All,
I just purchased “Your Complete Guide to Factor-Based Investing” for $9.95 (Kindle Version). It is probably well worth the money just to get Appendix G.
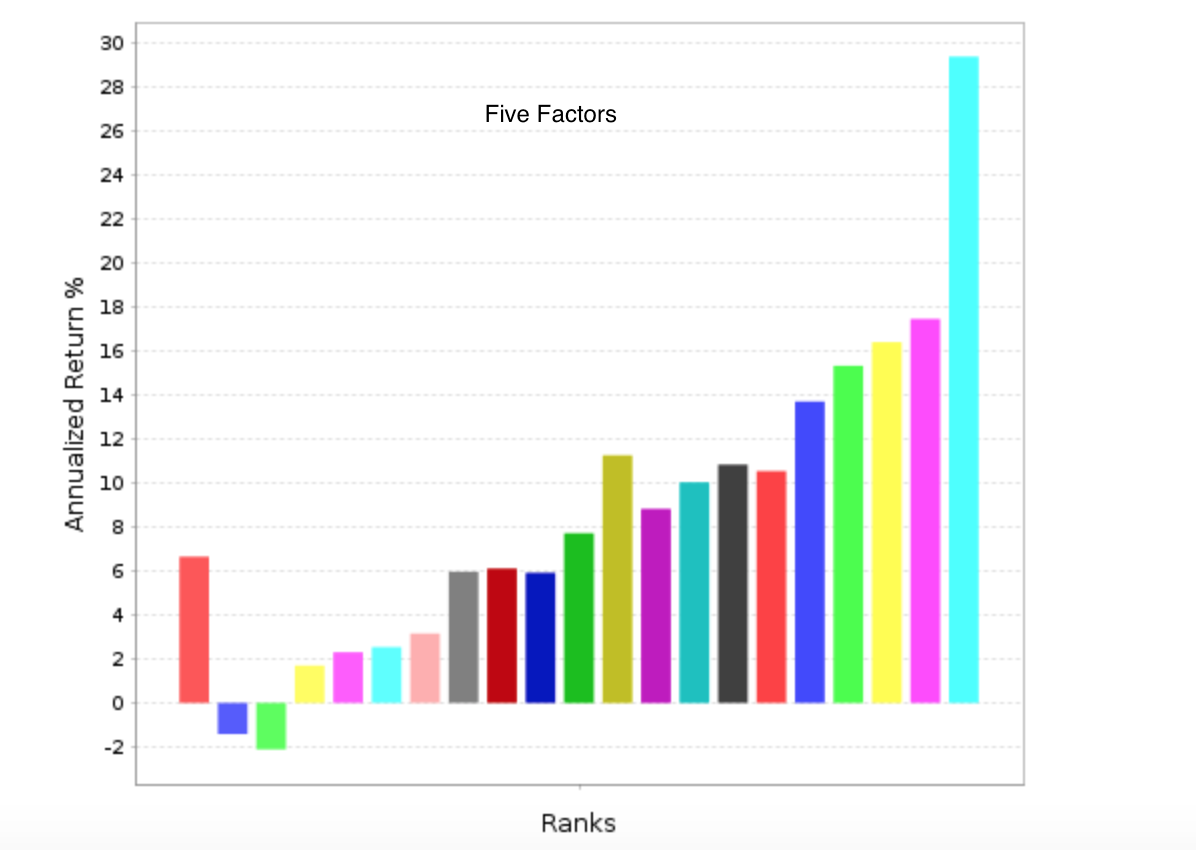
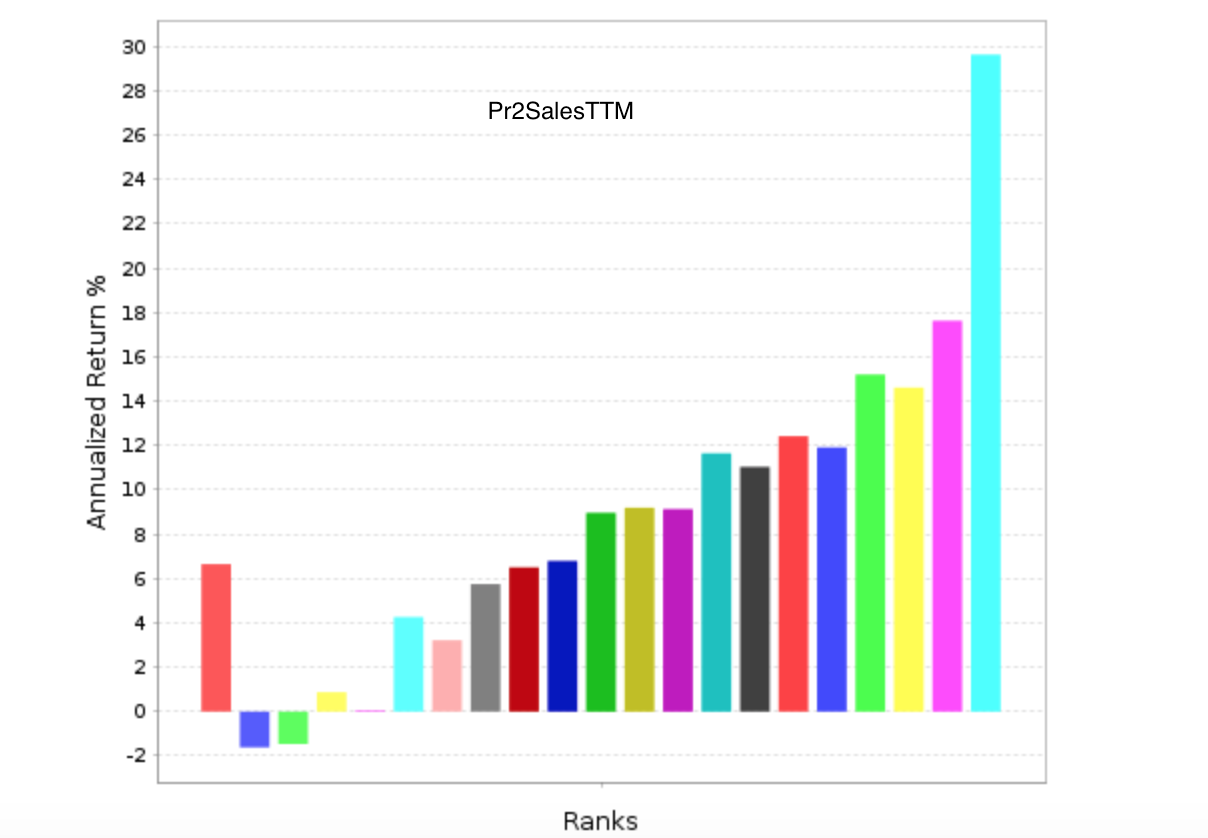
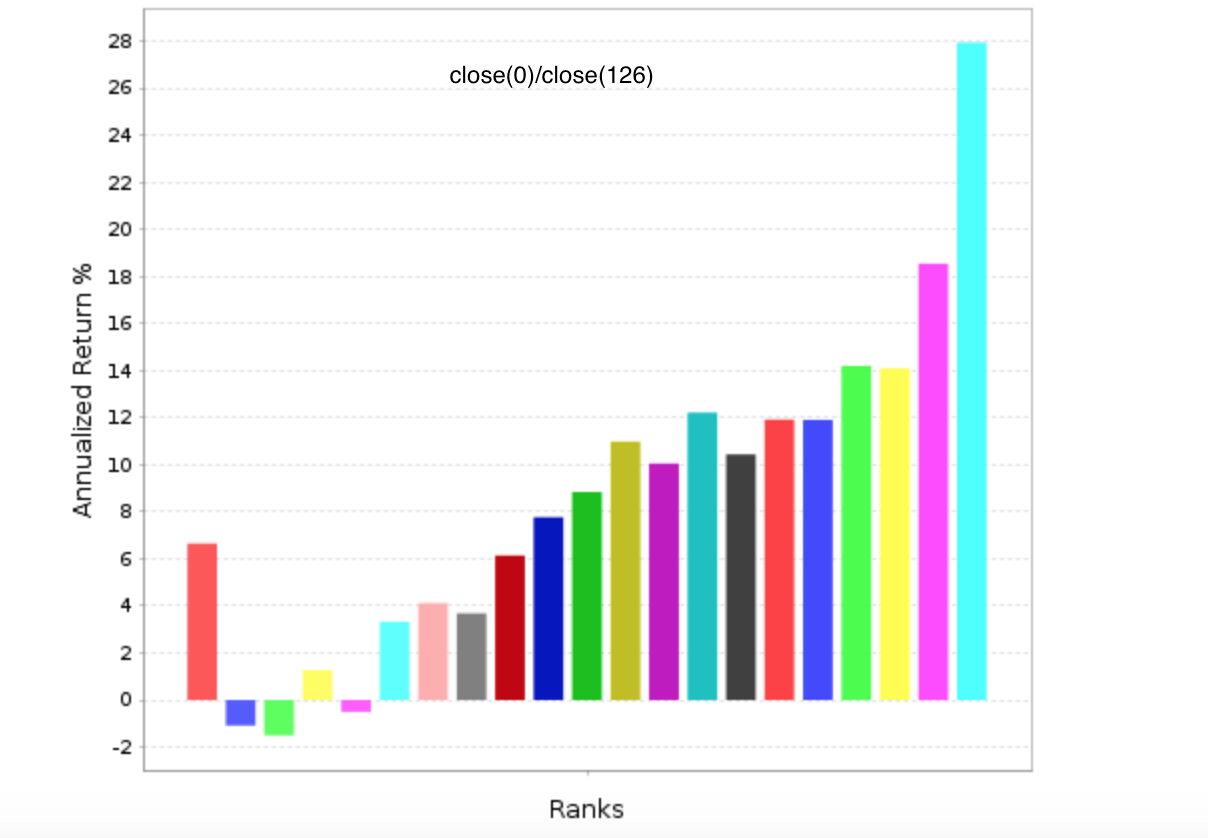
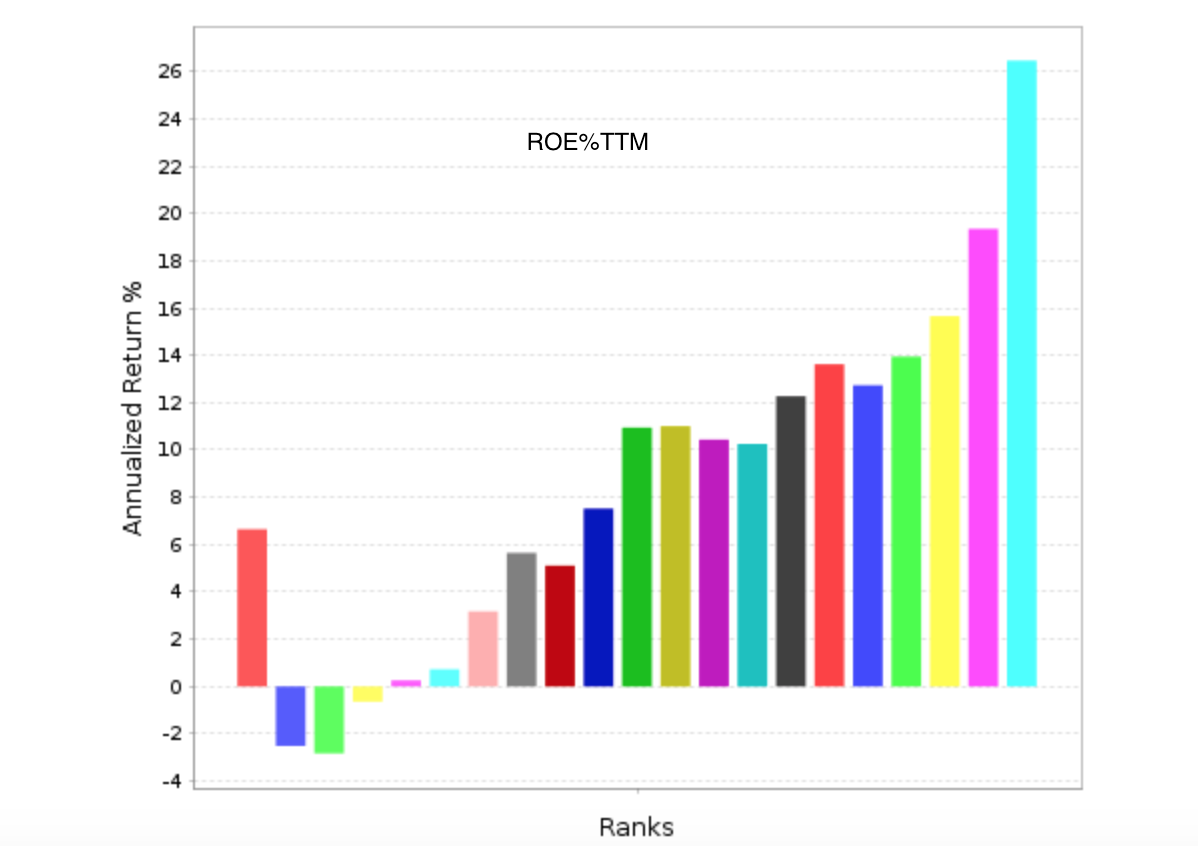
Appendix G is titled “Marginal Utility of Incremental Factors on Fund Returns” and discusses “Incremental Variables and the Investment Opportunity Set” Eugene F. Fama and Kenneth R. French (2015). In summary, this is a discussion of how many factors to use in a ranking system.
Because it is based on a recent paper by Fama and French it should probably be taken seriously. And I would have little to add (“I’m not worthy”: From the movie Wayne’s World).
But even if you disagree and you are in the more factors is better camp there is probably something you can use in this. For example, if you are adding a new factor to the ranking system does it matter whether the new factor has a positive correlation or a negative correlation to the factors that are already in your ranking system? If so, please explain (Oh sorry, I thought I was back in school for a second).
Or as they discuss in the appendix: How much does adding that new factor affect turnover and transaction costs? I do not mean to imply that the answer to this will be the same for everyone. Just that it is a good question.
Marc,
I leave to you to consider and express any opinion regarding Appendix G. But on my first read through the book I think it provides strong support for your ideas on the DDM and how the macroeconomy affects value stocks. Of course, they do not always come back to the DDM in this short book but I think you have said most or all of what the book says about this topic at some point. And there are some things—like the ability of small companies to get credit—that might not have been traced back to the DDM in your posts (I don’t recall).
Of course, I do not mean to imply that you agree with everything they say on this topic but is seem there is a lot of agreement on my first skim-through.
-Jim