Dear All,
Here's a preview of what's coming for our AI Factors, We hope to release it all next week.
Intelligent Features
Our AI Factors right now use Machine Learning (ML) algorithms with tabular data. Not exactly revolutionary, but I think we packaged it well. However, our normalization options are non-existent: we only do cross sectional normalizations vs. either the entire dataset or by date.
In this new release, you will be able to add more sophisticated types of normalizations that are entirely orthogonal to the existing ones. These normalizations do additional processing before sending it all to the AI backend. In essence, we are shifting more intelligence into the features. Since our backend is relatively dumb (compared to AGI, LLMs, etc.) it makes perfect sense to give it a little help.
Here's the kind of normalizations you will be able to do, and what we are calling them:
- Default Normalization: The current method, a.k.a. the Preprocessor
- Normalized Ratio: Take the current value of a stock's ratio (like Pr2Sales) and compare it with historical values for the same stock. The normalization used depends on the Preprocessor setting (ex. zscore)
- Regression Growth
- Regression Surprise
- Regression R²: Calculate the regression of the previous values for the stock, and use one, or all, of these statistics. See the LinReg() function for more info.
Below is a screen shot of the new Features page, all generated without writing a single formula using pre-defined features.
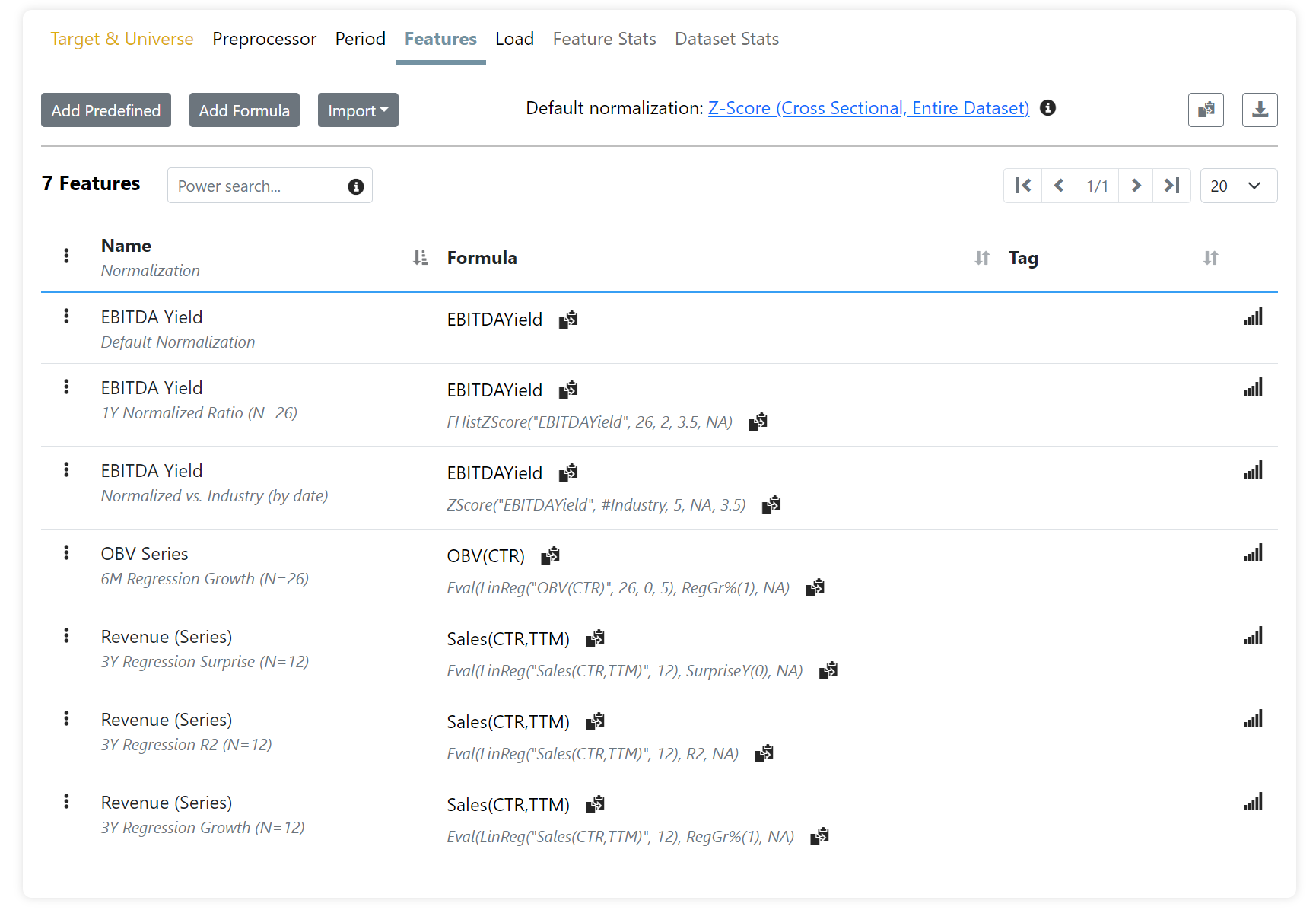
PS. These more intelligent features were always there for anyone to use, but you need to write very complex formulas, which is very error prone and frustrating.
