Maybe only tangentially related to this post Marcos de Prado's new ML book where de Pardo laments the number of false positives in Finance Literature. So I started a new post. But De Prado has a point about too many false positive in the literature, I think.
There are other ways to avoid false positives, in addition to finding features with a plausible cause-and-effect relationship..
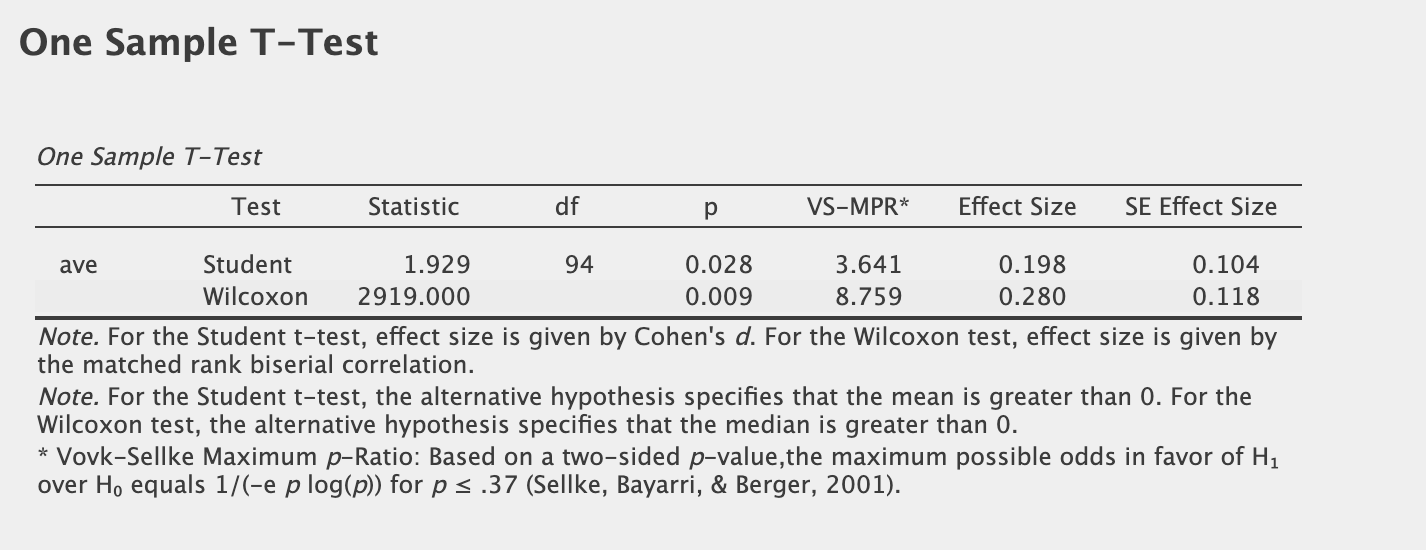
I was testing a model statistically. I was doing some p-hacking in other words.
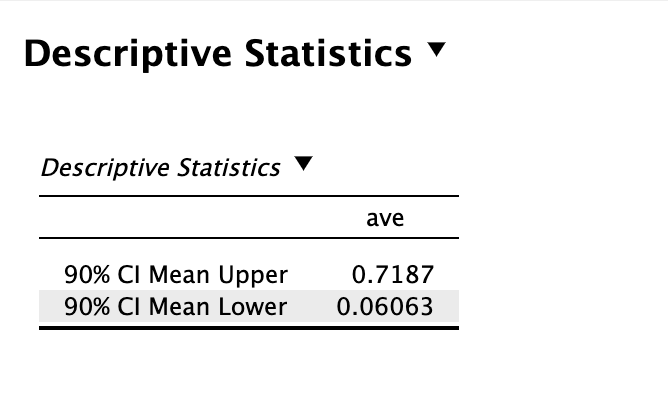
One-sided significance on 3 tests including a Bootstrapping confidence interval (Descriptive Statistics) which are all "significant" with a p-value < 0.05.
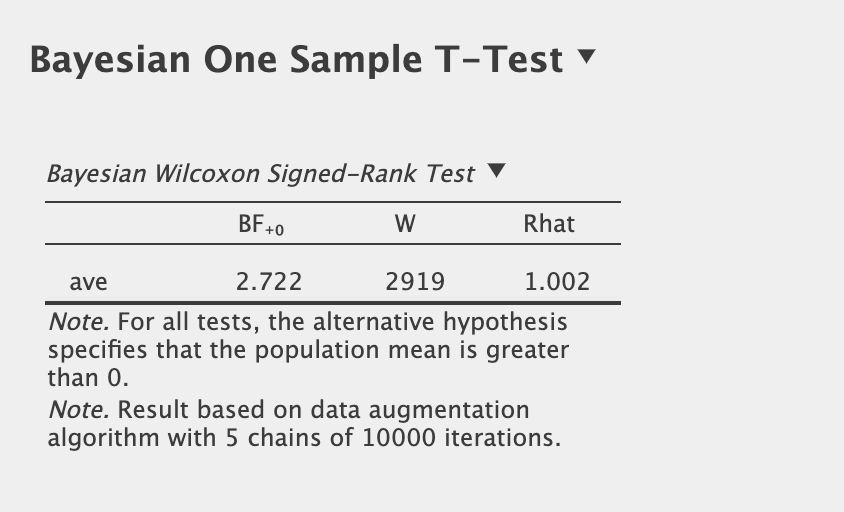
Not necessarily a bad thing to have your p-hacked statistics in your favor, but odds that this model actually has any edge at all is just 2.72 to 1 as indicated by the Bayes Factor.
