Dear All,
As mentioned before we are working on extending our tools by creating an environment where "apps" can run (created by us or the community). @AlgoMan is working on one here: AlgoMan HFRE v2.4 — Hierarchical Factor Ranking Engine (Download). His app right now requires you to download the dataset. Our app can also run internally, so it has a few more advantages.
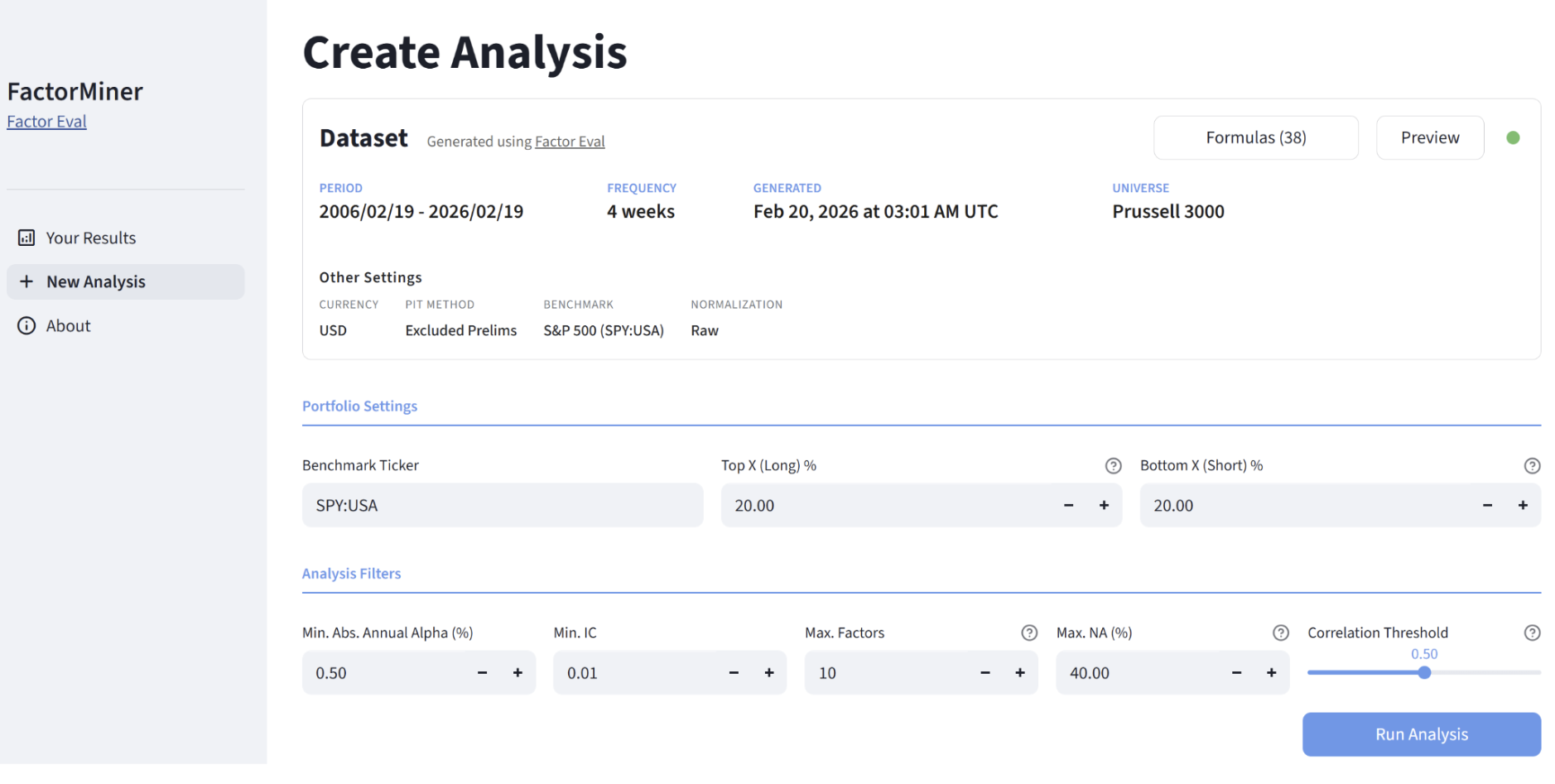
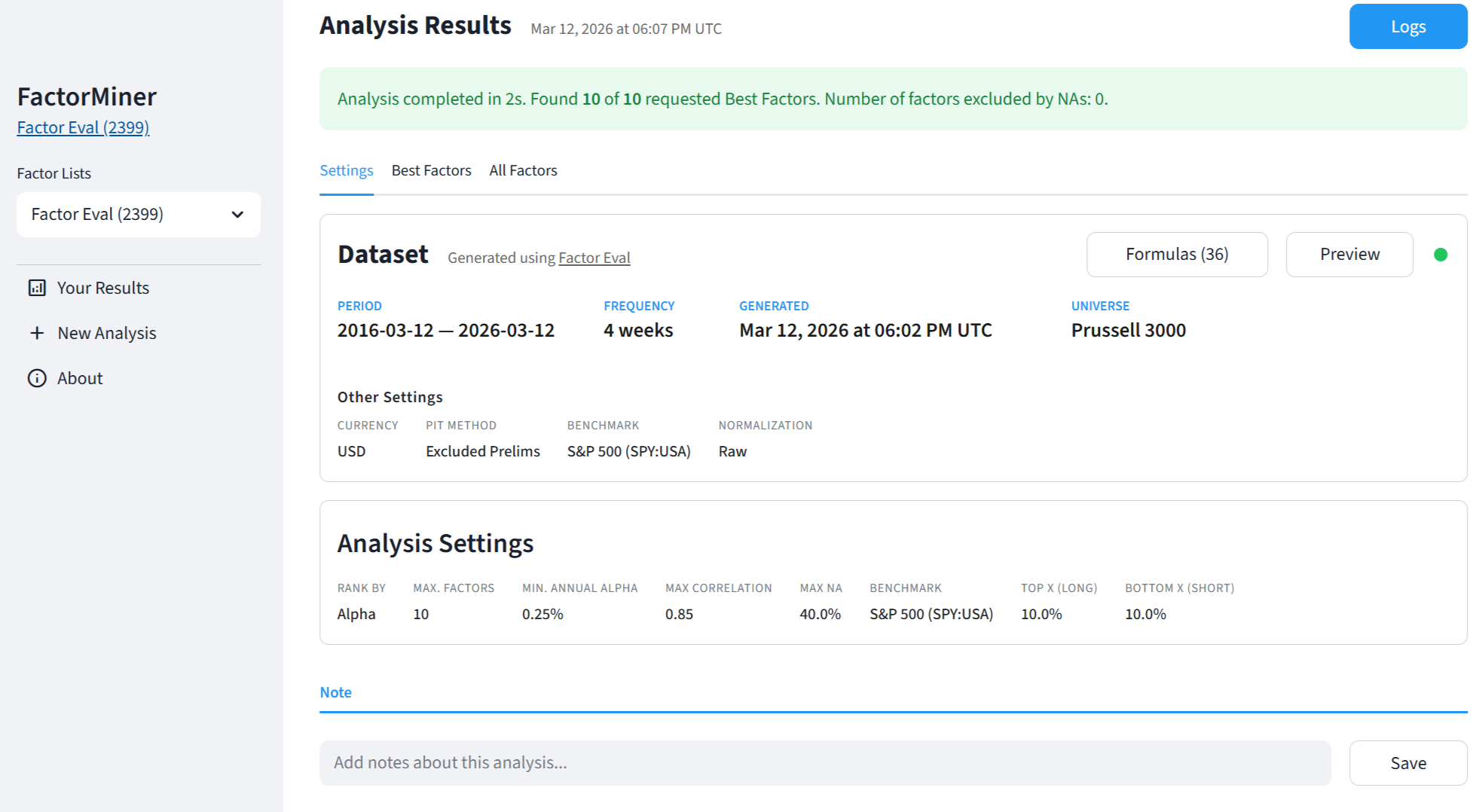
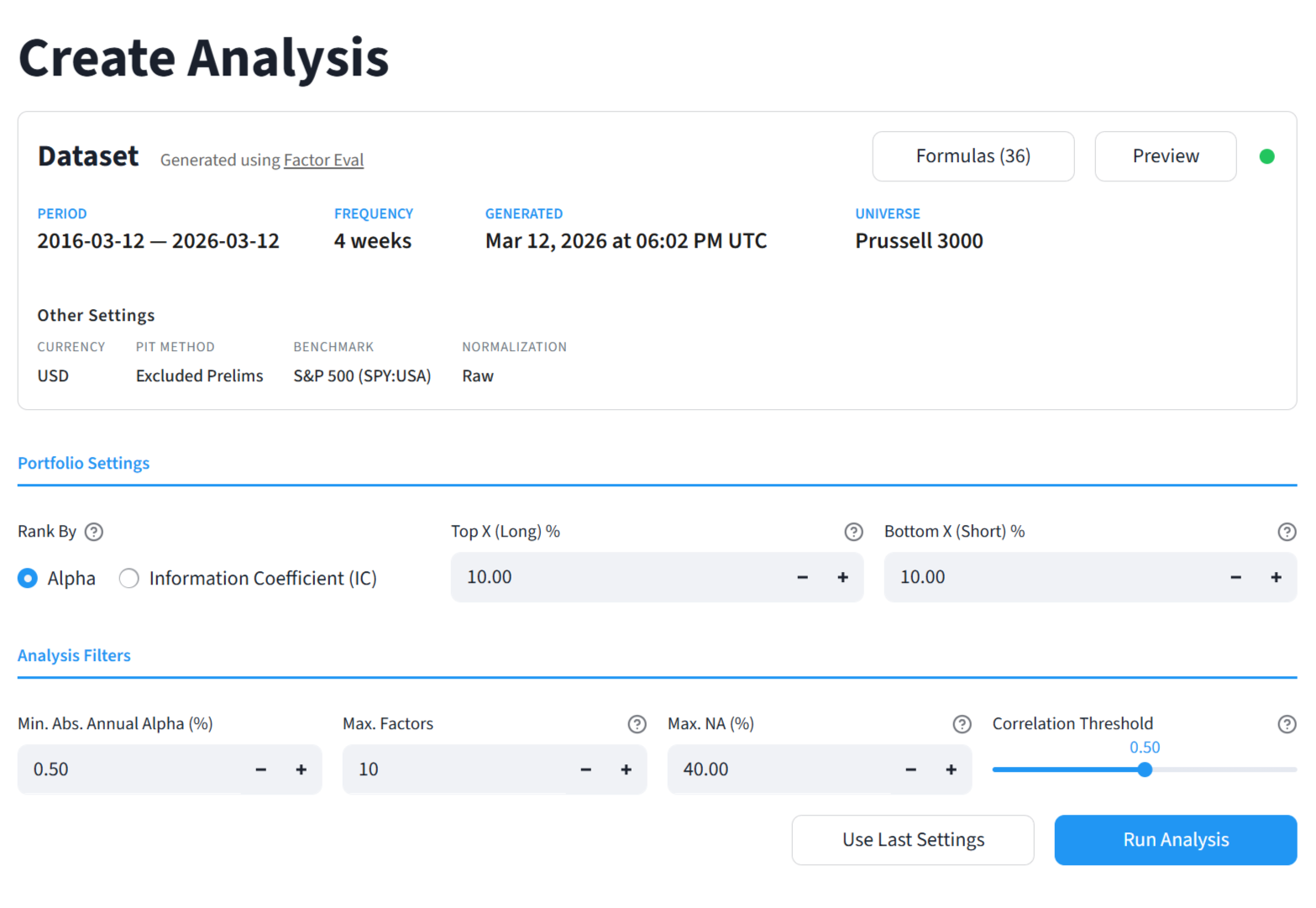
Ours first app is very modest. It runs long/short portfolios for each factor and reports the best "N" factors that pass your filters (min alpha, max correlation, etc). Here's a preview of the results for a use-case I had. I think it's really useful, runs really fast and produces actionable results. The app has several other neat features. We hope to release it early next week.
