I think a better way to do “out-of-sample” tests is to use the evenid = 0 and evenid = 1 universes. Another way is to use the more recent period as your in-sample and a period prior to that as your out-of-sample period. I would hesitate to use a strategy that was developed without regard to recent changes in the way people invest. As I’ve written before, recency bias can be profitable. If I were to choose between a strategy optimized over the last eight or ten years and one optimized over the eight or ten years before that, I would unhesitatingly choose the former.
One of the designer models boasted average annual returns of over 100% with a five-stock portfolio. I don’t KNOW that there were complicated buy and sell rules, but it’s not easy to get 35X turnover using ranking alone. Since it was launched five years ago, it has had a 4% annualized return (compared to the S&P 500’s 9%).
Yuval,
I used even/odd universes extensively at one time and it clearly adds something. But it it should be no surprise if data from the same time period behaves the same and gives the same results—one is fooling themselves if they think this is much proof of a good system. de Prado cemented my view on the limitations of this method in his book (Advances in Financial Machine Learning).
I am sure you did not use this method for your correlation studies that you mention—for good reason I would say.
But I encourage the use of even/odd validation if that is anyones preferred method.
Of course, no one in machine learning (including de Prado) would run a live port without the latest data. Once the method is validated all of the data is merged and optimized again: THIS IS TRUE WHETHER YOU USE EVEN/ODD UNIVERSES TO VALIDATE OR WHETHER YOU USE OUT-OF-TIME DATA. So, this really is not a way to separate the 2 methods. And many—including De Prado—would continue to optimize with the new data before each rebalance. So, no one would argue against using recent data no matter how they chose to validate their methods.
Whatever cross-validation method is used, preventing this is the goal. A good cross-validation would have.
-Jim
Then that must be a clearly exemple of overfitting.
Maybe we can avoid that by apliying rules more generic and close to the median? For instance; If ROE>12 is what best performs then choose around that figure, but not the same exactly…
Cross-validation—well done—will expose the most egregious problems with overfitting.
The above is a little dense mathematically, and the rest of the chapter involves consideration of correlation and problems with the data not being IID. All under the category of b “leakage”[/b] problems. But this is the reason you cannot use just any random sample. If the data were IID you could use an even/odd universe method for cross-validation, for example.
BTW, the fact that our data is not IID (the core problem mathematically) was first presented to me by SUpirate1081 and pvdb. It stung a little bit—at the time—to learn how messed up my techniques were. But their input is much appreciated considering the goal is to learn and make some money in the process. Just giving credit to these guys. CyberJoe understood this too but he grew tired of us and is gone now.
But you do not have to understand every mathematical detail. You could just follow the portion in bold (my emphasis). Test on data that is AFTER (in time) the data you use to train the data. Ultimately for reasons that are similar to the reasons you use PIT data in your models (a no-brainer).
P123 cannot stop the problems of overfitting in the Designer Models and has to enforce a valid out-of-sample test by not allowing people to invest in the models until there is (some) valid out-of-sample data. Well done P123.
But if you are worried about your own models (and your money) you can use your own (preferably valid) out-of-sample cross-validation methods.
-Jim
Jim, can you please let us lesser mortals know what IID stands for. I know what PIT means.
deleted
Georg,
IID (independent and identically distributed). It is beyond the scope of my post to detail the importance of this. But I can summarize: IT IS IMPORTANT TO EVERYTHING. Rather than debate this I refer you to any text that tries to cover any of this including dePrado’s text.
Examples,
Use of even/odd universes. These two universes may be identically distributed but they are not independent. Indeed, these are the most correlated samples (and therefore NOT independent) you will be able to find. Use them but know the limitations.
I would not paint everything we do with such a broad brush. But is can be dangerous, indeed, when we ignore some basic ideas.
-Jim
Jim,
Thanks for bringing up and explaining the important point that each data point is not independent.
Scott
Simple systems will likely underperform because transaction costs can’t overwhelm that the market knows about them already.
Complicated systems are not likely to outperform because of overfitting.
So we’re basically preempted from alpha unless we can develop/leverage robust and unique methods and/or data.
That’s not to say that the journey can’t be enjoyable.
