I also ran across a presentation he gave a few years ago where he made several very positive comments about scikit learns RANSAC Regression ability to handle outliers in financial data.
Causality doesn't really matter. What matters is out-of-sample predictability. For example, it mentions the out-of-sample low returns of the investment factor. But one only needs to see zero or negative returns for the CMA factor in Asian and frontier markets to prove its lack of basis.
And, causality is actually a wrong way to think about machine learning, and not just in finance. In fact, imposing overly deterministic and overly complex models like causality networks before having sufficient empirical facts is not only not science, it is anti-science, pseudo-science and superstition. There are many such errors in economics, and the field of factor investing is instead a relatively good one.
One of the major problems with machine learning theory is that it relies too much on solution-space models that overestimate the determinism of models in real-world production and therefore do not cope well with high-dimensional problems. If model uncertainty is correctly estimated, then high dimensionality is not a "dimensional disaster", but rather a "dimensional blessing": My 500 factor AI-model is my best model even if those factors are selected from Dan's sheet in the simplest way you can image.
Double descent is actually an example of better theorizing: it has been found that as the parameters of the model go up, an effect similar to model averaging that reduces unnecessary model/initial parameter uncertainty increases the quality of the predicted results is actually achieved. This is not the disappearance of the overfitting vs underfitting tradeoffs, but rather the triumph of model averaging/stacking.
The HML/MOM example he uses to illustrate that "causation matters" also makes no sense. That's just a comparison between boosting and model averaging. And he is wrong to overemphasize the importance of boosting. Especially in large cap stocks with high economic value potential, model averaging that reduces model uncertainty works better.
The emphasis on causality in machine learning actually further emphasizes model determinism and imposes more structure, which further reinforces the theoretical errors in this area in the machine learning community. As A.Y. Chen found, the more seemingly plausible causality theories are, the worse the out-of-sample validity of the factors, so what the factor investing community needs is not more presumptive causality, but less of it: "It's the economic value of predictability, stupid"
TL;DR: Finding causality and trying to falsify a theory is probably useful for removing false-positives from a predictive model. I have not found a good use of the "Do Calculus" myself. Not yet anyway.
With regard to the "Do Calculus," I found "collider variables" fascinating but did not necessarily find a use for this in P123 models. Would it make a difference if I included "collider variables" in a Ridge Regression? Or if I mistook a "collider variable" for a "confounding variable"?
Mistaking a collider variables for a confounding variable would totally messes up the correlation of the FEATURES, but I am not sure that it does anything at all to the predictive power of an ML model. Still thinking about how to possibly use this, however.
Claude 3's thoughts on that: "Your intuition that including collider variables or mistaking them for confounding variables might not make a significant difference in a P123 model could be correct, especially if the model is primarily focused on predictive performance rather than causal inference."
I guess my post so far mostly relates to whether trying to do the "Do Calculus" in de Prado's book is helpful for predictive models.
Obviously, features with no rational reason for working need great proof or possibly should be rejected out-of-hand.
This is Popper's idea that any good theory should be falsifiable. From de Prado's reference: "Popper gave special significance to falsification…."
De Prado's emphasis on reducing false positives, including using some of Popper's ideas about falsifiability, seems useful. But I might skip the (Do) calculus for now.
Machine learning, as with all tools, is dangerous. Like fire, man's earliest tool, those who use it correctly will reap the benefits, while those who don't will suffer the consequences. And since machine learning is particularly advanced, using it correctly is even harder.
I think his recent research emphasizing causality is on the wrong path. On this path of emphasizing boosting, the overfitting problem where one tends to extremely over-emphasize bias over variance is further exacerbated, which can lead to even much worse out-of-sample performance than traditional ranking methods. Unfortunately, the vast majority of institutional investors misuse machine learning in this way. For example, the pod shop model, which has only recently become widely known, encourages such overfitting.
It just didn't happen. In fact, in psychology, the social sciences and even engineering, professors talk about causality with extreme casualness, using correlations, tiny and biased data sets and even individual cases as a basis. They even use Granger tests, which the founders also said did not account for causation at all, as proof of causation (such tests amount to little more than the most rudimentary OLS regressions in factor literature), and these conclusions are often ruthlessly destroyed or ruined by meta-analyses. Despite the fact that the statistical methods employed in these meta-analyses to prevent publication bias are so weak that they can't even disprove the existence of the usefulness of size factor itself. Those conclusions are still believed to be self-evidently true and well-documented: Neuroticism is the cause of bad things, self-control in childhood is the key to success, marriage is good, divorce is bad, tax cuts boost the economy, inflation is bad for the economy, etc.
Proving some degree of causality is not impossible, but people tend to over-summarize causality from too few evidence to confirm their biases rather than under-summarize causality. So there is a much greater danger of talking about too much causation than talking about too little causation.