Looking forward to your feedback.
Cheers.
Use case
I want the "best" 10 factors from this list
- Buyback Yield
- Earning Yield
- Earnings Yield Incl R&D
- EV to Sales
- Price to Sales
- Price to Book
With all these normalizations:
- Cross sectionally (for each date)
- Within the sector
- Within the sub sector
- Relative to previous 1Y values , then cross sectionally
- Relative to previous 1Y values , then within the sector
- Relative to previous 1Y values , then within the subsector
For a total of 36 different factors normalization permutations
Results
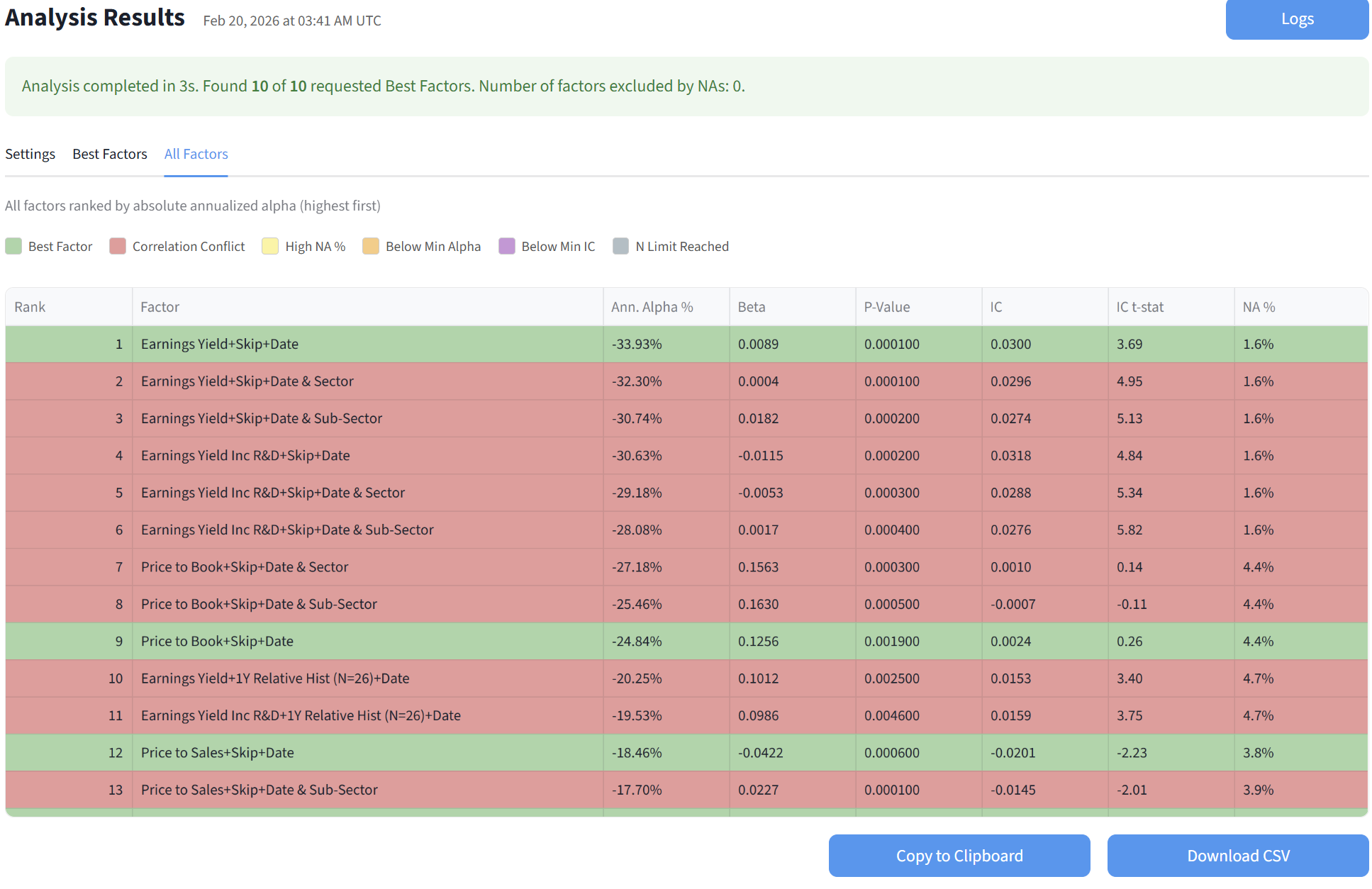
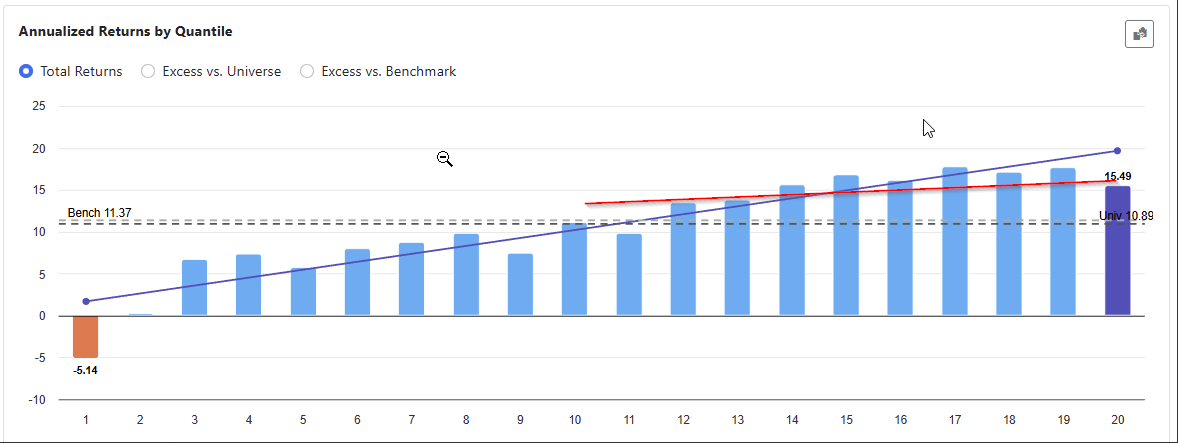
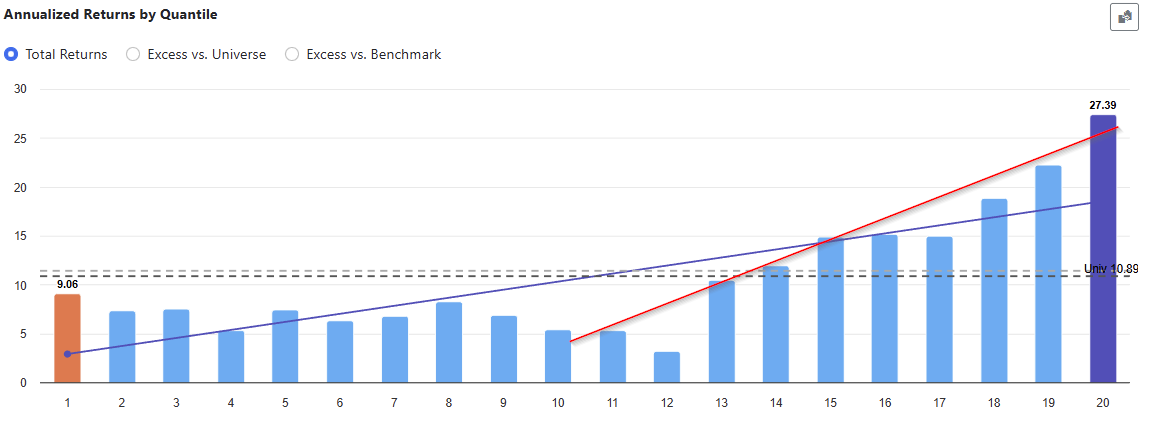
I fed the dataset to our new app for the past 20 years, every 4 weeks for the russell 3000. I set up some restrictions and produced these results in a matter of seconds.