David,
At least one professional would seem to agree:
-Jim
Georg,
My apologies for a short—and somewhat frustrated–answer previously. I do not seem to be very good at writing about some of this. If anyone is truly interested then people smarter (and better at writing) have written chapters about this, with editors. Better than a few posts from me if there is true interest.
Indeed, de Prado solidified this for me and could probably clarify any questions. He is a principle for a company that invests more than $217 Billion (AQR Capital Management). If you want wisdom from an immortal (a rich and well-trained one) that is truly where you should go (for $15.09 at Amazon). But that should not stop me from trying to give my best answer to a good question.
IID, as I posted before, means independent and identically distributed. The lack of independence gives a preference for how we cross-validate.
An example is best. Let us suppose you wanted to see how a regression strategy (or optimized P123 rank) works and you wanted to TEST the strategy from 2009 to 2010.
I was addressing one simple question. Should you TRAIN the system from 2004 to 2008 or should you TRAIN it from 2011 to 2015?
So depends on what you are looking for perhaps. But if you are interested in how well the system is likely to do LOOKING FORWARD then you should LOOK FORWARD. The training data should be before the test data. You should train from 2004 to 2008 and test using data from 2009 to 2010, for this example.
If you use the data from 2004 to 2008 you are training before the recession which may have changed the market. Maybe interest rates and a bunch of other things changed too. But it is a fair test. Because the regression (rank) was not trained on that information that was not available before the test period. This makes it a fair test of the system.
If you TRAIN with 2011 to 2015 you ARE training on a different market. You are training on data (and information) that you could not have possessed, at any price, in the 2009 to 2010 time period.