This seem correct to me. So many studies included in meta-analysis are small and should have some sort of implied Bonferroni correction at the outset allowing for 20 or so quick studies having been done--just for fun by other research teams--and not published because they were too small to begin with (if nothing else).
from sklearn.linear_model import RANSACRegressor
ransac = RANSACRegressor()
ransac.fit(X, y)
I think the best meta-analysis tool available now is the FAT-PET-PEESE method. However papers using this means have concluded that there is positive significant alpha in the size factor itself, even though clearly its not so.
Humans still have too few data sets to draw too many and too certain causal relationships. The factor investing community already has more and better quality data than the social sciences or even the vast majority of engineering fields, yet one still has to be careful about the causal conclusions they draw.
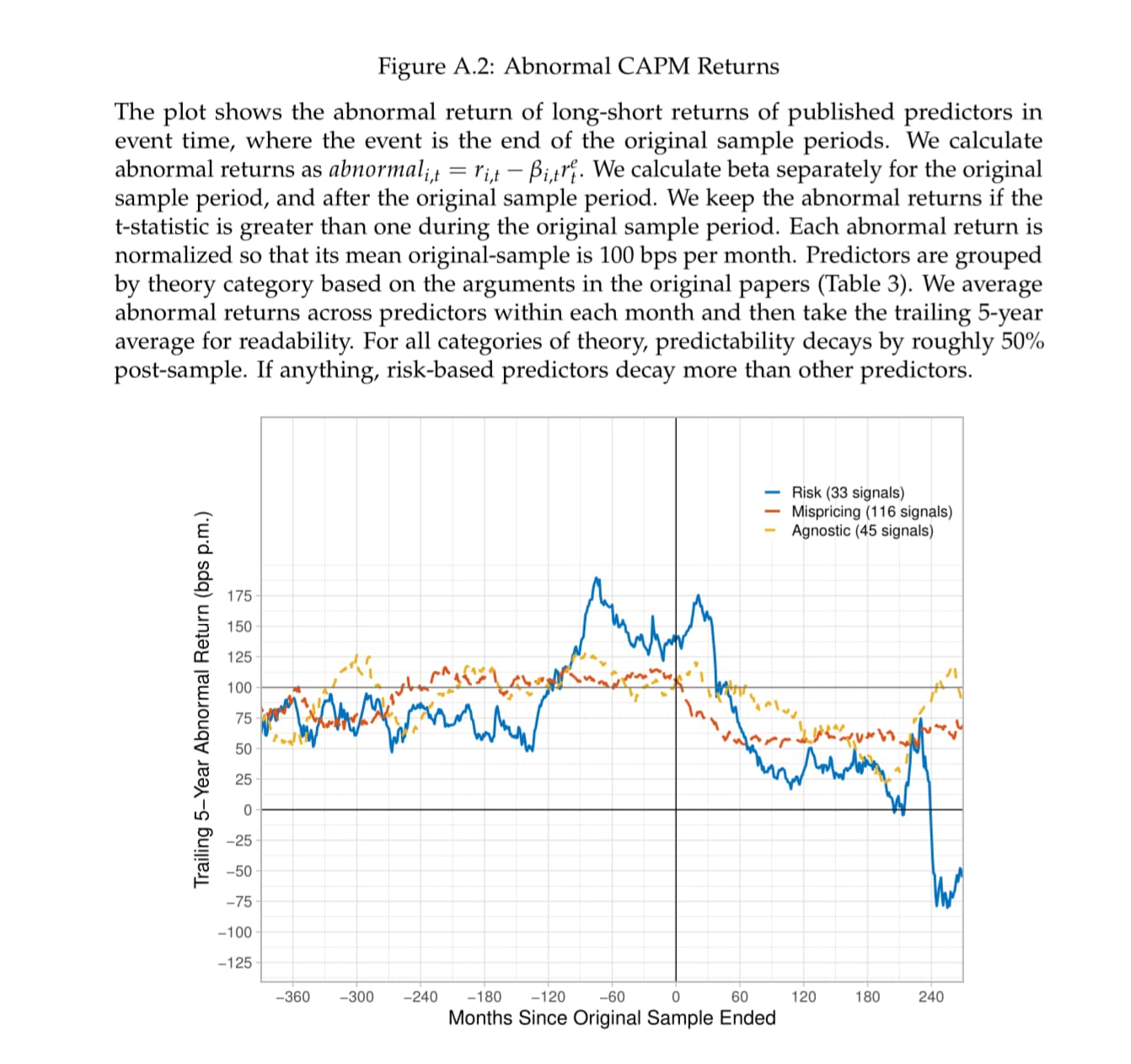
For example, A.Y. Chen found that factors explained by risk performed very very very poorly out of sample, while factors explained by "mispricing" performed better out of sample. This is in extreme contradiction to the causal conclusion (also recognized by Fama and French) based on the intuition that "factor premiums come from risk" and the consequent "factor premiums associated with risk do not disappear".