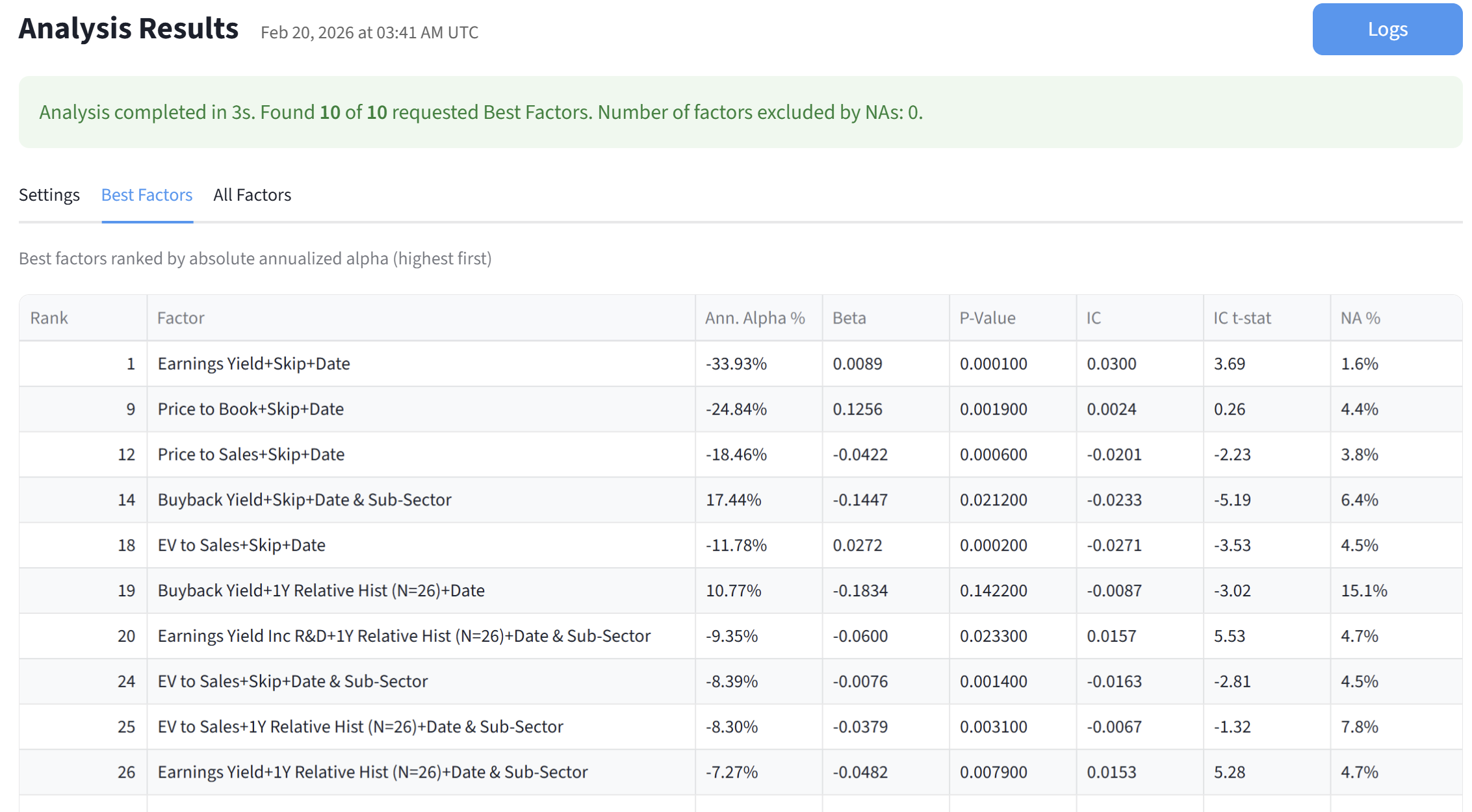
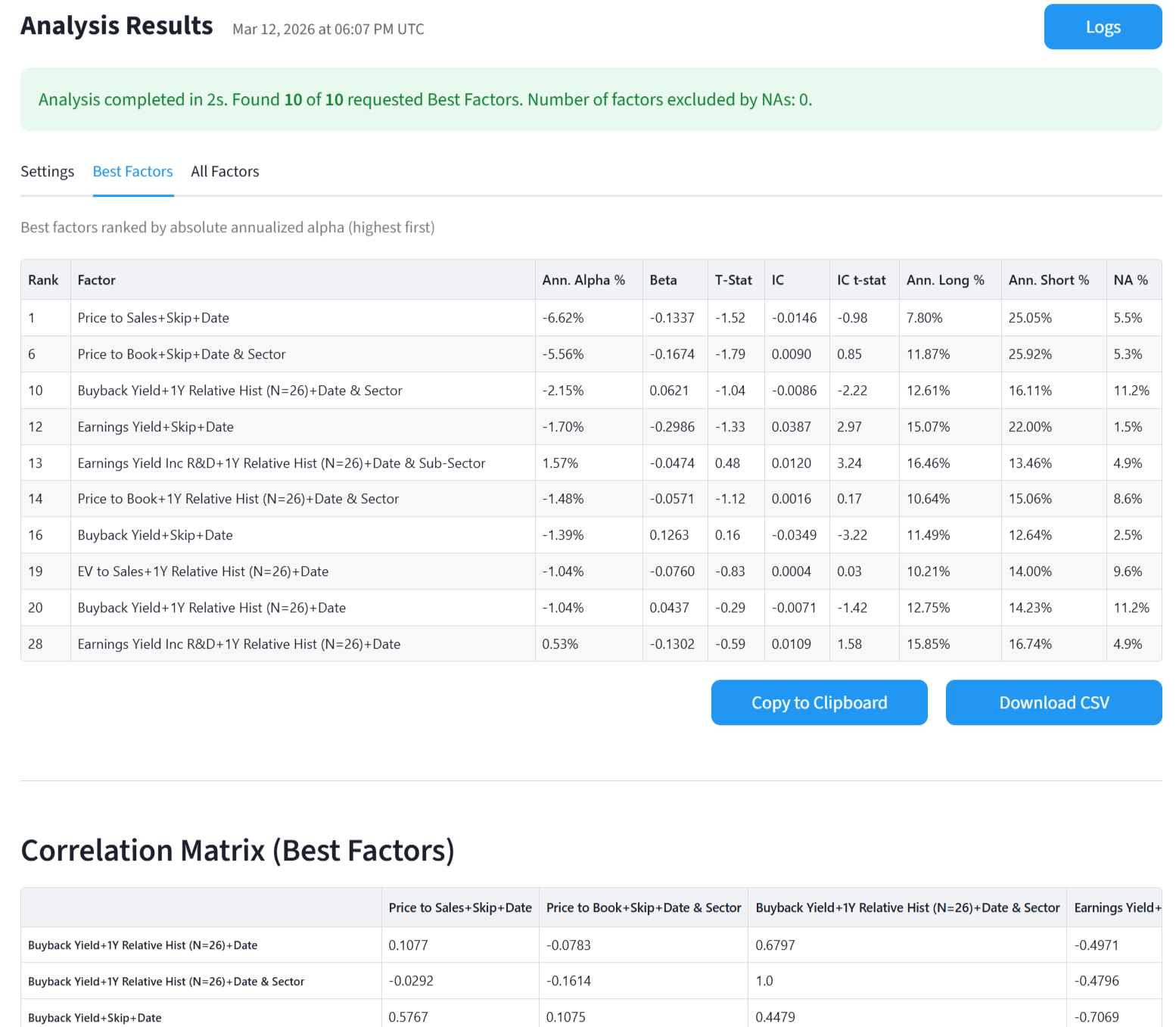
As you can see the best factor is "Earning Yield" normalized cross sectionally (in a ranking system this would be "vs. the Universe").
Factors 2-8 are skipped due to the restrictions I imposed. The next best factor is "Price to Book" also normalized cross sectionally.
And so on. The fourth "best factor" is the first one normalized vs the SubSector. Earning Yield appears several times with different normalizations, including relative to previous historical values (for example is the stock trading at a high earnings yield vs it's 1Y history)
It's good to see that the alpha signs appear correct. Only one of the factors has a +ve alpha, Buyback Yield, since "higher values" are usually better for that one. All the others, lower is better, so the short portfolio does better.