It could be that when you test after the recession you will do well but only because you had a set of data (and information) about the market after the recession to train with—which would have been impossible for you in 2009.
Using data that is not PIT is just an example of using INFORMATION that would not have been available at the time. Here you are using information and data to train your system. Data you could not have gotten through the SP500 (or anywhere for any price). It is also A LOT LIKE look-ahead bias.
Anyway, just wanted to give the best answer that I could. And, admittedly, I probably did not do as well as a principle in a 217 billion dollar investment firm (de Prado is a principle for AQR Capital Management). Someone who had several chapters to develop the idea. Also he probably did not have any errors in his math—which I may have done.
This mortal thanks you for your question. De Prado—who, obviously, communicates with the immortals—is a better source if you have a true interest.
And you could just use data that is forward in time if you want to see how your model is likely to perform going forward. This is common sense that a few mortals do posses.
Sorry if that still does not answer your question. But I will stop before I copy and paste an entire chapter and the references;-) You can do that on your own if you are interested.
I appreciate the question.
-Jim
Jim, thank you for this informative response - we can learn a lot here at P123.
So, open question… should we add the Yuval’s ranking system to the P123 Ranking system list or not?
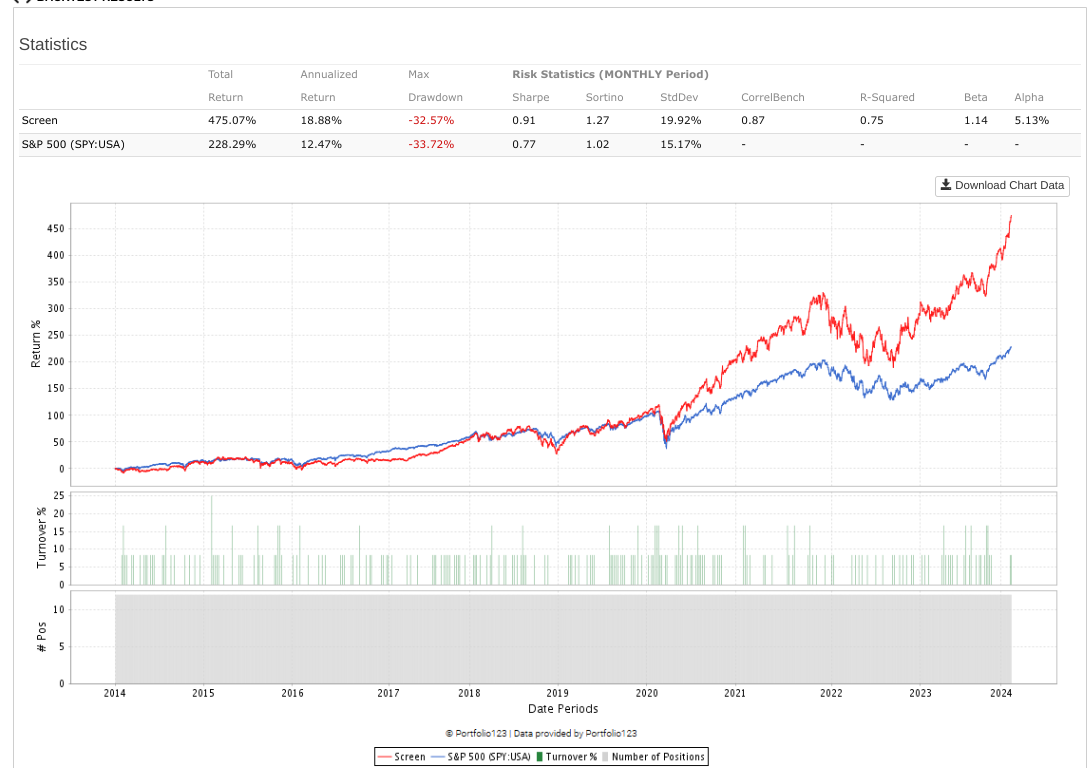
So, I wanted to resurrect this simulation and see how it had done over the past 4-5 years (essentially OOS). My observation is that it replicated the S&P with no improvement in alpha.
- Thanks to Yuval for providing something public that we could look at many years later.
- Does anyone else have a different story for success in Large Caps?
- Does anyone think alpha factors can still be exploited in Large Caps?
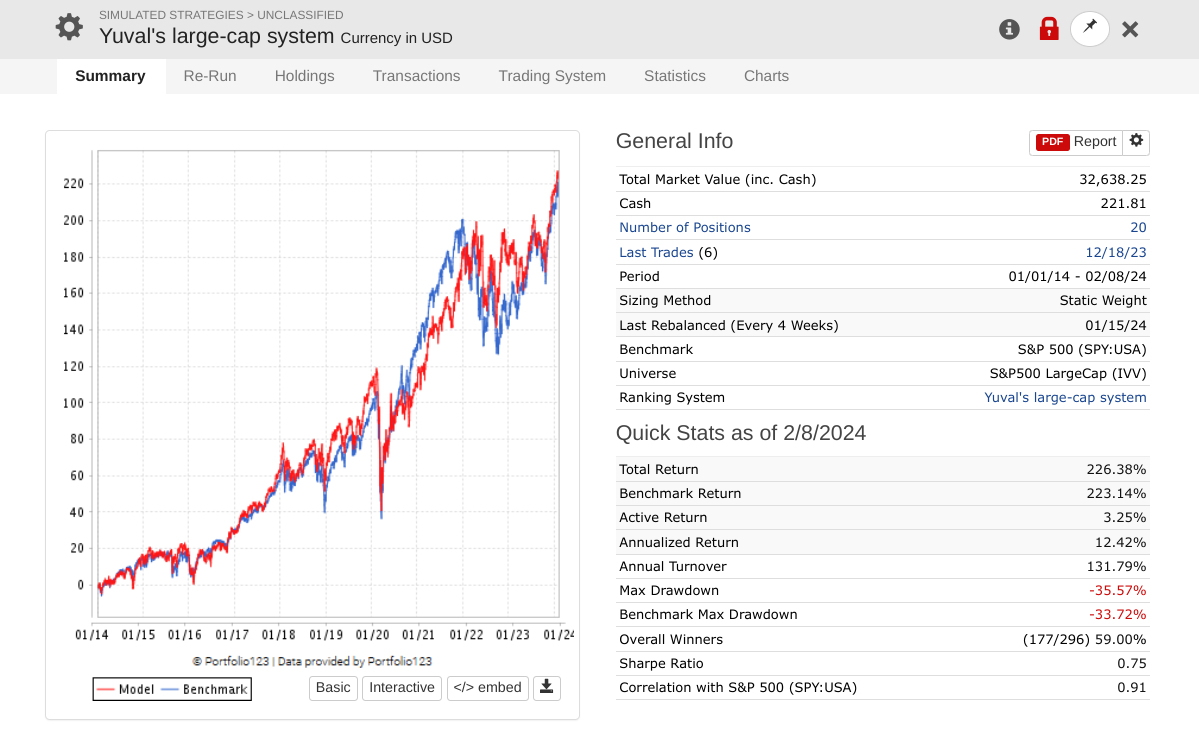
I think it’s very difficult to get alpha in large caps out of sample. I have not been able to do so. I hope to be proven wrong.