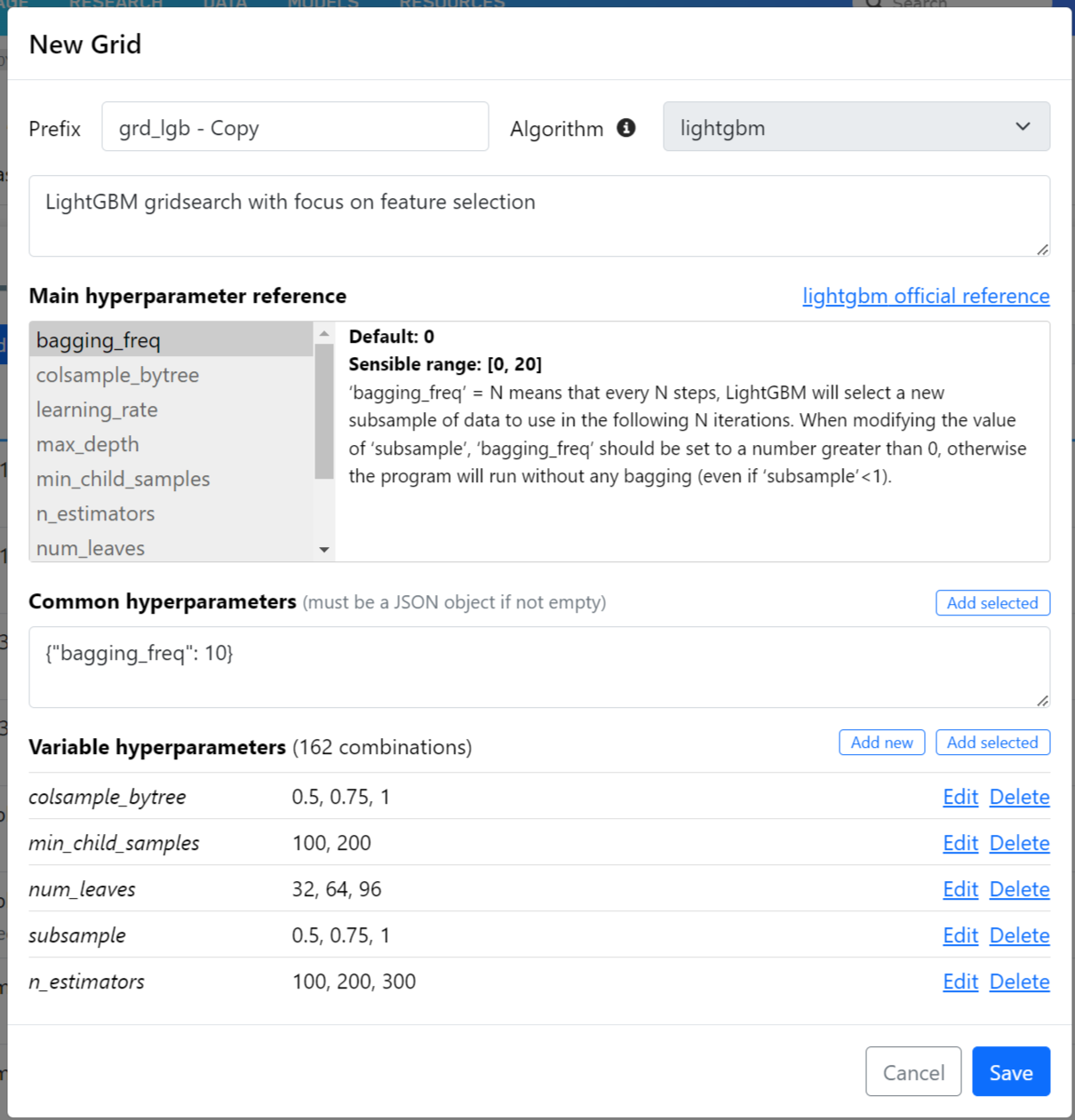
Grid Search
A way to easily test hundreds of hyper-parameter combinations. The models are generated automatically and easily distinguishable. Further refinements to the Reports section will enable you to identify the best hyper-parameter combinations.
We're also adding very helpful reference for the hyper-parameters for creating your own models.
Screenshot of the grid search set up (we also added several pre-defined one).
Categorical & Macro
We're adding support for categorical features by allowing you to turn off preprocessing. For macro series we're adding the normalizations mentioned above, which might help for stock predictions.
That's all for now.
The only other major area we have not addressed for AI Factor is better feature engineering tools.
Cheers