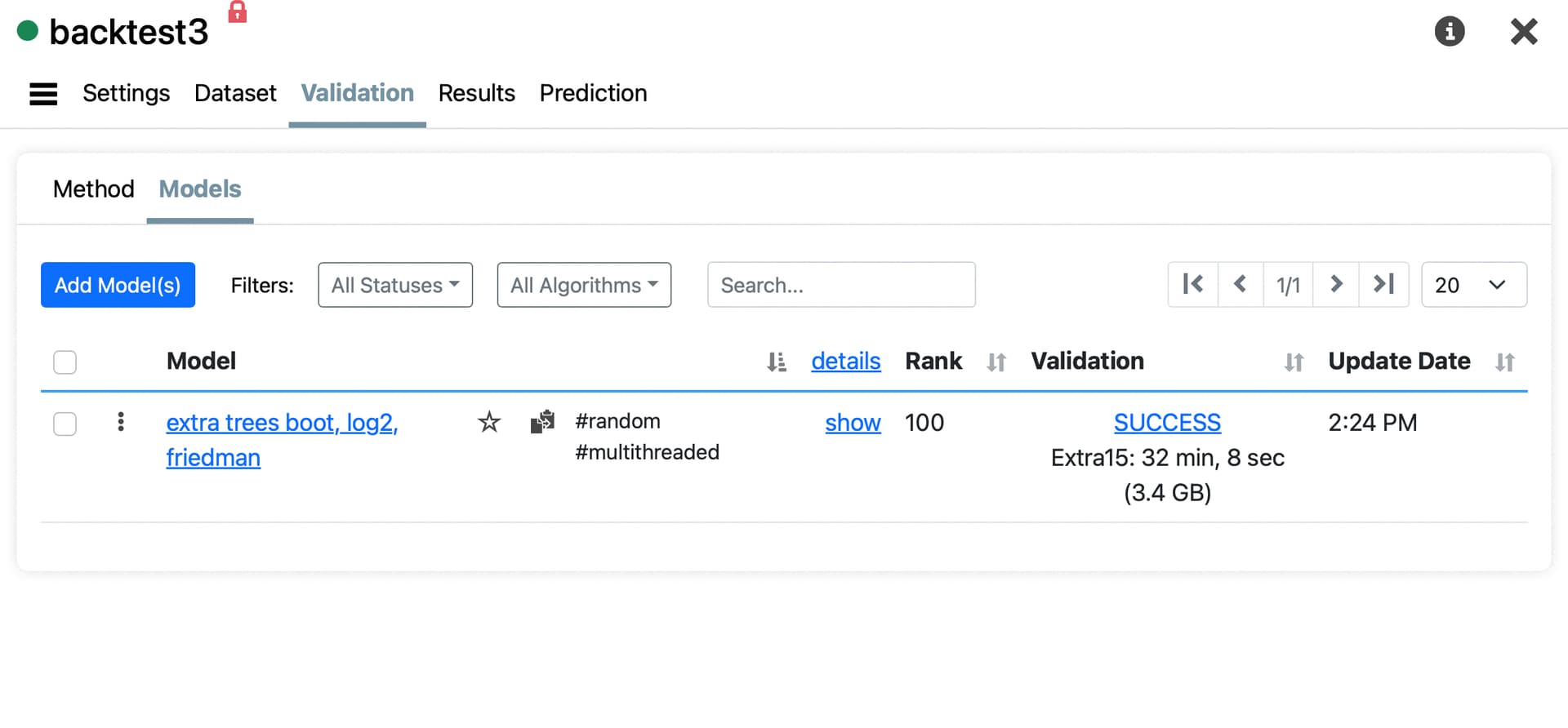
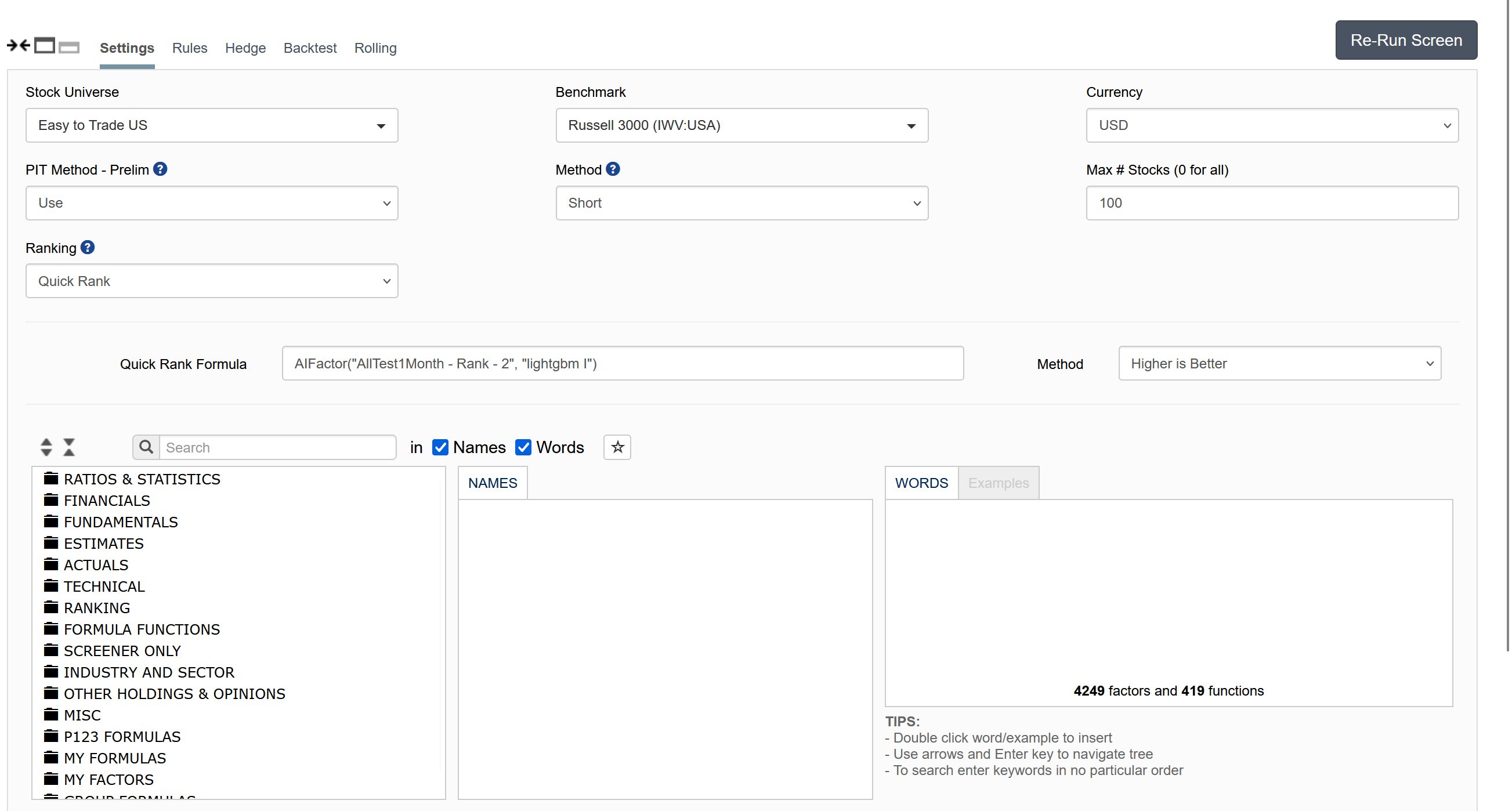
Thanks for getting back to me! I did take a look and ran some tests, but my results aren't quite matching up. Could you share your screener results that reconcile with the portfolio outcomes, like the one I posted above? Maybe I'm doing something wrong? To ensure I'm communicating clearly, I'm not looking for nice looking simulations, I'm looking for numbers that reconcile with the various AI results.
