I’ve been experimenting with Portfolio123’s ranking system and factor-based strategies, but I’m struggling to fine-tune my approach for better performance. I’d love to hear from those with experience in optimizing ranking models.
Currently, my strategy focuses on a combination of value (P/E, P/B), growth (EPS growth, sales growth), and momentum (relative strength) factors. While backtesting shows promising returns in some periods, I’m noticing performance inconsistencies across different market conditions. For example, my model tends to underperform during strong growth-driven bull markets, which makes me wonder if I need to adjust factor weightings dynamically.
A few questions I have:
Factor Weighting: Do you find that equal weighting across factors is effective, or do you assign different weights based on market regimes?
Factor Rotation: Have you implemented any rules for adjusting ranking criteria based on macroeconomic indicators (e.g., interest rates, inflation trends)?
Overfitting Concerns: How do you strike a balance between optimizing a ranking model and avoiding overfitting to historical data?
Ranking System vs. Screening: Have you found it more effective to rely solely on ranking for stock selection, or do you combine ranking with specific screening rules?
Any insights, best practices, or examples from your own experience would be greatly appreciated! Looking forward to discussing this with the community.
Besides that, I would recommend you to add more different types of factors. It seems you have covered valuation and growth, as well as momentum in your ranking (or screening?) system. Probably adding some other factor types (especially quality type factors and low volatility) will make your returns much more consistent, even through different market conditions.
My temperament does not lean towards growth but among the things I have learned are:
Use yield expressions like E/P instead of P/E. This gives a value instead of NA for negative earnings and makes small earnings not result in a huge number.
Incorporate Sales, like P/S, into your factors as it has extra weight in evaluating growth.
Use compares against Industry to potentials that against the entire universe gets lost.
Pull in Sentiment factors to introduce external opinions.
Acknowledge that using value factors and growth factors together will tilt you towards GARPish or value with some growth (hopefully missing some value traps) selections. Giving up some the highs for limiting some of the lows.
While not in a Ranking System, I have used a short term technical like RSI_D(10) >= 20 as a buy rule to offer up a slight tailwind with positive results
I would use predefined ranking systems as a base and go from there. Here are "base books" I built based on a test of all predefined ranking systems (some of the predefined ranking systems I tweaked).
Also, I would not try to reach all goals in one strategy, but combine different strategies (with different ranking systems) in a strategy book, that makes sure you diversify different factor (tilts), not every factor tilt is strong every year (and I found no way to time factors well).
In general: I find estimate and actual factors to be a sweet spot (on stock and industry level).
Value is difficult if not combined with momentum or earnings estimates momentum.
Dynamic factor weighting, i.e., factor timing, is almost impossible to justify in terms of the required transaction costs and the resulting increased complexity of the system.
In short, it is better to recognise that multi-factor systems can also underperform at times.
Overfitting is a cancer. Just equal weight is much better than most solutions. And simple is always better.
It's not a good idea to optimize, just make something okay.
I guess I agree with this about 50%. It really depends on how you go about optimizing. Many optimization techniques lead to overfitting. But there are others that may not. And simple is certainly not always better. The example of Joel Greenblatt is instructive.
My opinion after some time toiling with this is that the factor weighting is more easily managed through risk management. Knowing your factor bets will go a very long way to mitigating these concerns.
I did try to adjust the weights to neutralize the tendency of the dan list rankings to be overly biased towards fundamental momentum at the expense of low volatility and value, which did reduce the unwelcome downside risk. This is not optimization for me though, but just basic equal weighting.