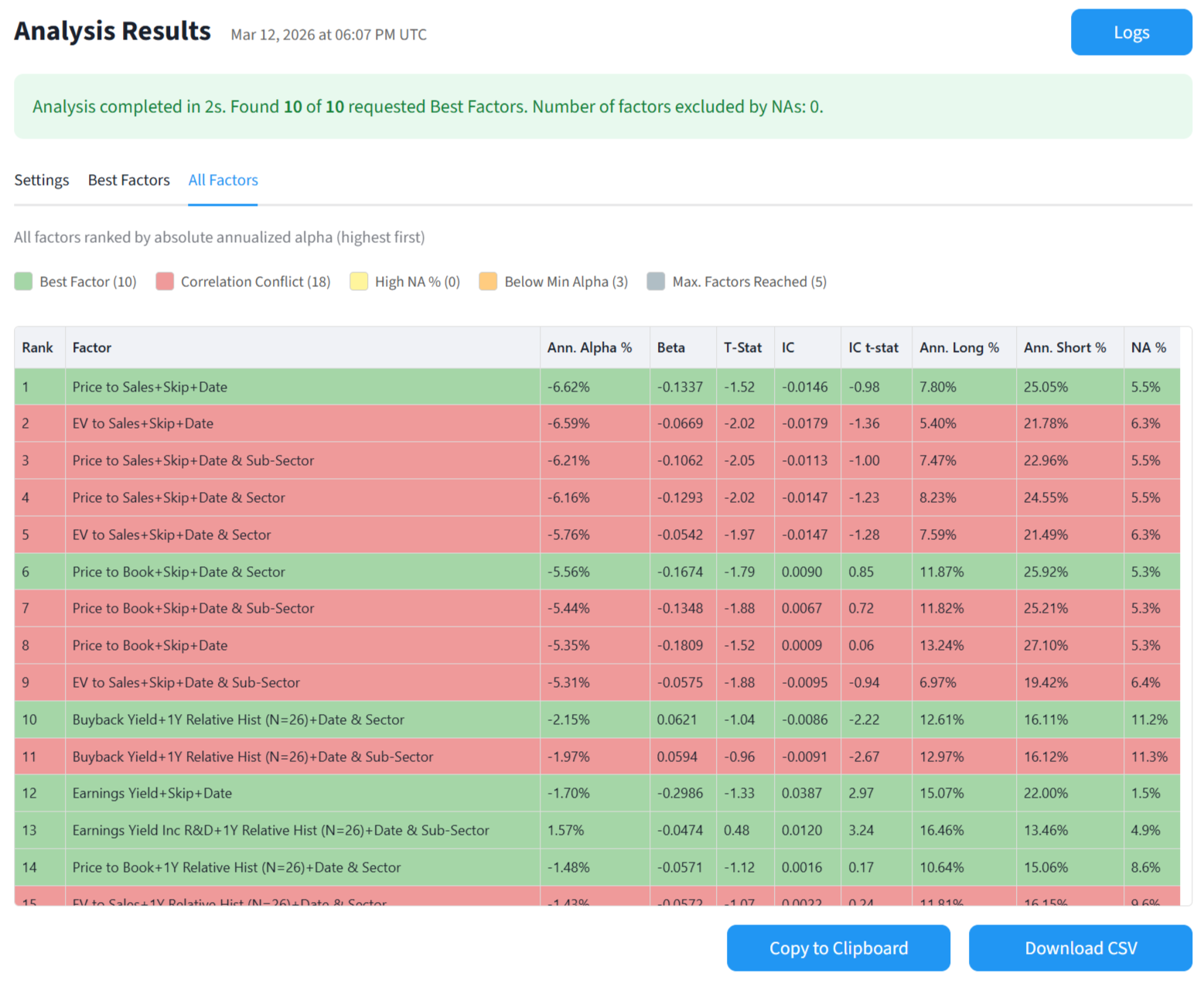
Results: All Factors
The app also shows you all the factors and the reasons why they were excluded