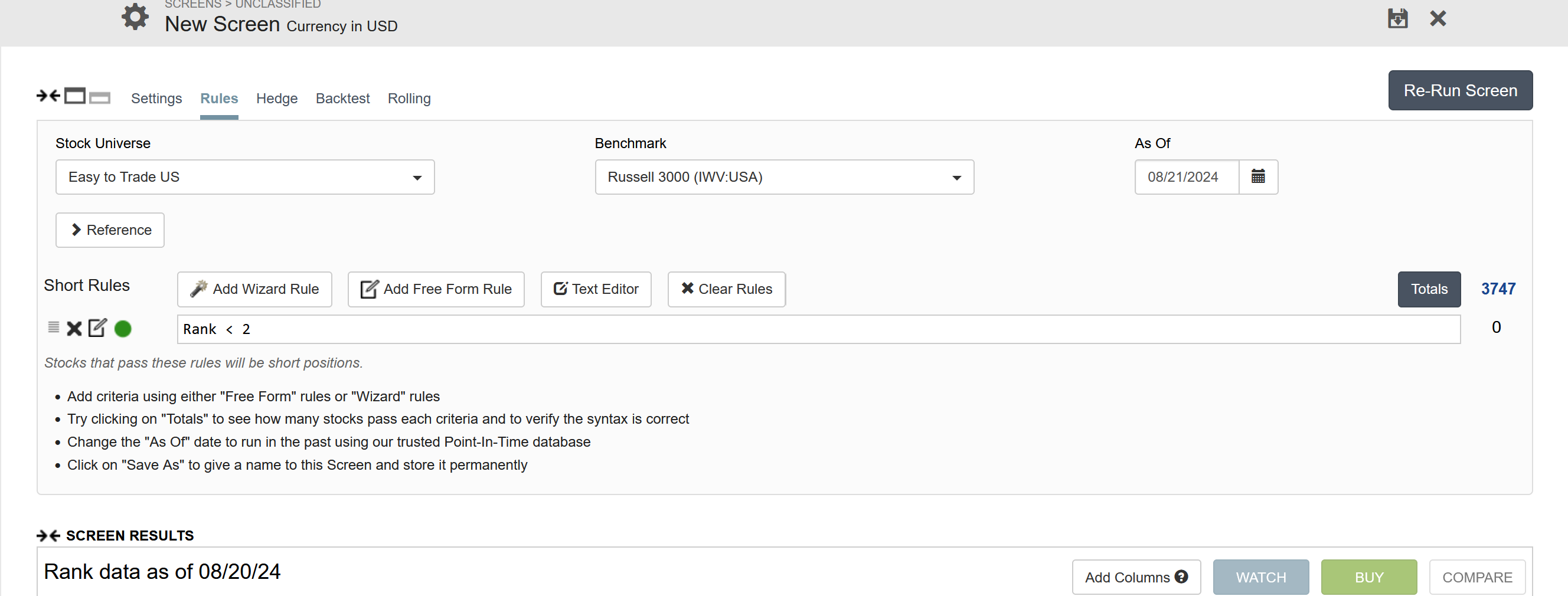
I also noticed that when I screen for ranks <5 (using the new link provided), it returns 0 stocks, which seems odd since the portfolio performance section in testing or validation shows stocks in those categories.
Lastly, @marco, I noticed that backtesting in the screener is now limited to just one year historically. If you're integrating AI features with the screener, it would be really helpful if they connected with the simulation feature too, since it's promoted as the best way to understand real-world outcomes of a ranking system. Also curious why you decided to limit the testing to 1 year - that is not reassuring for research purposes.