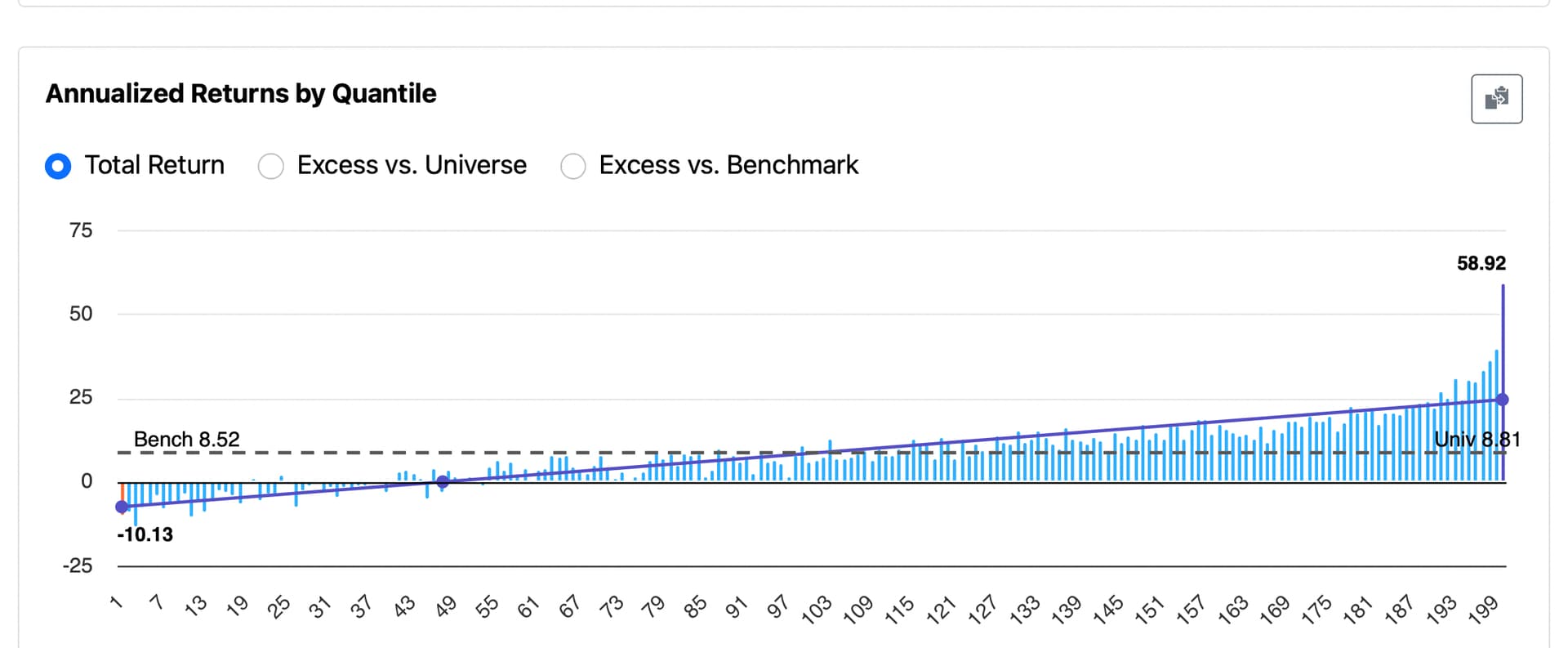
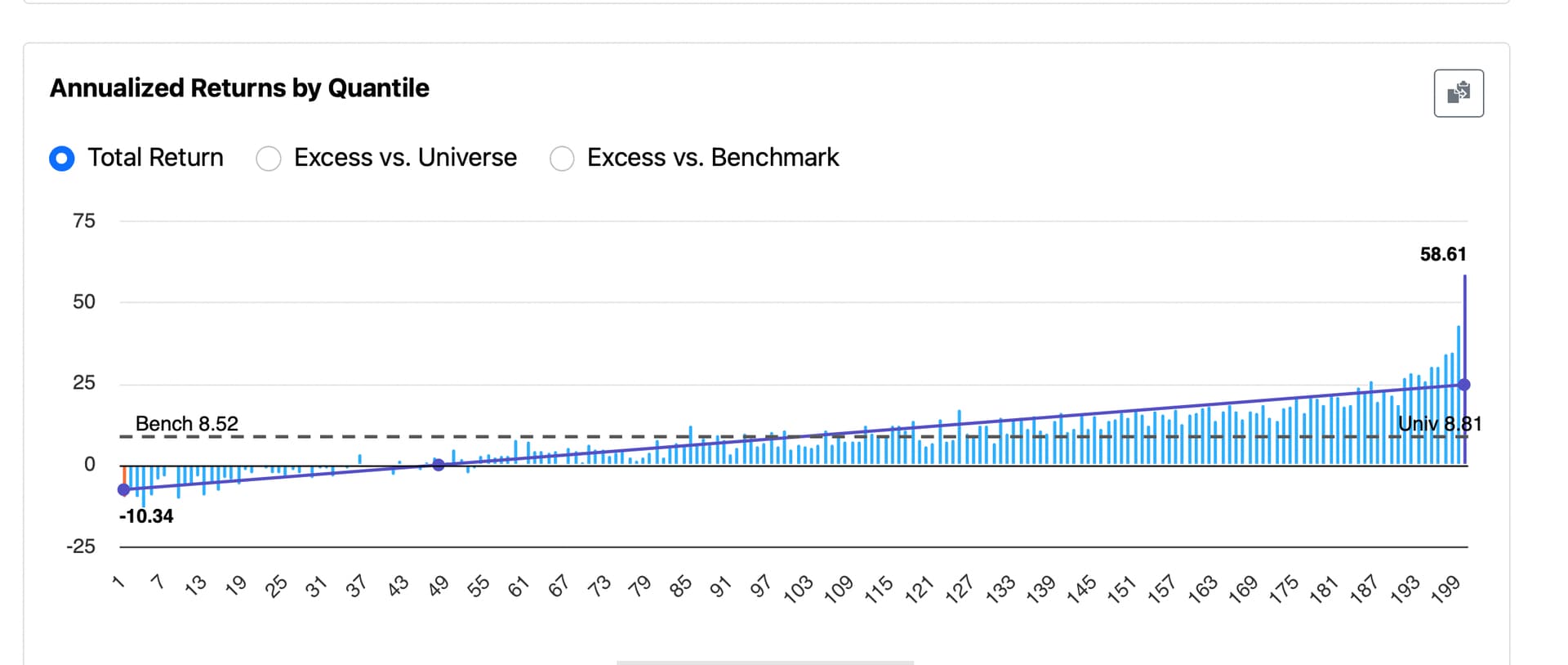
I’ve tried to present just the facts, without manipulating the data in any way. This is the only ranking system I tried this with so there is no cherry-picking. Maybe some publication bias but I probably would have wanted to post if my system was better than equal weight. Hmmm…what would I have done if equal weighT outperformed my algorithm? Honest question. I wonder if we will see that from anyone in the subsequent threads. Where equal weight outperformed their algorithm on a backtest. We could see some publication bias there, I believe.
That said, I think it’s a fair and unbiased observation to say that the difference does not appear to be statistically significant or practically significant either.
Would be interesting if others tried this with their own ranking systems and shared the results. Having a larger dataset could help us draw more meaningful conclusions.
I am not implying that this one sample is definitive.
It's not about performing any optimization (in the sense you're talking about), it's about removing the weight bias between broad categories of factors caused by optimization in the ranking of Dan's list.
In fact, it's not even necessary. I just want equal weights.
Edit: In fact, the notion of optimization as you describe it makes no sense outside of extremely simple artificial systems (e.g., literature, painting, music, chess, Go) - at least by the limits of current human capabilities.
Yes, I'm not wrong that the literary/artistic field lends itself to quantification in the extreme.
Due to the ease of collecting data and the certainty/stability of the results themselves. The optimization problem for music is relatively much easier. You needn't care much about overfitting
I’m not sure I fully grasp everything in your post, and I apologize in advance if I’ve misunderstood any part of it.
