Some of you followed the earlier thread where I was developing a Hierarchical ML Factor Ranking tool (original thread). That was more of a development diary — the app has changed quite a bit since then, so I'm starting fresh with the release version.
Download: https://drive.google.com/file/d/16XTP2E-snSnD8koiCNOKQ_t0lsrrBPaQ/view?usp=sharing
What is HFRE?
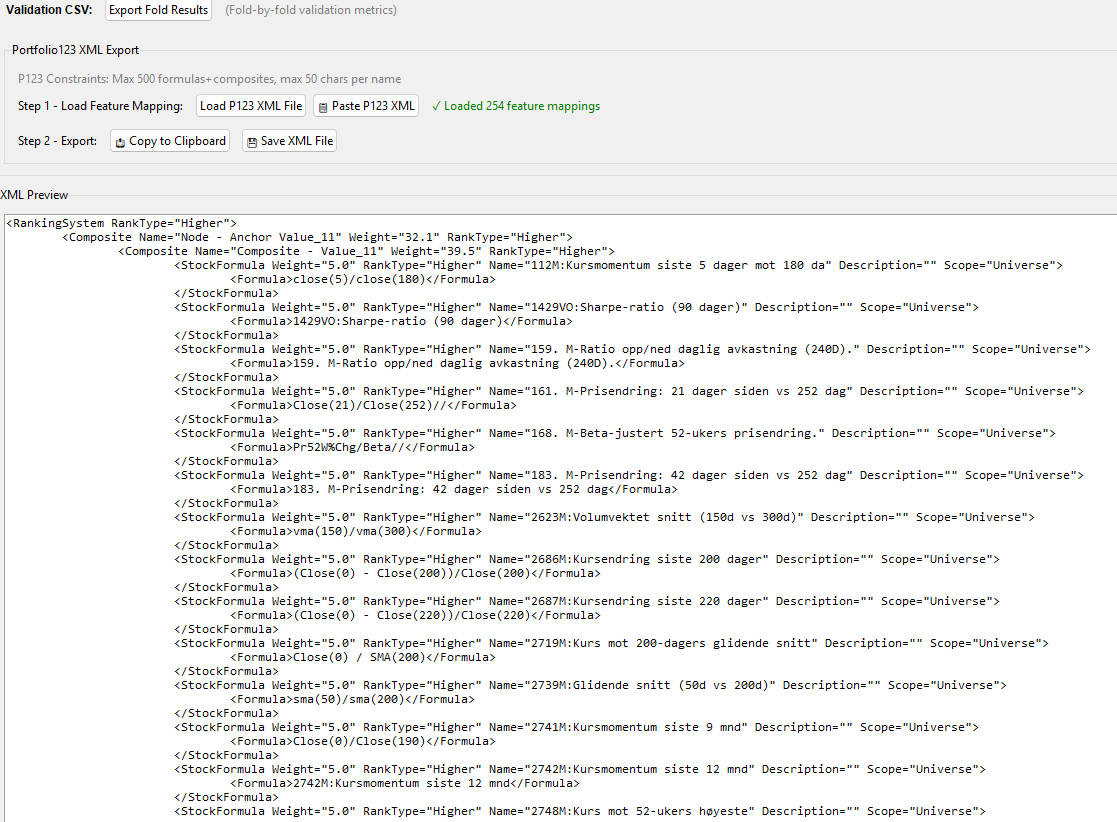
HFRE builds a Portfolio123 Ranking System using a structured, two-layer linear hierarchy — then exports it as XML you can paste directly into P123.
The core idea hasn't changed from the original thread: standard linear ML ranking tools suffer from lack of structure (we lose the ability to build meaningful composite nodes) and factor over-concentration (the model tilts heavily toward one factor type). HFRE addresses both.
Important: HFRE is not designed to produce the highest possible back-tested returns. The focus is on building ranking systems that reproduce out-of-sample — models you can trust in live trading rather than ones that look spectacular in hindsight.
How It Works
Layer 1 — Nodes: Each node has an "anchor" factor (your core signal — momentum, value, quality, etc.) paired with a handful of support factors. Think of each node as a Micro-Strategy — a small, constrained linear model focused on one theme.
Layer 2 — Meta Model: A constrained linear model combines all nodes into a final ranking score.
Because both layers are linear, the entire model transpiles directly into a P123 Ranking System via XML. No black boxes — you can inspect, backtest, and manually tweak everything in the P123 environment.
