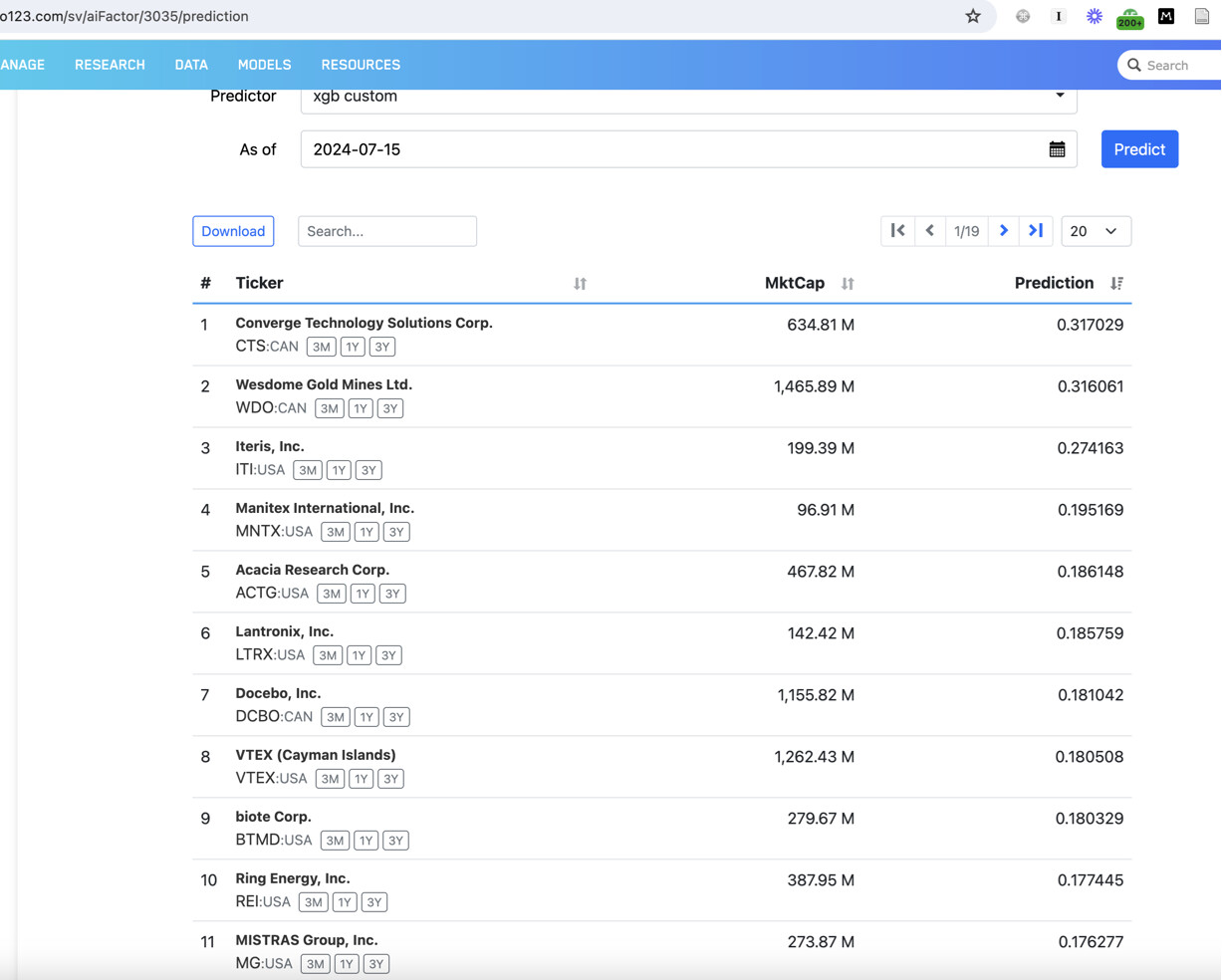
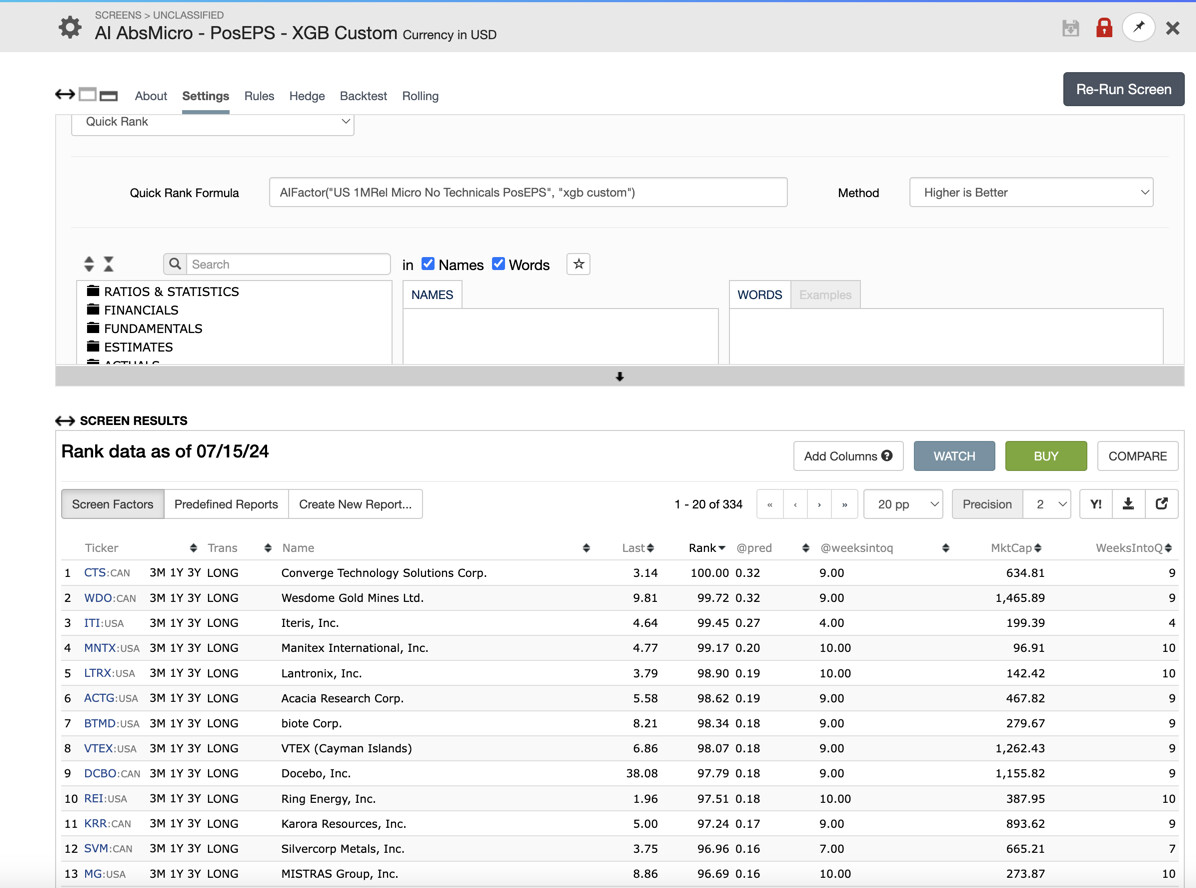
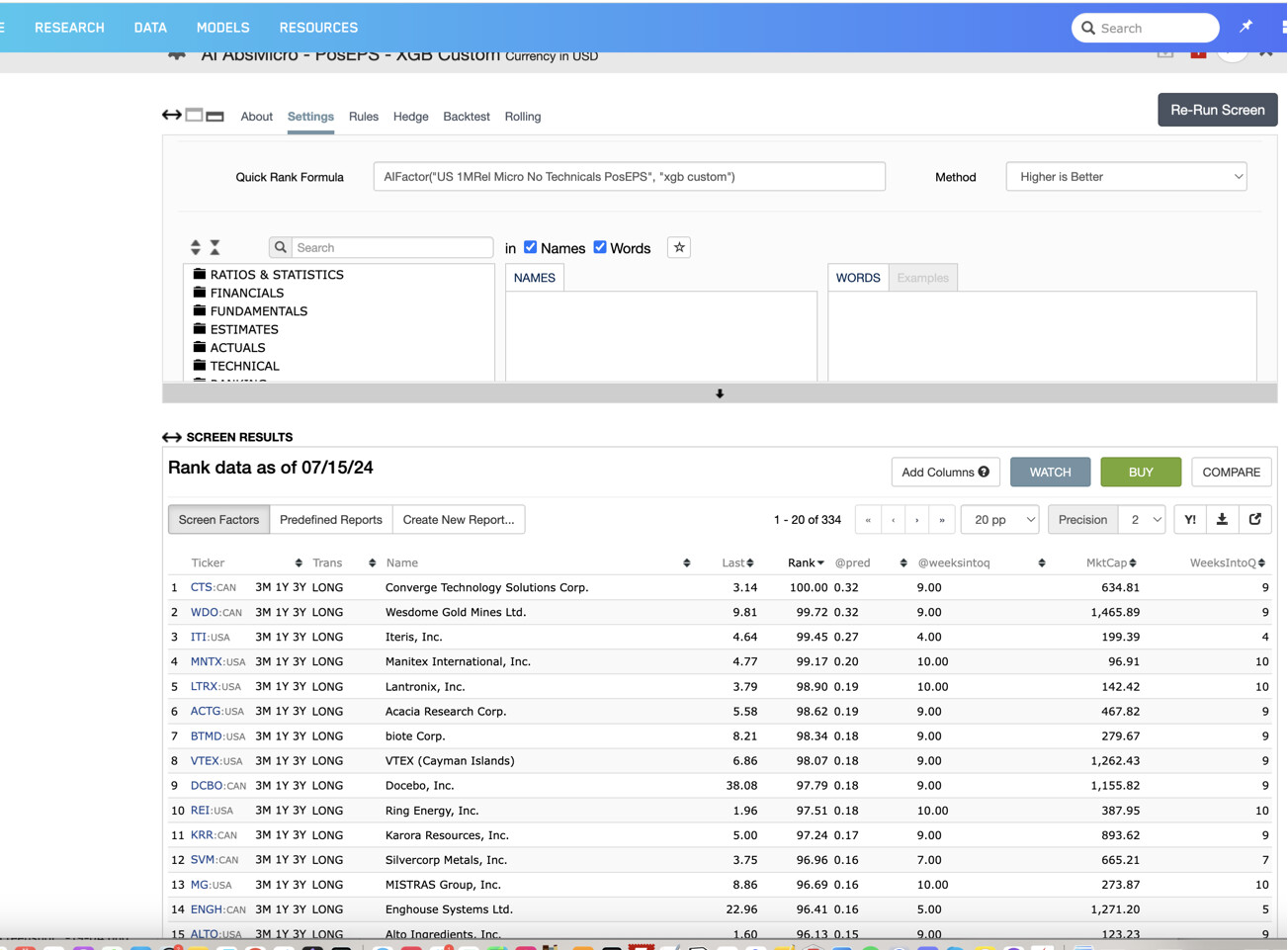
Unlike traditional screens that only update 2x a day, it seems like AI predictions update far more frequently. I've seen screen holdings shuffle around in ranks every few hours. Any feedback on how the predictions update throughout the day would be appreciated.
Edit: Could it be that outside of a cache period, the algos are rerun and the randomness produces slight variations in rankings/prediction scores?
Predictions should not change during the day, only after nightly updates. Not sure what caches you are referring to, perhaps the ranking system cache? Either way caches should not produce different predictions if the same dataset is used.
Now, if you train two predictors with exactly the same dataset you can have different picks depending on the randomness of the algorithm. But now we're talking about two prediction "instances". I don't think that's what you are referring to.
There might be variation perhaps due to ties. If you can reproduce the problem let us know how so we can take a look
That's strange then, in my screen, every few hours after refreshing, I see a few different ranks and stocks. I'm familiar with the common data update times so it isn't that. The stocks that were towards the bottom on the screen are often replaced with others (as their rank pushes them just outside of the screen thresholds).
I am sure it will be easy enough to reproduce the problem, but I don't know how to do so in a way that would be useful to you? I could take a screenshot of the holdings now and keep checking back until they change a bit and then take another screenshot, but would that be enough to assist?
Can ignore my cache comment, was just trying to find any rationale for what is happening.