That said, it’s fascinating how deeply math is embedded in so many aspects of life. For example, the Ionian mode (major scale) is structured around logarithmic (base-2) octaves, aligning with how we perceive sound and loudness.
There’s a natural elegance in these symmetries—whether in music, physics, or even aesthetics. Some might even appreciate how gravity emerges from the symmetry of four-dimensional spacetime or the sheer simplicity of E = mc².
If that’s in the spirit of what you’re saying, I completely agree.
In the broader context of investing algorithms, I think the same principle applies. Complexity can often be distilled into simpler forms while preserving its core mathematical structure, and when done well, there’s an undeniable aesthetic beauty to it too.
What I really meant was: Because of the high cost of data and the extreme uncertainty of the "true function", the investment problem cannot even be solved in terms of optimization as he defines it, and there are only a few simple principles (e.g., the C+T method with a fixed threshold as in the gene score calculation is basically very good for out-of-sample prediction - but that is not causality) and factors (as the selected SNPs) that can be followed. By contrast, simple artificial systems represented by literature and art can be optimized, at least, where the accuracy is roughly literature > painting > music as the order of relative success of large models on these problems. For example, both cross-cultural and intra-cultural consistency is stronger for painting-related issues in the studies just cited, and less so for music-related issues. And text-related problems are so simple that even largely unsupervised machine learning (Transformer) can be used to distil their laws.
I think I may agree with that too. For sure, I have no use for an optimizer, and the ML system I use is, in my opinion, both more elegant and significantly simpler than most.
You certainly make some great points.
I’m not even sure the optimizer is included in my current P123 membership level, if your point was largely about the pitfalls of optimization. Even fast, automated optimization has significant limitations with present-day computers, and I’m not holding my breath for quantum computing to solve that anytime soon.
A broader point that might just be mine: compute limitations are often a bigger problem than they first appear—especially when trying to use a large number of features in a model. Some form of simplification is required much of the time, and essential if you want to explore the entire solution space.
In cases where optimization is not required, the computational constraints do not matter. This is because the computational effort of univariate OLS (or better yet, direct binned averaging, at most after ranking) is negligible, especially compared to the costs of data.
And the cost of data is always often far greater than the cost of analyzing it. For example, obtaining additional stock data is costly: one needs to wait a month in real-time for new monthly data, or one needs to personally deal with stock data for countries and eras that have historically been under-appreciated. This obviously costs more than analyzing the existing data. That's why it is the main constraint against optimization.
It is basically only in the case of large language models, which deal with extremely easy access to a lot of data and extreme structuring of the problem itself (i.e., text-based problems), that computational constraints begin to be comparable to (or even more than) data constraints. Image generation problem may be similar.
Let's say a ranking system uses a number of factors that are strongly correlated and a few factors that are uncorrelated. Equal weight will favor the correlated factors. Is that what you want? For example, what if you have twenty different ways of looking at profitability? ROE, ROI, ROA, profit margin, and operating margin, compared to universe, sector, and industry, gives you fifteen factors right there. On the other hand, your list may only have one or two factors that look at, say, sales stability, or price variability, or R&D expenditures. Does equal weighting ever really make sense except as a to-hell-with-backtesting shortcut? I suppose if you put factors into groups and equal weight those, that might make some sense, but what about outliers like the PEG ratio (is it growth or value) or share turnover (is it technical or stability or size)? And within your groups you still might have some highly correlated factors and some entirely uncorrelated ones.
Then there's the question of probability. If a certain combination of factors has worked well in the past and another combination has fared poorly (and if "the past" stretches back 25 years or so), isn't it more probable that the combination that has worked well would work better than the combination that has worked poorly? Maybe the differences aren't huge, but favoring combinations that have worked well in the past is more likely to yield favorable results because there is some correlation between past and future strategies.
Optimization is fine, but it should be robust enough to avoid excess curve-fitting. Equal weight is relatively arbitrary and doesn't take either correlation or probability into account.