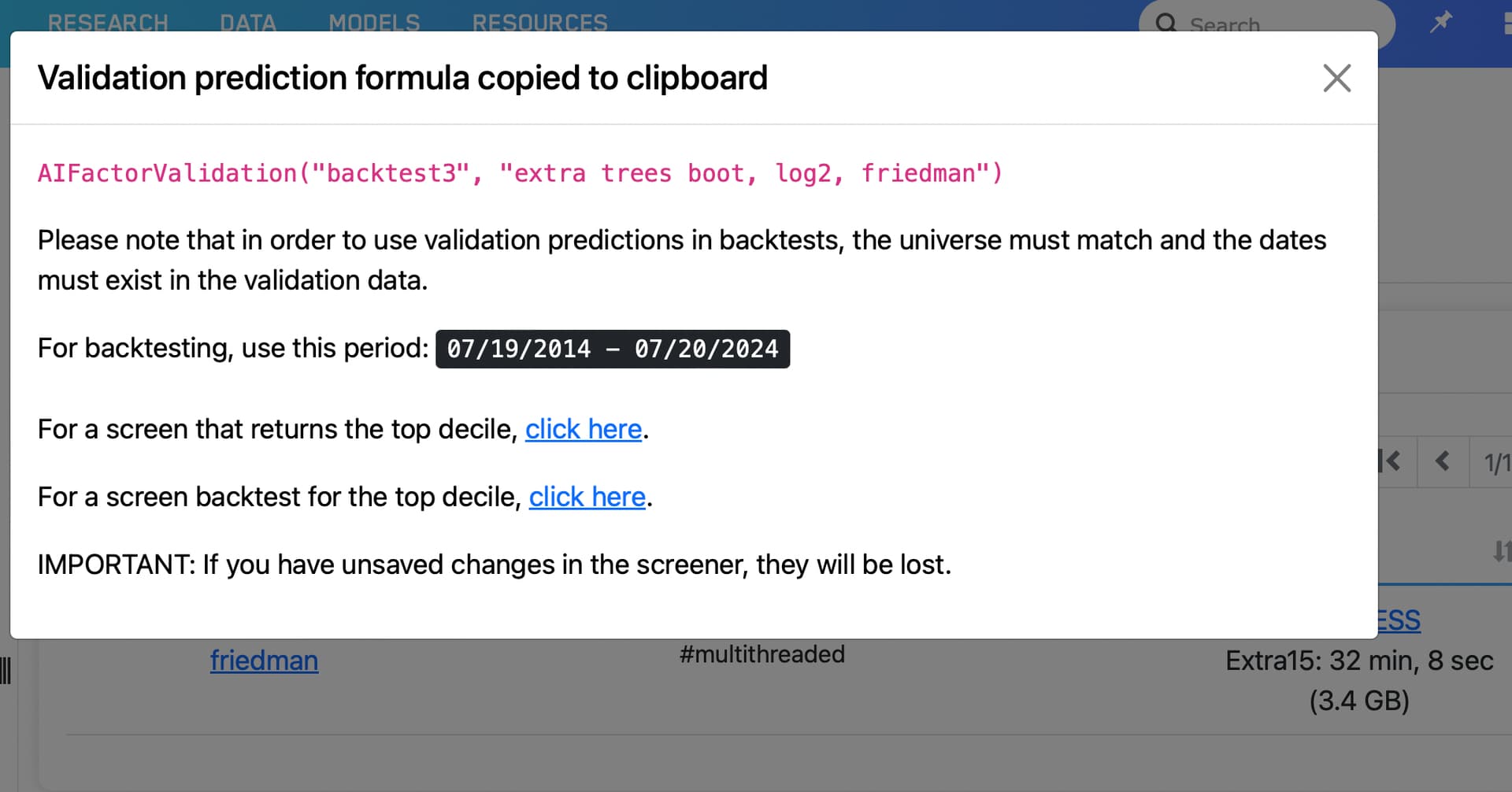
For long backtesting with AI factors you need to use the new function AIFactorValidation(). It uses saved predictions made during validation and it's very fast. Predictors should only be used to predict in the present. We allowed up to 1 year for more flexibility.
ALSO
Rank < 2 is problematic with Quick Rank since stocks that have too many NA's in the features (30%) will get the lowest ranks, but in AI Factors they are discarded. So the results will not match.
To match exactly you need to:
Create a new universe
Set the starting universe the same as the AI Factor
Add a rule in your universe to kick out stocks that had no predictions in the validation like this: AIFactorValidation("AI factor name", "model name") != NA
Another option is to not use Quick Rank and create a ranking system and set the Ranking Method to "Percentile NAs Neutral". This will produce better matching results (but not exact). We'll make some changes to Quick Rank that will give exact results to the AI Factor.
These new features are incredibly helpful in aligning the AI Feature results with the screener—I'm pretty satisfied with that part.