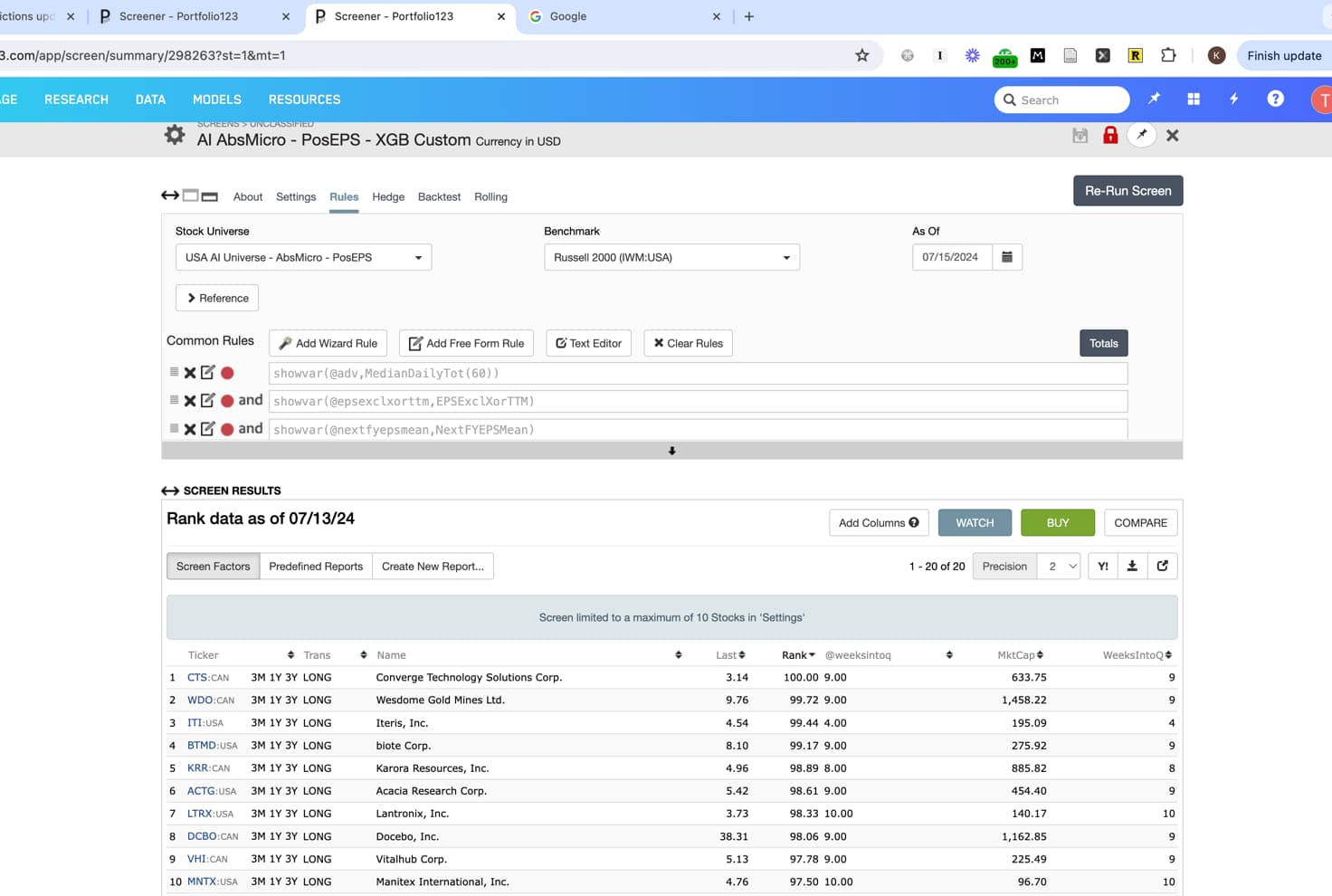
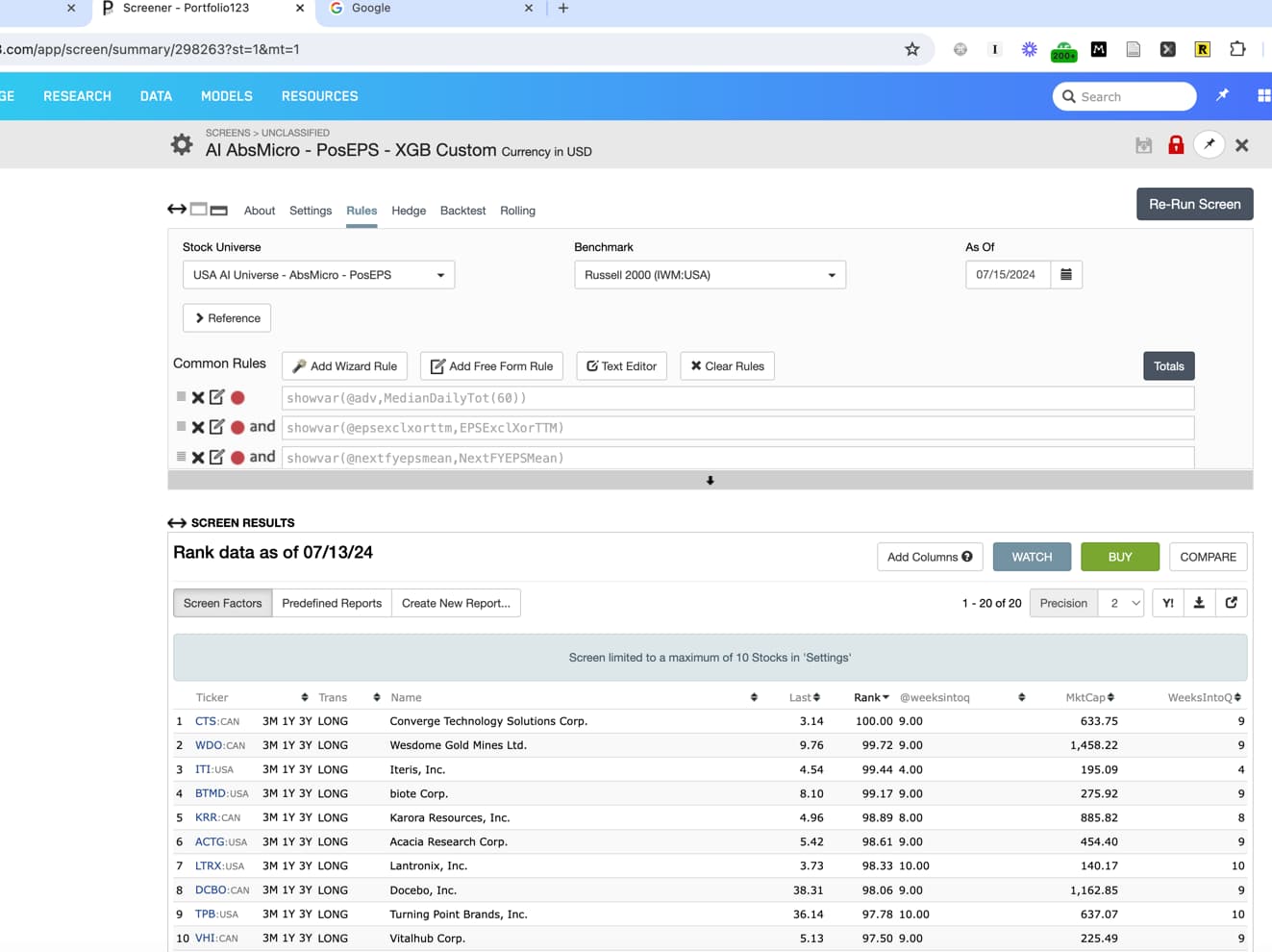
I'm not sure if the name of the screenshot gets sent through here, but the first screenshot was taken at 6:57PM UK time, and then the second screenshot was taken at 8:58PM (about 2 hours later). Pretty sure there were no data updates in these hours. Notice the addition of TPB on the second screen, and the disappearance of MNTX as the rank has dropped.
It's worth noting that MNTX is not tied in rank with VHI - even though the rank in the first screenshot is 97.5 for MNTX and the rank in the second screenshot is 97.5 for VHI. In the second screenshot, MNTX is rankpos 11 with rank 97.22.
Also note that this is just one example, and the issue isn't unique to this particular screen.
This helps. Did you perhaps download the results from first screen? Do you know what TBP ranked ?
Ranks are not predictions. They are relative, so not surprised ranks for MNTX changed. The culprit here is either TPB has a different prediction or it was not present in the first screen.
