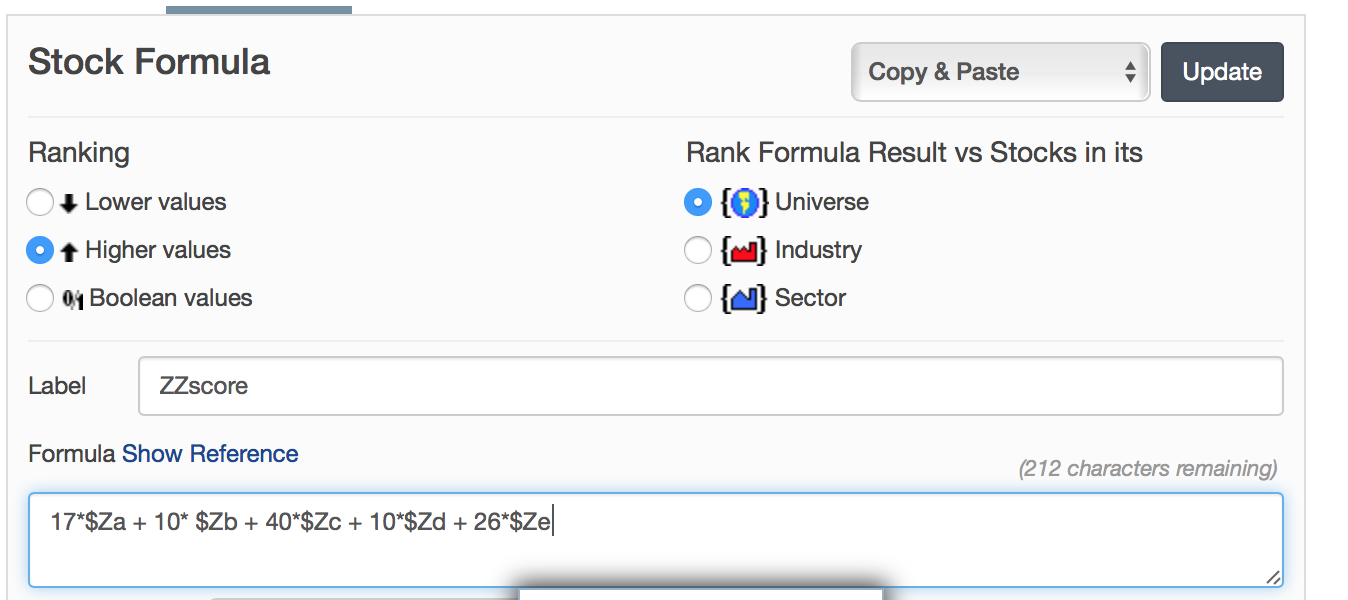
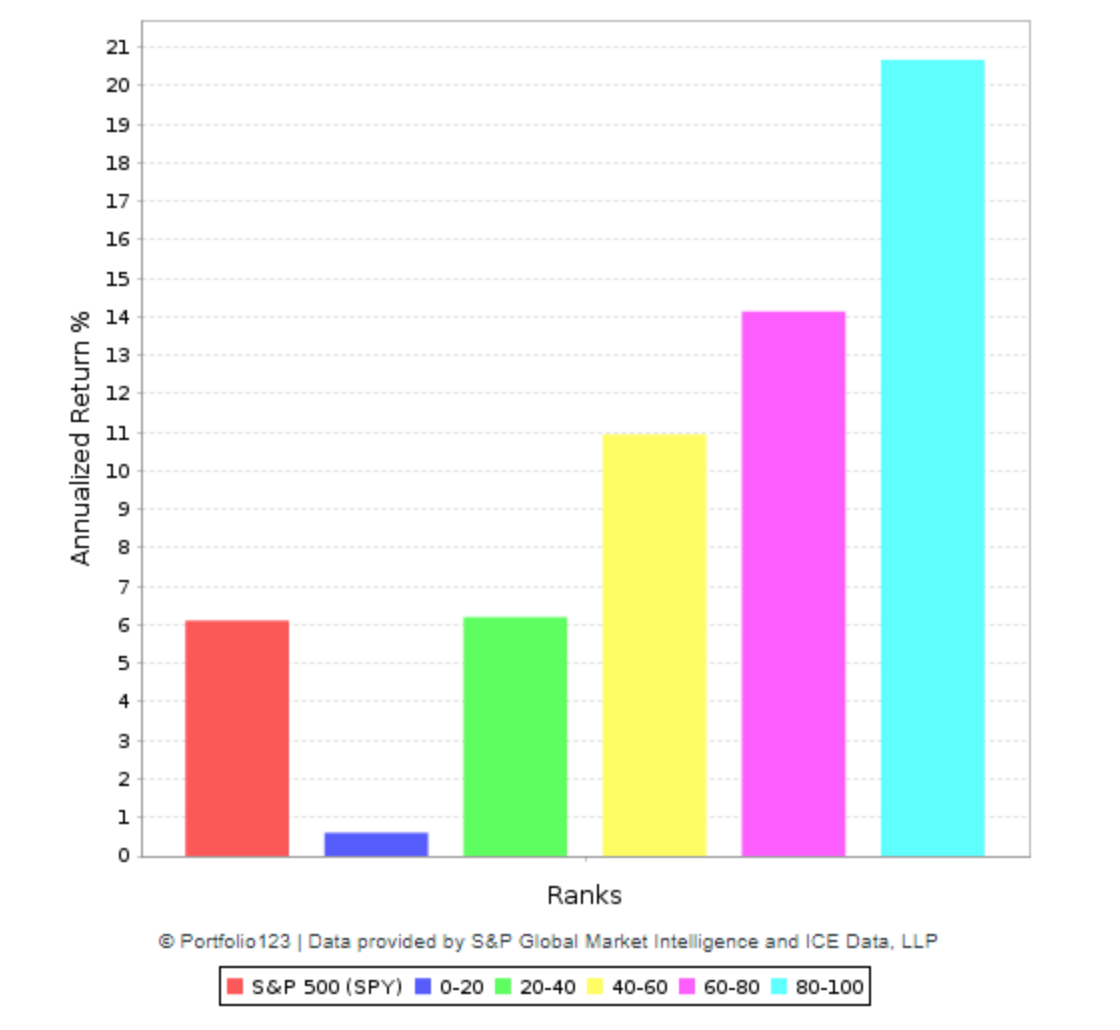
David,
Thank you again for bringing this back to my attention. This and “factor analysis” is something I have looked at in the past. I plan to spend a good amount of time on this this extended weekend and beyond to find where it can be useful.
For ranks, I wonder if it can be useful at all. I wonder (for ranks) if the best advice so far is not Peter’s (gradient descent). Note there are other optimization methods beside gradient descent such as an evolutionary algorithm. Steve Ager (StockMarketStudent) has even made a simple spreadsheet that uses the evolutionary algorithm that has been helpful to me in the past. Furthermore, it is similar to gradient descent (albeit probably not as efficient) in that it randomly changes all of the weights at once. You then select the weights in the optimizer that gave the best results and repeat. There is Markov Chain Monte Carlo Metropolis Algorithm (the basis for the Gibbs sampler for Bayesian statistics with JAGS standing for just another gibbs sampler being the latest iteration). But it is STAN that uses methods similar to gradient descent that is considered the most efficient (although it has not fully replaced JAGS yet).
I do not see how PCA could be used for ranks as the range (and the variance) for each factor once it is ranked is the same. Whether you are looking at market cap or Pr2Sales the range (ranks) will be 0-100.
Clearly PCA and ridge regression can be used for multivariate regression but there is the problem of getting the data dowloaded: as emphasized by Peter. Maybe this can be used if I ever add ClariFI as a service. But any limitations for ranks may apply to the ZScore of any factor once that factor is standardized.
Furthermore, before factors are ranked one might be able to tell which of these give the most variance but this says little about which is most related to returns. In an “all fundamentals” universe the greatest variance may come from market cap and market cap is (probably) related to returns. But is it more important that Pr2sales with regard to returns?
These apparent limitation are the reason I have not studied these subjects in depth so far. I intend to find where it is useful: it is a commonly use and certainly there are good uses (there has to be). And I intend to clear-up any misconceptions I have at this point.
