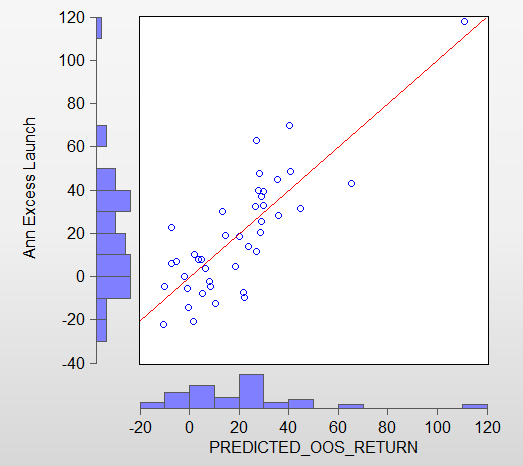
@Jrinne: the slope is near perfect, meaning it’s almost a one-on-one correlation between in-sample and out-of-sample performance. I think the intercept of -44 in my -44 + 234GSD + 10LOG(holdings) can be explained as follows. One part of the intercept corrects for the return of the market (roughly 30% or so). The GSD is a measure of absolute performance, while I’m regressing on the excess returns. The difference between absolute and excess return last year was around 30%. The other part is correcting for the LOG(holdings) component. A model needs to have at least 5 holdings, so every model will always score 10 * LOG(5) = 10 * 1.6 = 16 percentage points “for free”. This is corrected by the intercept. Adding 30 and 16 gives 46, which almost exactly explains the -44 intercept.
@Steve: I used the annualized numbers that P123 reports. Because I only used models that were live for at least half a year, I don’t think this a very big issue, if at all.
Thanks for your insightful comments!