Unfortunately I didn't download the full ranks from the first screen, but having looked at a lot of these previously it's very likely that TPB would've been in rankpos 11 or 12.
While I know that ranks are not predictions, I'm still confused as to what would make ranks/screen holdings change intraday if data only gets updated in the morning and evening? My understanding is that there would be no new information available for anything to change.
I'll monitor things again today and also add a screen variable for prediction score to see if that changes at all.
If the screen rounds the prediction score to two decimals and ignores the more precise 6-decimal AI factors score, I thought maybe on a 10-stock screen, if both rankpos 10 and 11 have prediction score 0.18, they could shuffle around randomly, making it look like there are changes.
Maybe this is indeed the issue. But then I observed something else that I can't make any sense of:
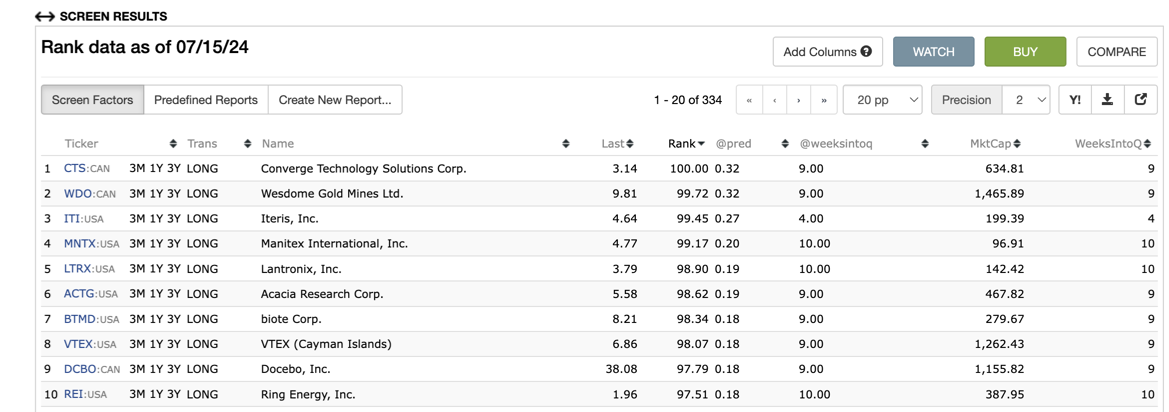
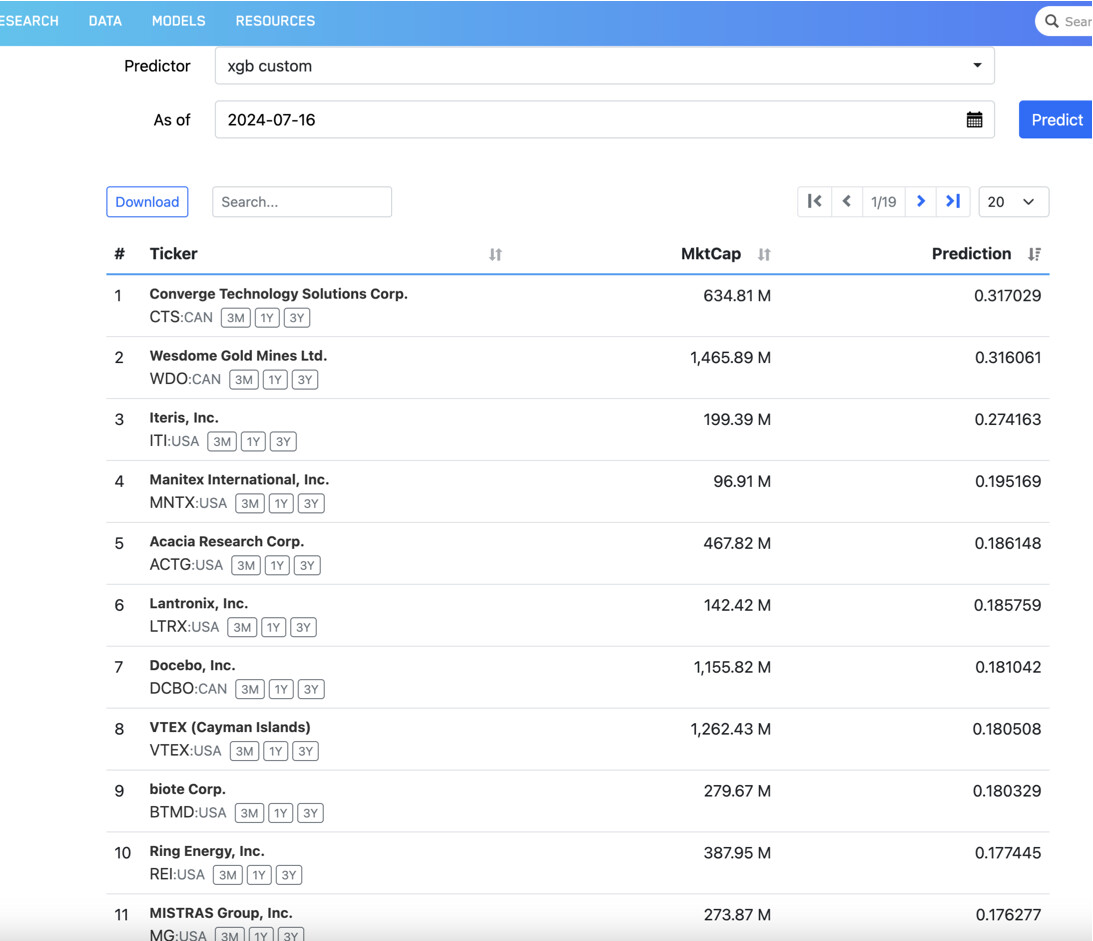
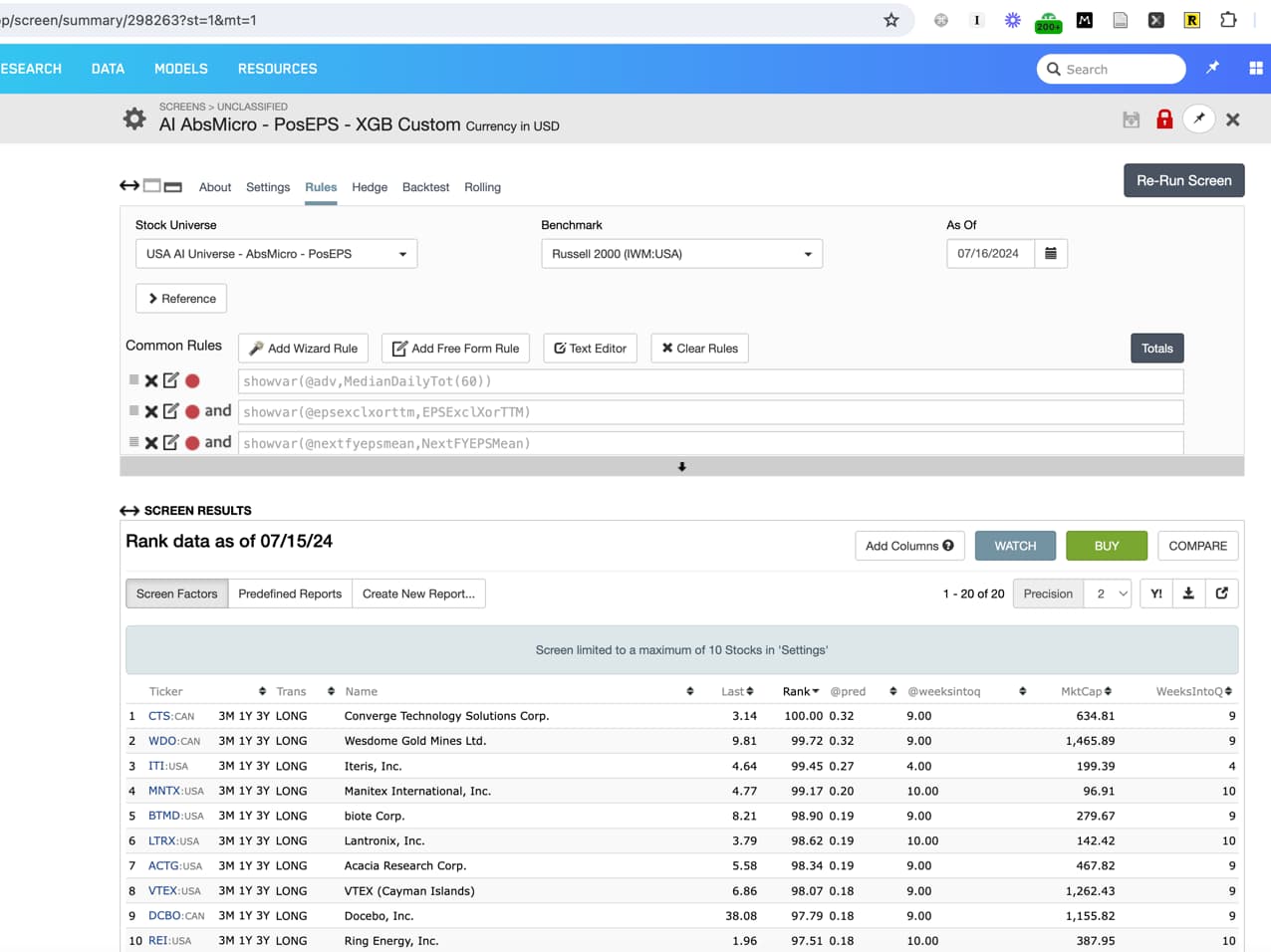
Take a look at the prediction scores on the AI factor page, for both today and yesterday, versus what the screen shows right now:
If we look at MG on this example, we can see the AI factor prediction is 0.176277. But the screen prediction score is: 0.16.
Does the prediction data update at a different time of day compared to the screen data? I know I'd made a post on this about a week ago but didn't have the added context of the differing prediction score on the screen itself.
Are ML models pickled at P123? Seems like this would require a lot of non-volatile memory that would get large quickly considering the number of trials members tend to use. Or are ML models being retrained each time and held in cache for a while?