In my opinion, large caps are best for very long-term holding. They provide a good cushion. If you thought you might die tomorrow and wanted your inheritors to profit from the stock market without your knowhow, designing a large-cap model that specializes in very stable and reliable companies with an annual rebalance might be a good idea. Alpha might be elusive but risk might be minimal.
1 Like
personally success with large caps, my methodology is I only invest the tech sector, weekly rebalance, never more than one to five stocks in the portfolio, I do not require any edge to make $$$, the SP500 index is momentum, no momentum you are out of that index, every year or so, new inclusions ( all sectors ) to the index prove themselves over the next year or so, some of the vola in the tech sector is fantastic and you got the liquidity, muy importante, from my previous market experience with smallcaps, even when you have the dinero to invest can pose all type of problems, to the point you become the market, generally for the average investor its liquidity, the better the liquidity the lower the investment return, the more diversification the less return, the ranking from P123 that are very useful are growth and sentiment, anyhow you gain avg annual 15% more or less over 15 years, reinvested you make your madre and pappy cry with happiness for the sueno americano, for example see this link for the vanguard total mkt fund, from 1994, also exceptional performance from 2008, annual growth at 10%, Backtest Portfolio Asset Allocation, and this is a big diversified fund, anyways success is long term strategy ( sales = earnings as simple as and try not to be a seer) and keeping to the strategy thru thick and thin. addendum Backtest Portfolio Asset Allocation 4 tech stocks from 2012 not even well ranked until recently $10K to $100K ( inflation $86K ), thru thick and thin, most is about head space,
Screen that selects the 12 best stocks from the SP500
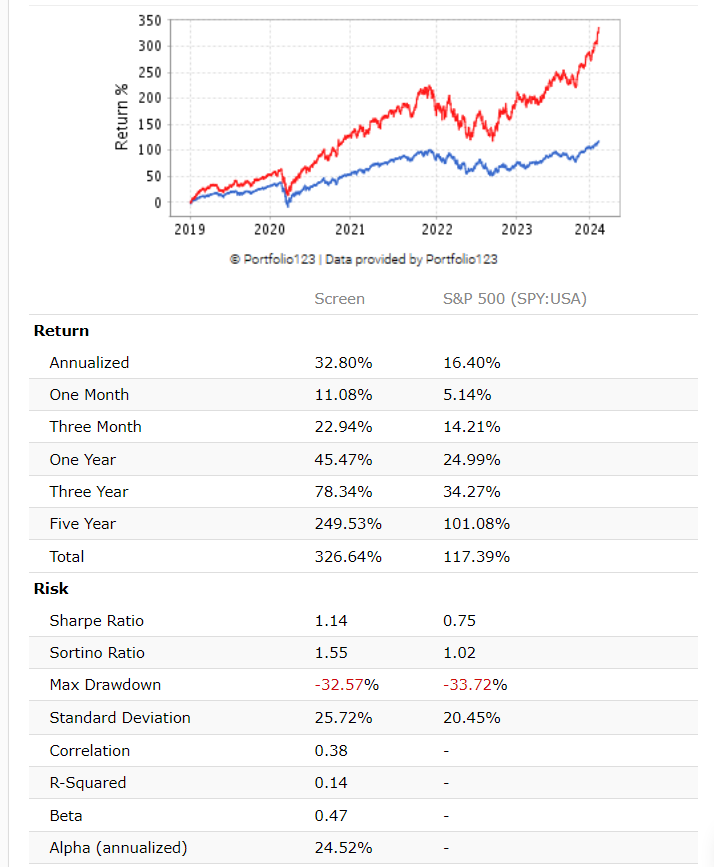
https://www.portfolio123.com/app/screen/summary/292174?mt=1
1 Like
Yuval, could you develop a ranking system for selecting REITs that will be standard in P123 ?