Hi P123 Team and Members,
Killer app for this:
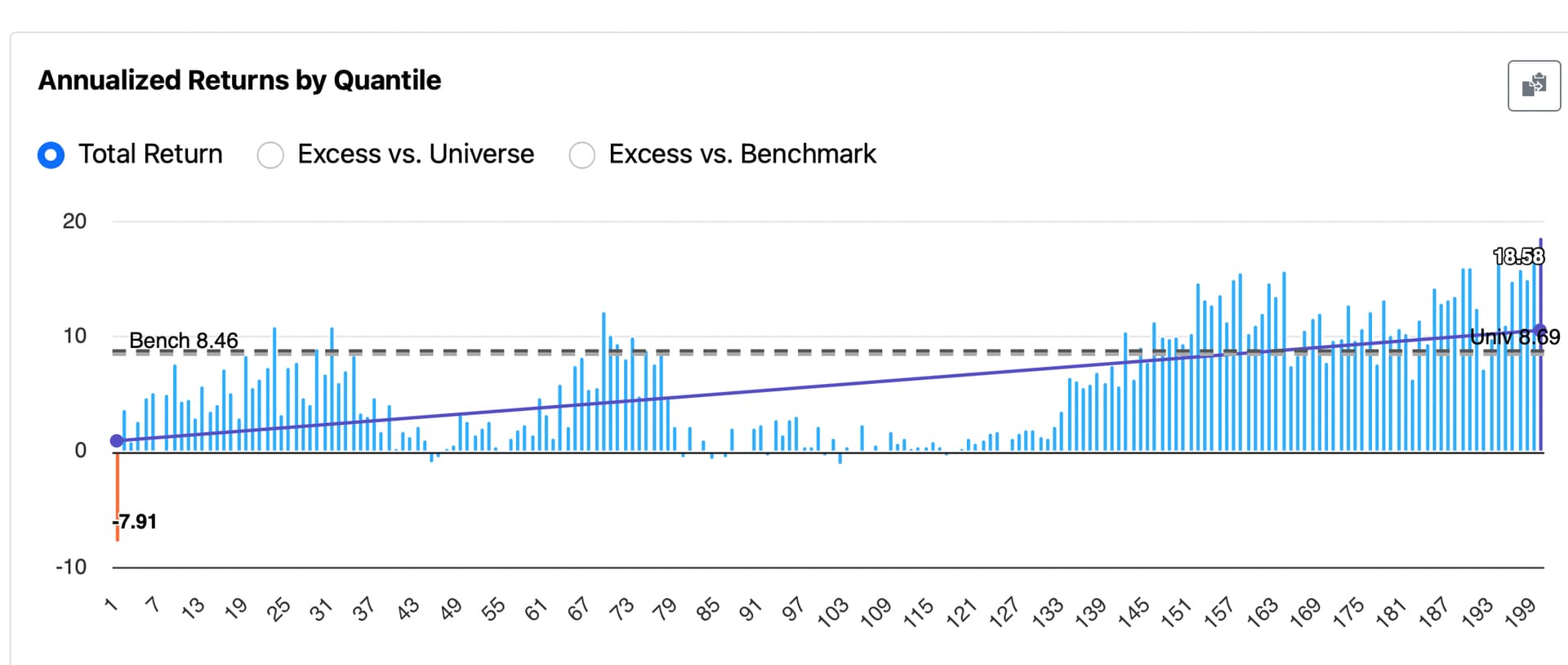
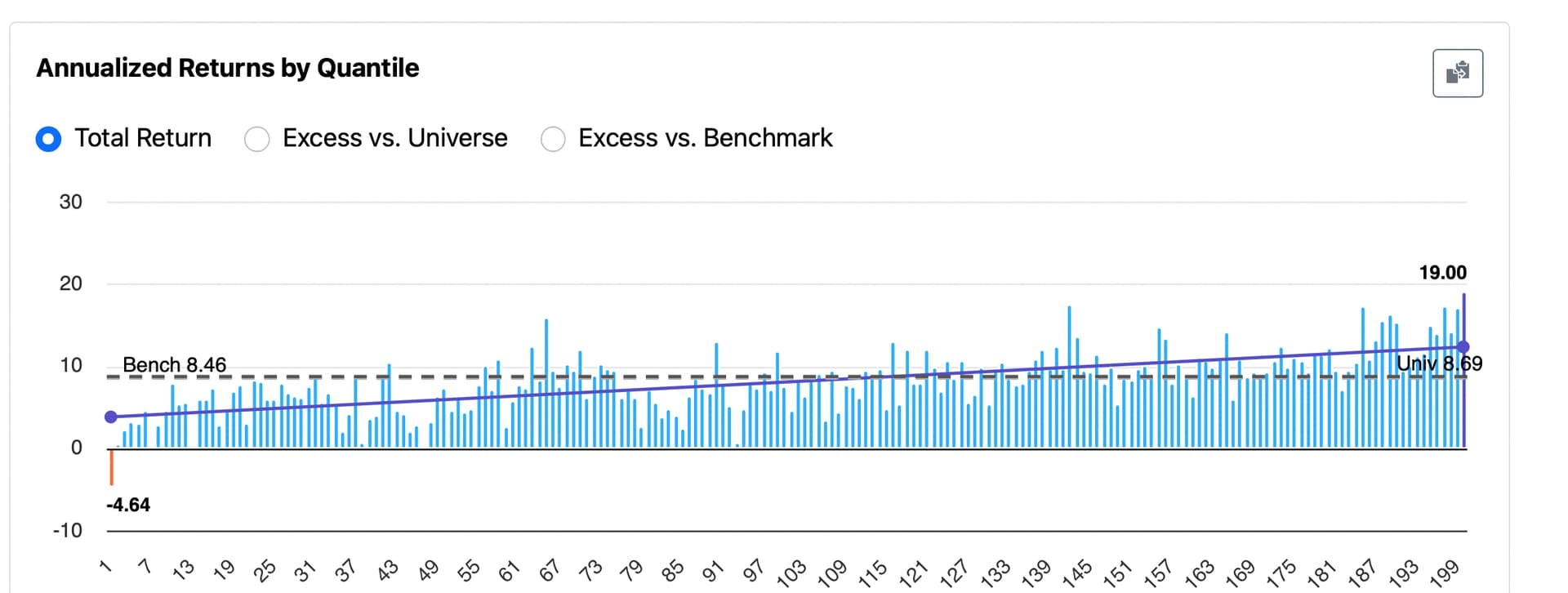
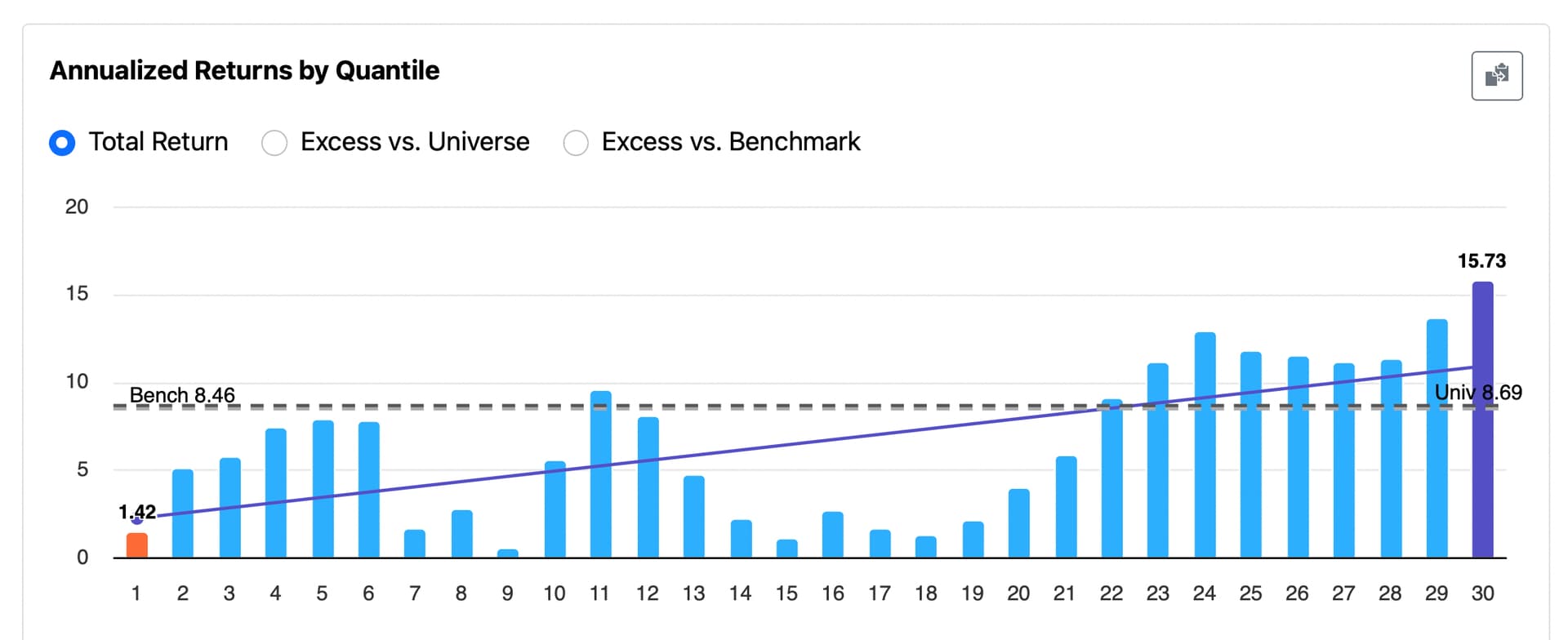
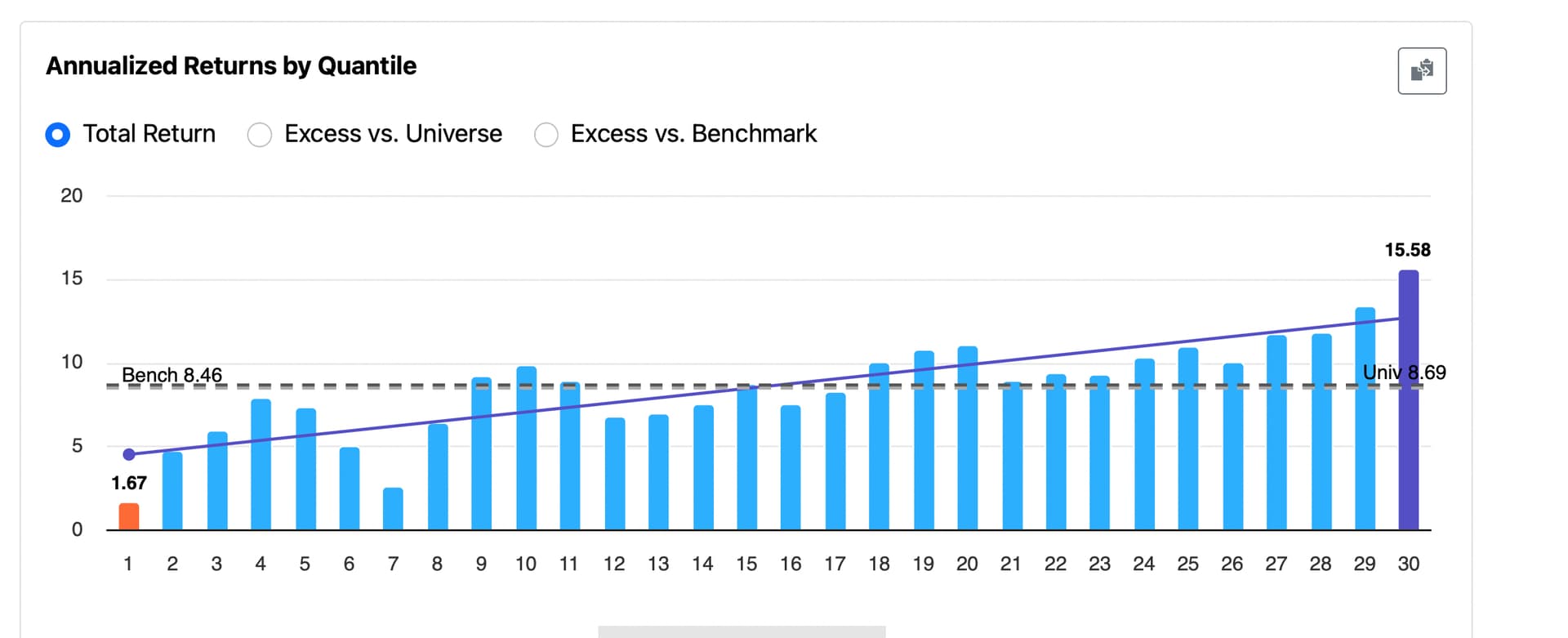
→ Smooth rank performance test results with an equal number of stocks in each bucket (achievable with mild additional programming that I will not cover ).
I’d like to propose adding a random_state parameter to P123’s random() function. This small enhancement could support multiple valuable use cases:
- Consistent tie-breaking across model runs (when desired)
- Controlled randomness for reproducible random subsets (e.g., replacing current uses of Mod())
- Debugging and backtesting repeatability, especially in workflows with random elements
- More consistent simulation results — for example, it could help address variability in cases like this: Backtest Consistency: Different Results from Same Test
- Cleaner performance testing with equal-sized rank buckets (achievable with mild additional programming that I will not cover here)
This feature is widely adopted in most machine learning libraries, including scikit-learn’s RandomForestRegressor, because it gives users control over randomness when needed—or consistency when preferred.
In practice, this could be implemented as:
Random(seed =123)
…or similar, with the default behavior remaining unchanged for backward compatibility.
Given the relatively small development effort and wide applicability, I believe this would be a high-impact addition for many users.
Thanks for considering it!