If the latter is the case, one would expect changes as described by Trendylist. And one could use random_state = 42 for models that have random_state as a hyperparamter option with Sklearn to reduce or eliminate changes in the ranks throughout the day.
I am not sure which method is used, so just a thought.
Thanks, this is a much more eloquent way of asking this question from my OP: "Edit: Could it be that outside of a cache period, the algos are rerun and the randomness produces slight variations in rankings/prediction scores?"
P123's syntax can be different that Sklearn's (probably JSON). For example, true in this example of code that runs is not capitalized. But P123's code can take the "random_ state" hyperparameter, it seems, as in this example:
If you get more consistent result with this, then it is probably true that "the algos are rerun and the randomness produces slight variations in rankings/prediction scores." random_state's purpose is to make reruns more consistent as you know.
We do have an outstanding issue with matching exactly predictions from AI Factor Prediction page with screen results. We're still working on it. But screen results should not change in between updates.
Don't these only affect training? The prediction uses a pickled predictor. Not sure what you mean by "the algos are rerun".
We are still looking for the cause. In the meantime we found some problems with your universe
!Sector=HEALTHCARE should be Sector!=HEALTHCARE
The "!Sector" negates the id of the sector which is always going to be 0. So the conditional will always fail.
$DIV1Y>$DIV2Y>$DIV3Y
This will not work. Should be rewritten as
$DIV1Y>$DIV2Y and $DIV2Y>$DIV3Y
There may be others like this. As far as the problem we think it's some feature that is behaving erratically. It's hard to pinpoint since there are more than 400 features. Maybe you can think of some that may be problematic.
Also, using custom formulas is potentially a problem since editing a formula will change the results downstream.
Thanks for the update and tips where you saw errors, that's very helpful. As you mention with so many features it's hard to identify where one might be 'broken' but good to know that it is indeed likely something is off. Will have a look and see if I can identify anything that might behave unusually.
If it helps, I was tracking again today. This afternoon this was the screen:
You can see here that BTMD's prediction changed from 0.18 to 0.19. So it looks like the actual prediction scores are indeed changing on the screen during periods where there's been no data update.
What are you showing us ? A backtest ? Is it using AI Factor? What's the name of the system?
We narrowed it down to formulas that involve the taxonomy time series. There seems to be some non deterministic behavior: depending which server executes your request a slightly different value is produced, which affects prediction. Obviously this should not happen. Every server should produce the same values. We're working on this. Below is a example of a formula that exhibits this behavior. The differences are small. You can reproduce this behavior in the screener too by logging out every time you run the screen so that you most likely get a different server.