However, much of the AI results I work with rely on Long/Short portfolios, and I've noticed, just like with the original ranking models, that it's tough to generate alpha to outperform the indexes unless you're trading very small stocks (net of taxes and transaction costs). Kudos to @yuvaltaylor for successfully leveraging small companies for this purpose. I know it’s still possible, though it requires quite a bit of effort.
That said, I’m hoping someone could guide me on how to create a short portfolio in the simulation to replicate the AI Factor results, or better yet, a long/short simulation. A step-by-step reference on creating a short simulation that reconciles with the screener or AI results would also be extremely helpful. My results consistently show higher volatility and higher beta shorts, so I need to rebalance the portfolio to achieve a beta of 1 or 0.
Any guidance you can provide would be greatly appreciated.
Nonlinear machine learning models are particularly good at trading in microcap stocks. And the best machine learning models for large cap stocks published in papers so far are linear models. So I don't actually consider trading in large cap stocks. I will consider this if and when I have at least tens of billion dollars. Until then, it takes too much effort compared to the gains, at least relative to trading smaller stocks.
I am also interested in how to implement shorting models in the p123 system. Because, at least in my experience, these models always produce strange results in tests.
It's hard to know the availability and costs involed shorting micro/small-cap stocks. So the backtested results here wont give you a realistic picture of how the strategy would have performed live anyways.
This is a major problem with shorting models. Their profitability is extremely dependent on shorting fees. Shorting availability is a lot less important than fees because you can synthesize short positions with options.
Variable margin limits are also severe. I tried shorting MAXN a while and then realized that my purchasing power was greatly reduced. The amount was much more than the value of my shorting position.
Despite the fact that there is actually pretty good shorting cost data already available from 1996 or earlier, p123 apparently won't be sourcing that data due to lack of demand.
Thanks for sharing your insights on trading models and the challenges with shorting.c The concerns raised about shorting fees, availability, and margin limits are real - just as real as market impact in trading micro-cap stocks. But keep in mind that you earn the cash rate when you short stocks which is now over 5% and looks to non-zero for the foreseeable future.
I appreciate the points you've made. However, my current focus is on reconciling the AI Factor high-low results with the simulation feature, as it directly impacts my ongoing analysis in terms of the value of the AI Factor feature.
I can be wrong, but i think shorting is really only feasible long term by using put options. Thats the only way you have upside>100% and downside limited to 100%, otherwise 1 single stock can blow up your whole portfolio, regardless of how small you size it. And over the course of many years, someday you will get that black swan event that kills all your short alpha.
Yuval's blog posts on that matter are really good. But since we don't have historic option pricing data, it will be very hard to backtest. So what we really need to make it work is backtest with options data?
Market-neutral funds primarily short stocks directly. However, it is true that options may be more appropriate when shorting microcap stocks and volatile smallcap stocks like AMC. And, you pay more for the protection of options, especially in stocks that are suitable for shorting (small, volatile & unprofitable) , which further hurts the profit potential of your shorting strategy. I had a option selling strategy so I knew it. I profited a lot from selling options of those stonks.
However, if this can be overcome, it may be possible to take advantage of the fact that nonlinear machine learning models are better at predicting the short side.