These odds calculate to a probability of 73% that this model has an edge over the benchmark. Not a probability of 95% or greater as one might think from the p-value.
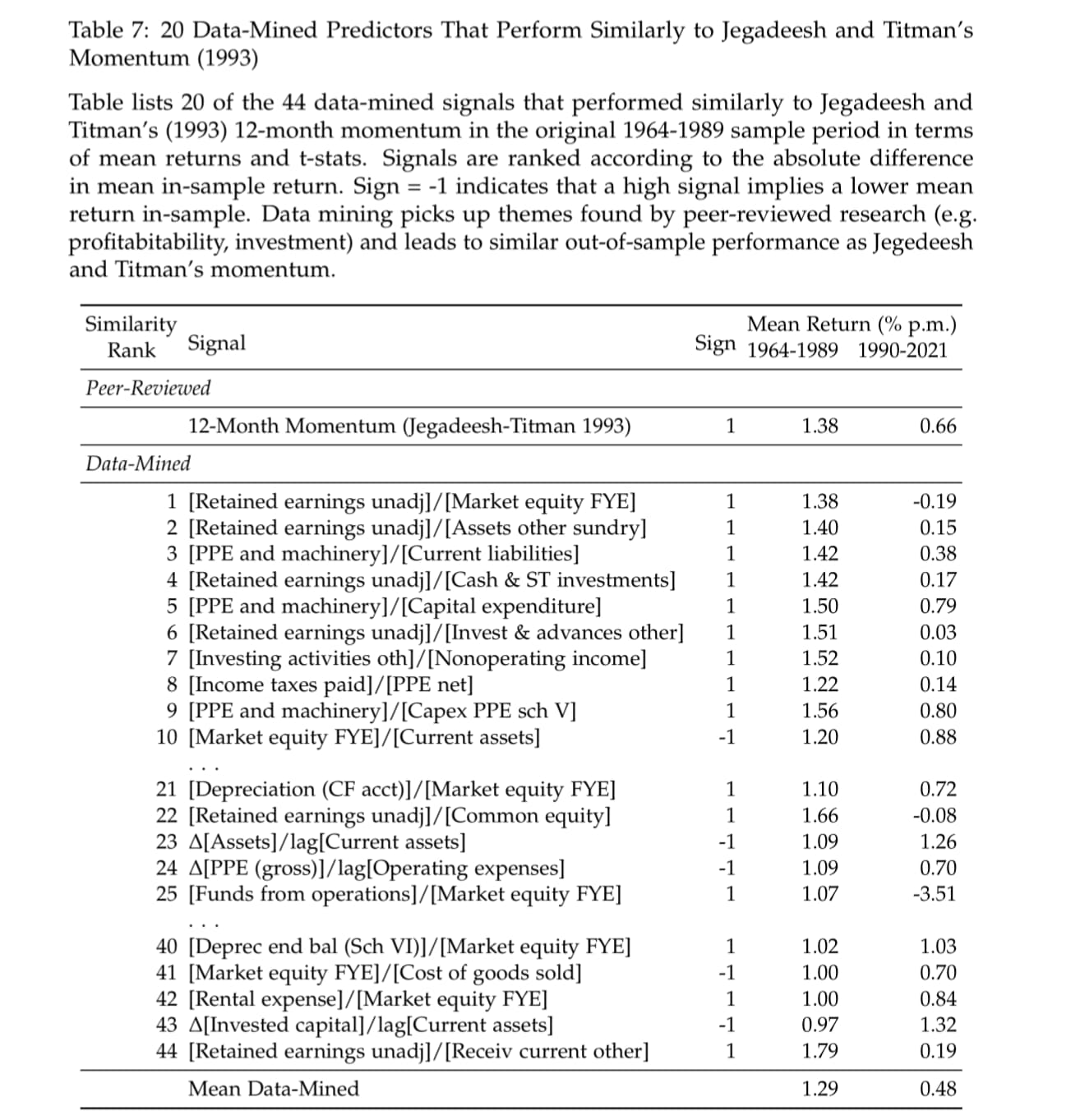
A.Y. Chen provides an interesting way of thinking about avoiding overfitting: the best way to avoid bias due to data mining is to do the most possible data mining to discover what is pure data mining and what are usable features. It is like his original title "How I learned to stop worrying and love data mining"
His papers are the best papers to allay my concerns about factor investing, far more so than the AQR-funded "No Reproducibility Crisis" paper, despite his personal and inexplicable pessimism about the present and future of factor investing.
From the Introduction: "We use empirical Bayes (EB)….Our data-mined portfolio is the simple average of the top 1% of strategies, based on EB-predicted Sharpe ratios.
With Empirical Bayes one can focus on the false discovery rate (and not worry about the t-score so much). One can data-mine a huge number of factors then decide what false discovery rate (FDR) one wants.
Set the FDR using empirical Bayes or the Benjamini-Hochberg procedure.
I agree with using EB along with the data-mining of a large number of factors. At least in theory. After data-mining, set the FDR to one's liking (probably different FDR for everyone and for another post).
SelectFdr (I.e., select a false discovery rate) for implementing the Benjamini-Hochberg procedure in Sklearn. Probably a lot easier than empirical Bayes for those interested.
So not as useful perhaps as there are no factors in this paper but ZGWZ and by extension A.Y. Chen have some interesting points. This is the A.Y. Chen (Andrew A. Chen) on the Board of Governors at the FED, I think.
The author is basically making the point that if the top 100 factors were the result of p-hacking alone then it would have taken about 1,000,000 years to find those factors (given the author's assumptions). A reductio ad absurdum proof that p-hacking cannot explain everything