All,
I have been thinking about and discussing with ChatGPT different ways to rank stocks. There may be other ways but P123 is a fine way to do that.
But are we really done after we have the ranks? For now we use a simulation to develop a “heuristic” for what rank or RankPos to sell at. It works ON AVERAGE, no doubt. We can backtest over long periods and find would have worked (again, on average). You have probably seen the positive results in your ports.
For individual trade decisions this is often wrong—for a highly ranked stock with low liquidity and high transaction costs for example. It may not really be in your benefit to pay the transaction costs to buy it and sell a holding that would have done fine (and not have to pay the transaction costs to put it in your port). It tends to even out and works over the long-run. The sims prove that. No debate.
The sims have an estimate for the transaction cost which, perhaps, could be improved or tailored to the amount being purchased. But a sim never makes any attempt to actually calculate the expected returns. That information would not be impossible to incorporate into my decision process now, I think.
I would have to predict returns as well as predict transaction costs with some accuracy (reasonable variance) and low bias for this to work. I note that @Yuval and others have good methods for predicting transaction costs. You can find that in texts also. For example: The Science of Algorithmic Trading and Portfolio Management: Applications Using Advanced Statistics, Optimization, and Machine Learning Techniques
Or use this table from the book. Develop your own table using @yuvaltaylor formulas. Add bid/ask spreads on your own, etc. But Yuval’s formulas are excellent.
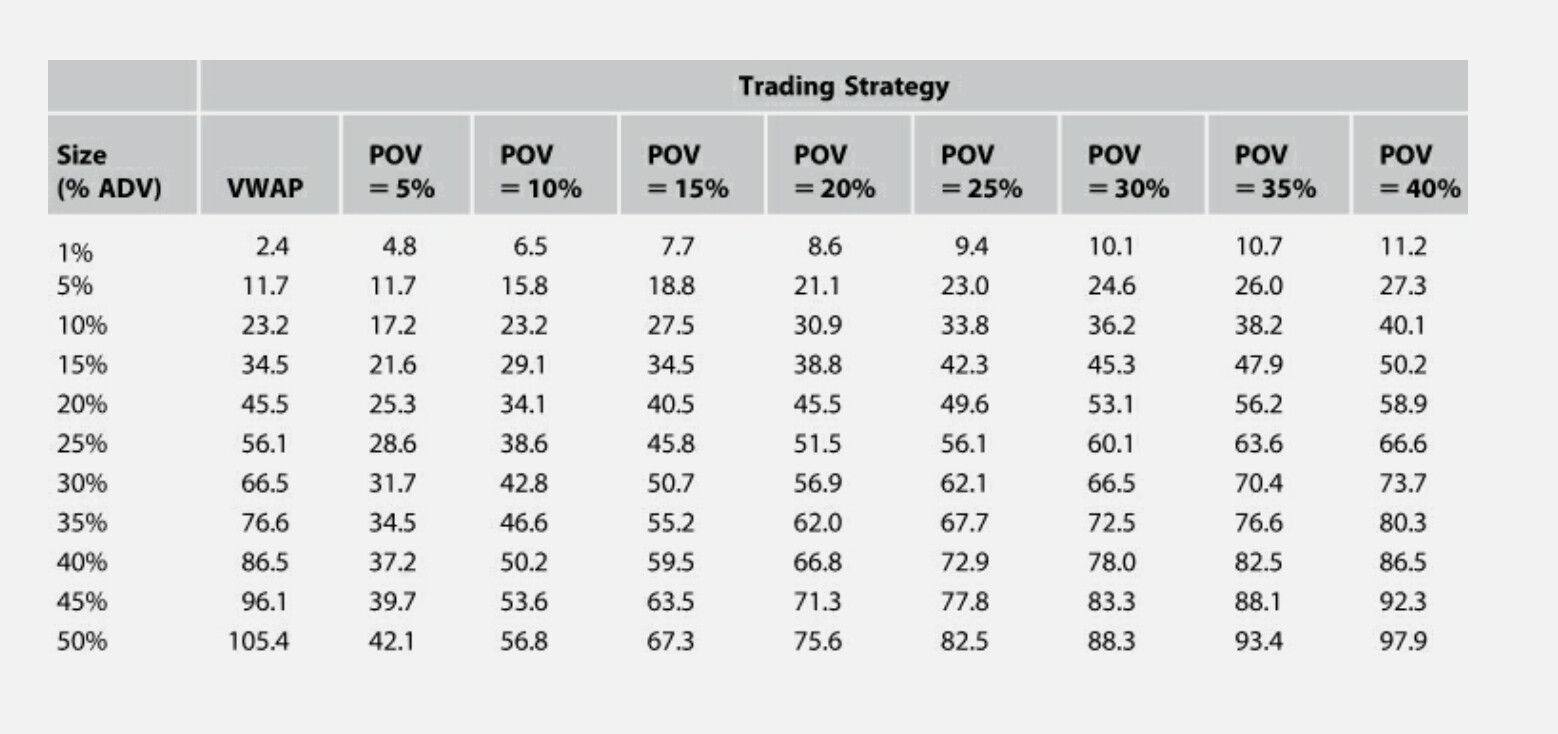
So ChatGPT agrees with my formula on how expected returns and transaction cost can give an exact understand of when a trade is in your benefit. So I just copy that from our discussion: “ExpectedReturnofBuying−ExpectedReturnofHolding−TransactionCosts”
TL;DR: P123 as an excellent method for ranking stocks that has stood the test of time. You could still using machine learning to supplement this ranking information
Ii think it could be done in a spreadsheet once you have the expected returns and transaction cost . I am sure I will at some point.
@marco here would not be a a lot of data or computer resources required to use @yuvaltaylor transaction cost calculations with the higher-ranked stock (with whatever methods one decides to use for expected returns using P123’s AI/ML).
At the end of the day, it is just subtracting 2 times after using whatever method you find useful to get the expected returns and transaction costs first. Seeing if the number is greater than 0 or above some threshold. For now, I could probably figure out an elif (or simple if/else) for that when I get tired of using a spreadsheet. Maybe loop over several iterations of different ticker combinations. Using @showvar in the screen to get the transaction cost or incorporating the data in an API download. Doable and probably useful for me.
ChatGPT simply says “……integrating a Boolean condition based on expected differential returns and transaction costs is an effective way to make data-driven trading decisions” which may be clearer that what I wrote.
Jim