There is now publicly available options data since 1996 for sale. This also means that we have access to shorting cost data since 1996. But I don't think p123 will bother with that if there isn't enough demand for it
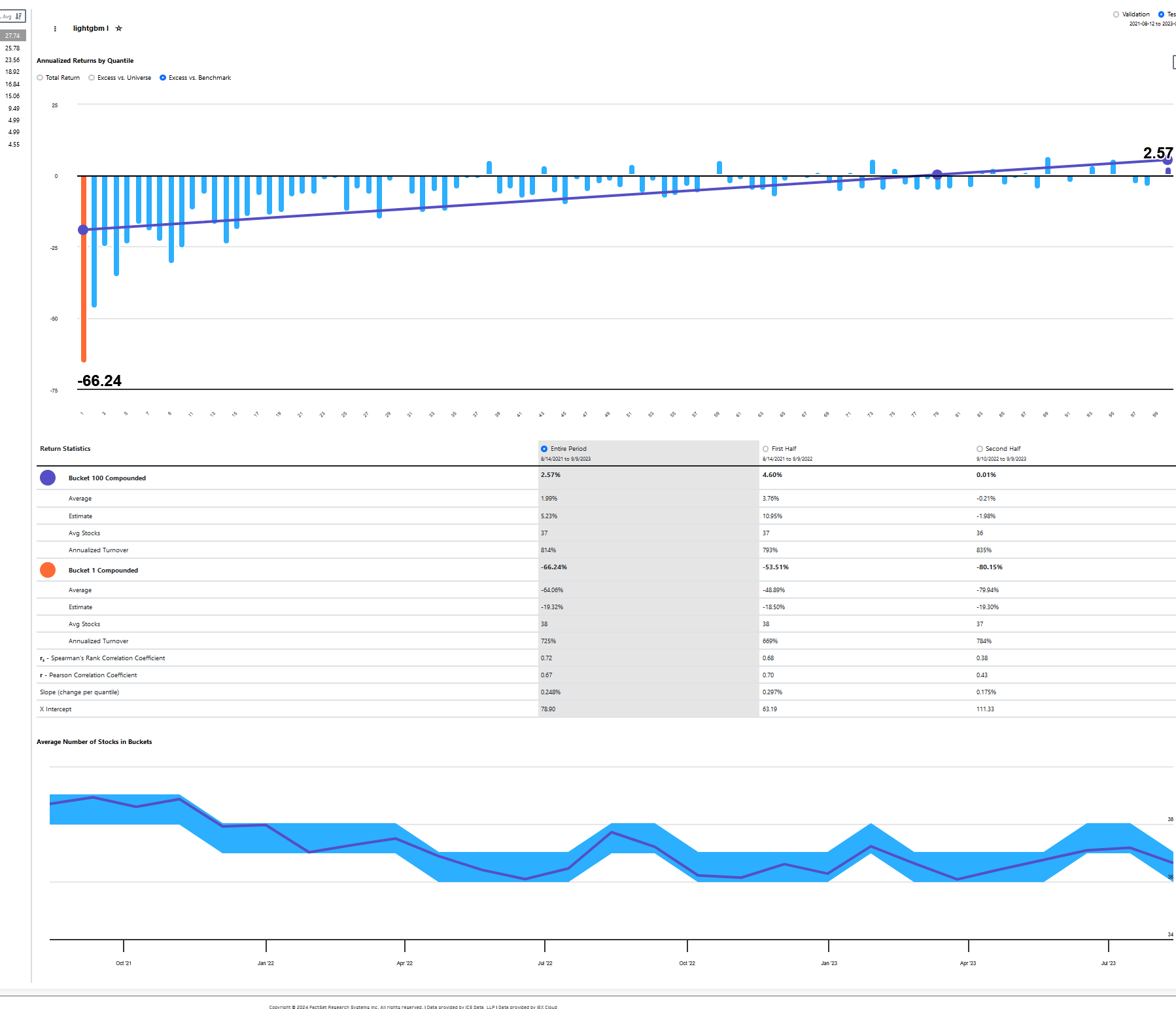
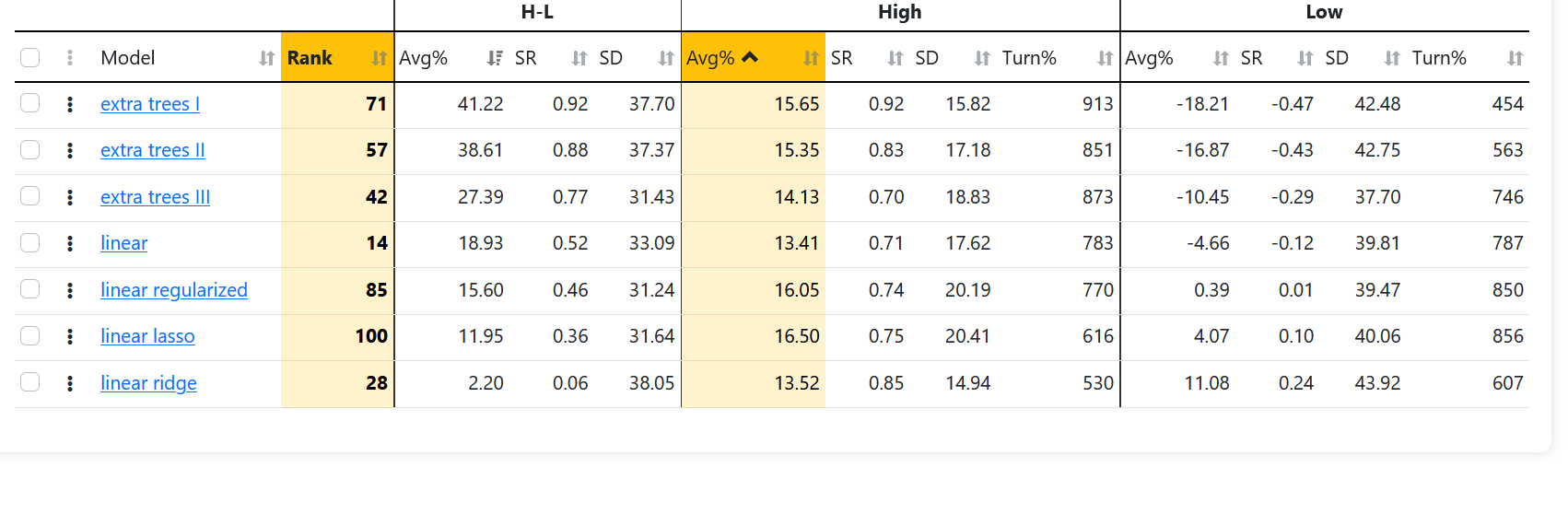
On a related note, I've notice that the averages for hi and low do not reconcile. They are close however. Does anyone know what's going on here? For example, the first row the hi is 15.65 the low is -18.21. Therefore, the h-l avg, I think, should be 33.86 (15.65- (-18.21)).
I have actually bought some basic option data for about $500 to test some strategies that uses Portfolio123 data as its starting point to chose the companies to buy put options on.
What I found was that I couldn't find a strategy that made money structurally. In the 20 year period I tried it on, there were many 10+ week streaks of all the options going to 0. However, at other points in time (usually when the broad market indexes did really poorly), the strategy would do good. I thought it was hard (read: I didn't manage) to find a strategy that was actually profitable over the whole time frame.
This was with very cheap data of course, that was pretty rough around the edges. What I took from it was that (with my understanding at the time), I could expect to manage market risk, but shouldn't expect to greatly improve my returns.