I apologize if my questions are ill informed at his point but I intend to address this. I am not trying to make any points but rather trying to stimulate further discussion of this interesting—and I think important—topic. The re-examination of PCA, Factor Analysis and Gradient Descent have already been very useful to me.
Oh. And I intend to pull out my “Introduction to Linear Regression Analysis” Douglas G. Montgomery et. al. and not gloss over Ridge Regression and Lasso Regression this time. And review multicollinearity.
Thankful for the discussion.
Edit: so if you wanted to use the gradient descent algorithm for ranks you would start with your first factor and increase it a small amount (eg 5%), normalize the weights and run the rank performance test. If the results were made better (by your criteria) then you would repeat. If the results were made worse you would subtract 5% normalize the weights and repeat. When you did this and the results got worse then you would go back to the previous (better performing) weights. You would then do this with the second factor and so on. If you went back through this a few times–starting at the first factor–then you have done a gradient descent. It would easy for anyone using P123 to look into the potential problem of local minima and address this if you wanted to use this seriously.
And with the optimizer (and a spreadsheet to do the normalization) you could run through all of the gradients for one factor (weights 0-100) with one optimization. Select the best performing weights and move to the next factor. You would want to move through each factor several times. You could fine-tune later with 1% increments (gradients). This would address the local minima problem to a large extent.
Probably start the optimizations with equal weights for the factors. Presumably after a few runs things would be moving in the right direction (greater or lesser weights for the individual factors).
You have to love multivariate regression. It is a great machine learning optimization tool: easy and usable before the advent of computers. Now there are other methods worth considering
-Jim