Workflow
- Load Data — CSV from P123 Factor Download (rank-normalized, weekly)
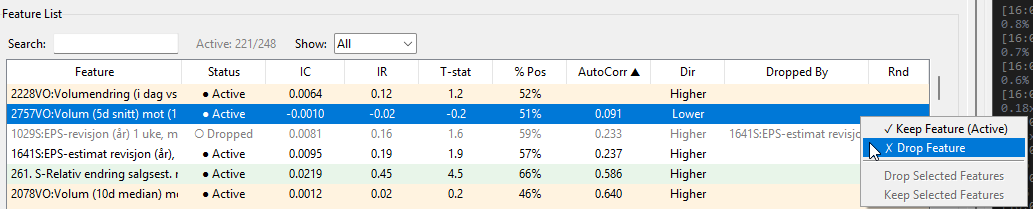
- Feature Quality — IC analysis, automated reduction of noisy/correlated features
- Direction Verification — Confirms Higher/Lower direction for each factor
- Feature Bundling — Groups correlated factors into composites (with interactive dendrogram)
- Anchor Selection — Pick your core factors using MMR (balances signal strength vs. diversity)
- Validation — Walk-forward Time Series CV or Basic Holdout with full fold visualization
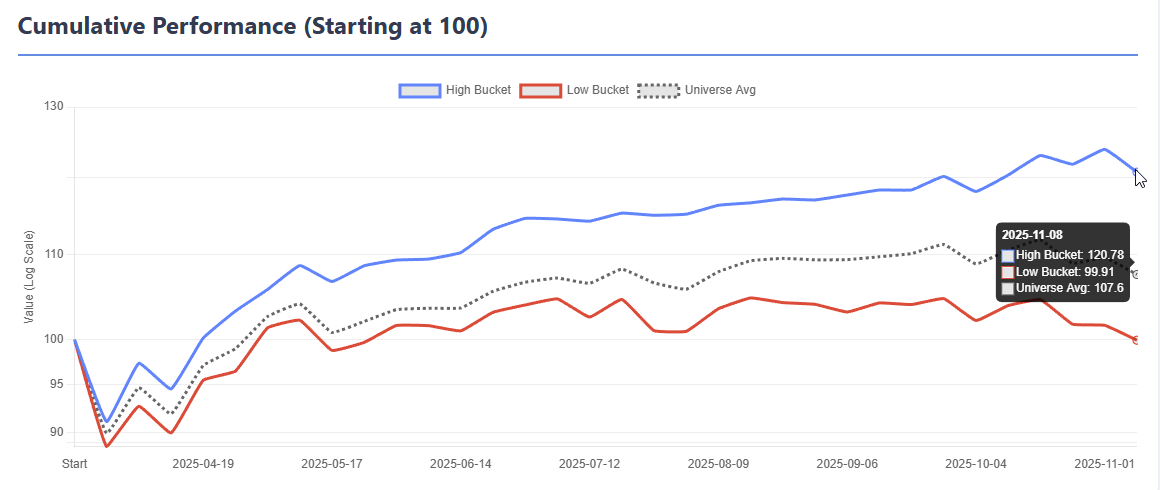
- Results — Bucket returns, performance metrics, turnover decomposition, stability analysis, and an HTML report that can be saved as reference
- Production — Train final model on all data, export XML, paste into P123
Not every step is mandatory, there is a bit of redundance in the workflow because how new ideas was integrated to the app in the development process. You can skip Feature Bundling, jump past steps, or even run it as a simple ElasticNet model without composites if you just want to test specific functionality like the Top Decile Focus. The app is flexible — the workflow is a guide, not a straitjacket.
A Few Things Worth Mentioning
Turnover awareness: Turnover is addressed at multiple levels. The Anchor Selection tab has a Min AutoCorr filter that blocks high-turnover features from becoming anchors. The Results tab includes a full Turnover Decomposition that breaks down which features are driving portfolio turnover, so you can identify and address the worst offenders. Feature Bundling also helps — composites built from multiple correlated features tend to have more stable ranks than individual features.
Anchor Diversity + Residual Weighting work together as a feedback loop during node building. The diversity slider controls which anchor to build next, while the residual weight controls how much of each node's prediction is subtracted before the next node is built. Together they ensure each node captures genuinely different signal rather than piling onto the same factor type.
Top Decile Focus lets you weight the loss function toward the top bucket — useful for long-only strategies where you only care about the stocks you actually buy.
Non-negative meta weights prevents the model from going short on any node, which improves stability. I strongly recommend using Non-negative weights, that is one of the reasons why I spend quite a lot of effort to find the correct directions of the features in the app.
Please check the help menu before asking questions — I've tried to document everything including defaults, thresholds, and what each setting actually does.
Beta
This is a beta release. To be honest, I have spent far more time building the app than testing it. I've only run it with one dataset myself, so there will be edge cases I haven't hit. If something breaks or behaves unexpectedly, let me know and I'll try yo fix it.
I'm neither a professional software developer nor an ML expert — I build these tools as a hobby. That said, a lot of thought and effort goes into them. If you find the app useful and want to say thanks — you can buy me a coffee ![]() buymeacoffee.com/algoman
buymeacoffee.com/algoman
I've been asked about releasing the source code. I'm generally hesitant — I've had bad experiences in the past where code I gave away ended up being commercialised by others. For now the app is free to use but closed source.
Looking forward to hearing how it works with different datasets, strategies an settings.