A shared function which produces annualized portfolio metrics is used to derive Avg%, SR, and SD from period returns for H-L, High, and Low. H-L period returns is simply the result of subtracting Low period returns from High period returns. You can see the H-L portfolio on the Portfolio Results page by pressing the gray circle to the left of High − Bench and changing it to High − Low.
Thank you for the explanation. Could you please clarify what exactly is meant by the "shared function" in this context? Specifically, I'm trying to understand how this function is defined or implemented to produce the annualized portfolio metrics (Avg%, SR, and SD) from period returns for H-L, High, and Low.
It seems that the portfolio section to which you refer might be calculated differently from what I see. Is it possible that the page I'm referencing has calculations coming from that other "portfolio" section you are referencing. Is it possible to download the data to see how it all checks out? Thank you!
The shared function in question produces Avg%, SR, and SD from a list of period returns.
The period returns of a validation model can be downloaded using the Download button found at the upper right of the chart on the Results / Portfolio page.
Here are formulas that can be used directly in Excel assuming the AI factor uses 4 weeks and deciles, where AE and AG are columns Ret10 and Turn10, corresponding to the High quantile, and 28 is the frequency:
Avg%: =100 * ((1 + AVERAGE(AE:AE) / 100) ^ (365.2425 / 28) - 1)
SR: =AVERAGE(AE:AE) / STDEV.S(AE:AE) * SQRT(365.2425 / 28)
SD: =STDEV.S(AE:AE) * SQRT(365.2425 / 28)
Turn%: =AVERAGE(AG:AG) * 365.2425 / 28