Dear All,
Yes, it's finally coming together: our fully integrated AI/ML product we call "AI Factors". We're doing testing right now, and I just wanted to share some screenshots. Of course it's still just a tool: garbage IN will still give you garbage OUT, and it will take time to learn how to best utilize it, but it is living up to our expectations. We will likely do a limited release initially. More info soon.
Couple of details
- The target below is the 3mo future relative performance in a small cap universe.
- The portfolio performance is calculated by concatenating the Validation Holdout periods.
- We have four validation methods: Basic Holdout, Time Series CV, Rolling Time Series CV, blocked K-fold CV (shown below)
Without further ado, please meet AI Factor
Cheers
Fig 1. Features Page
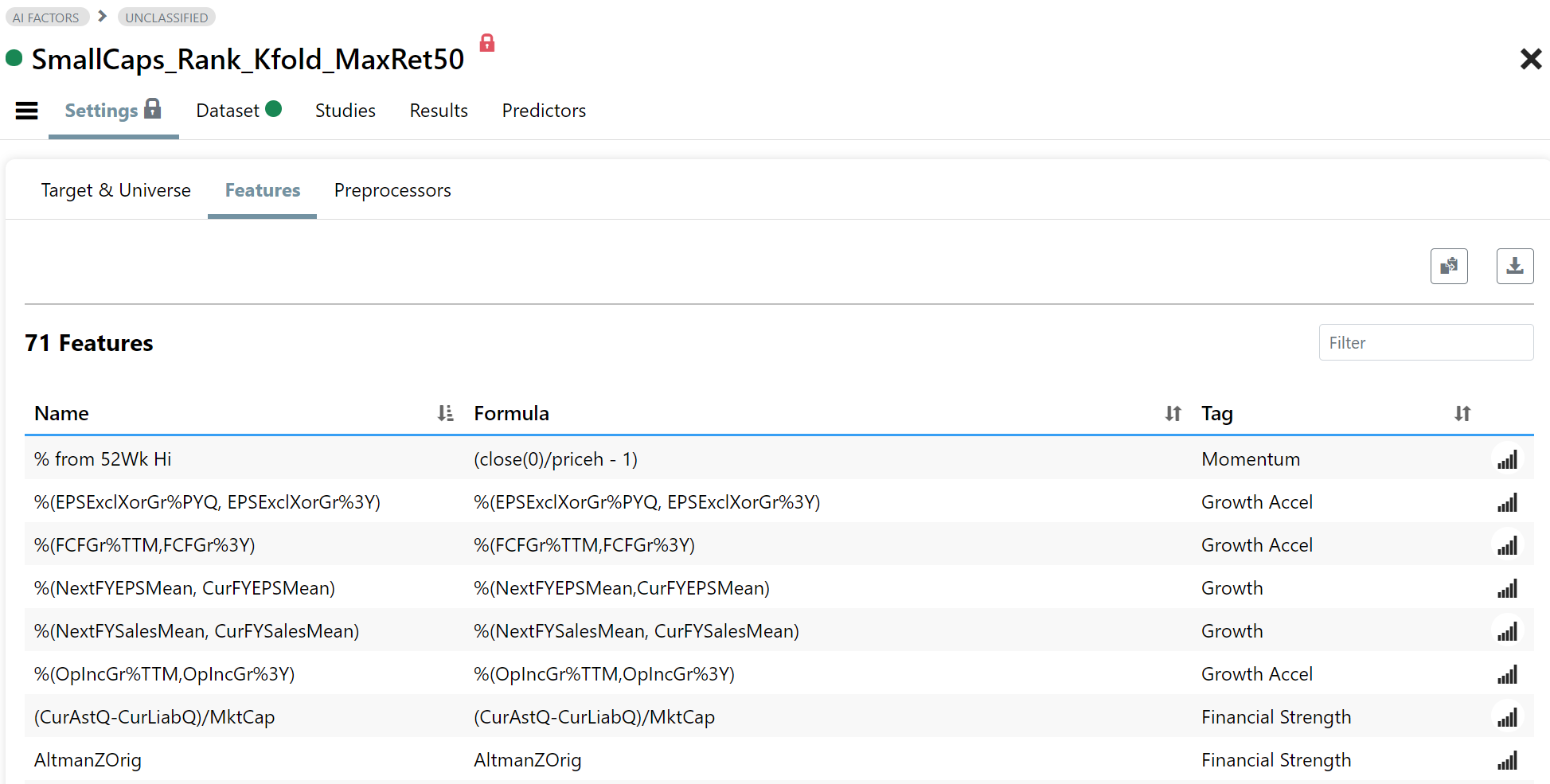
Fig 2. Validation Setup
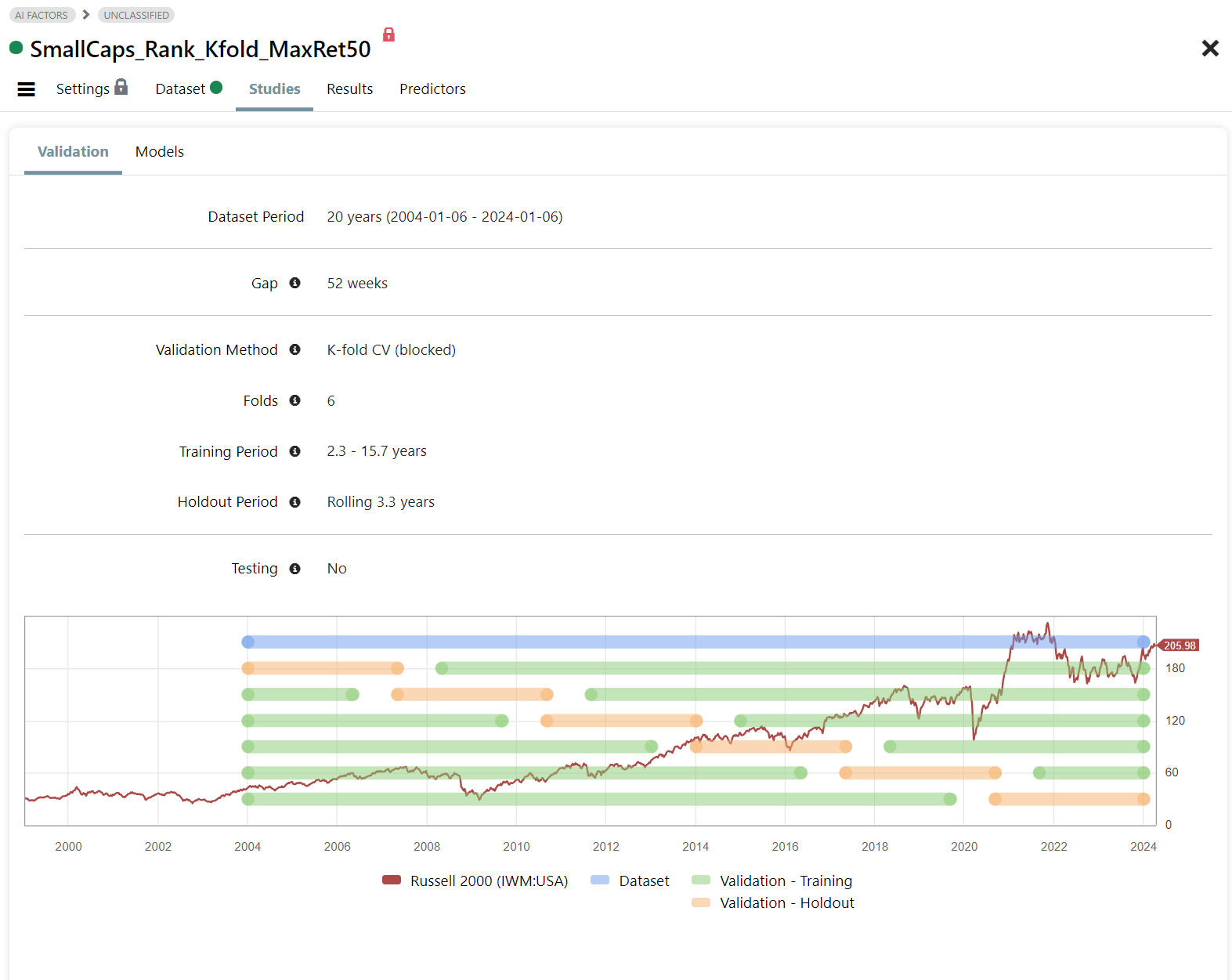
Fig 3. Models for Validation
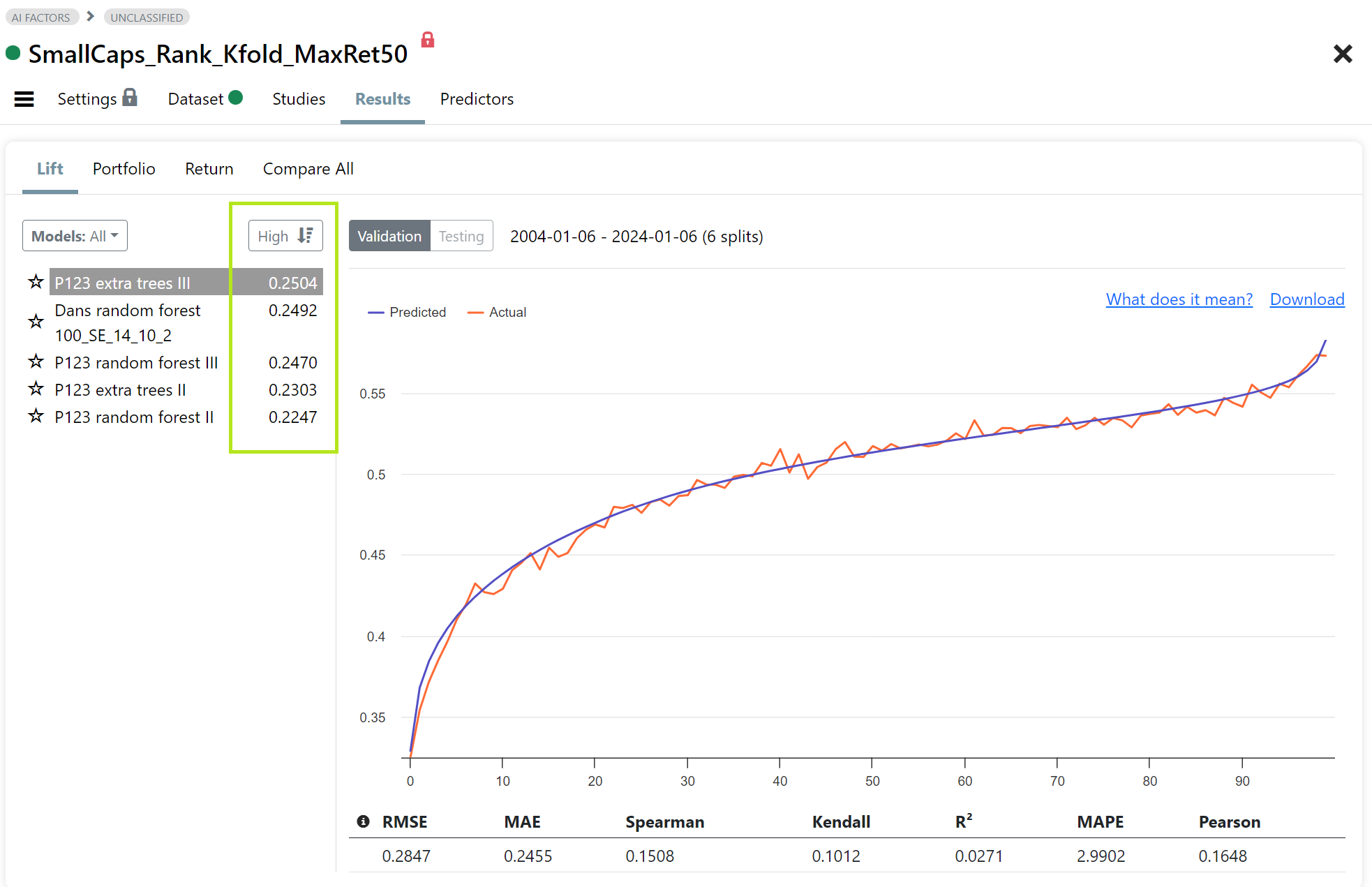
Fig 4. Results: Lift Chart
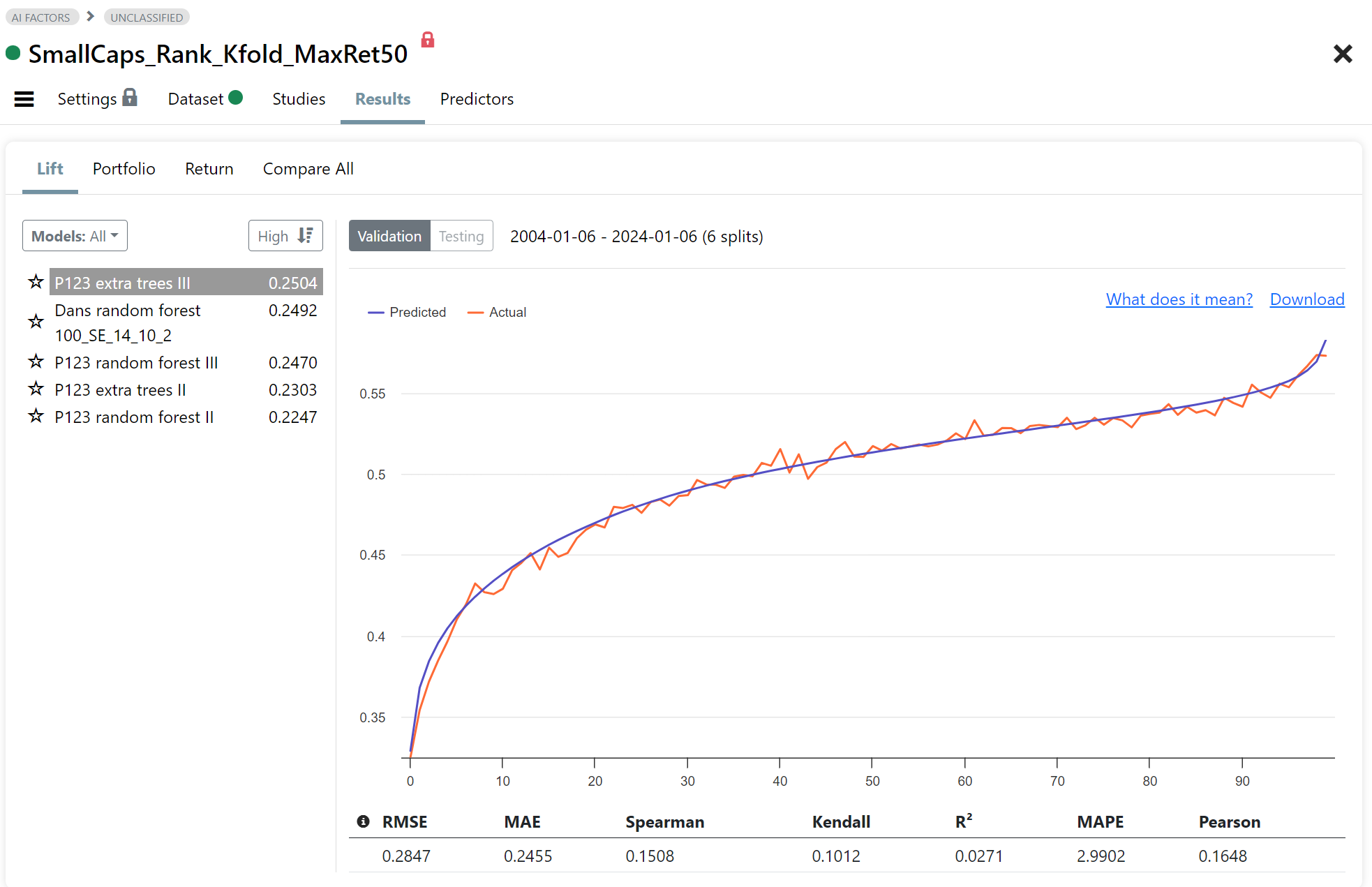
Fig 5. Results: Portfolio (H=top decile, L=bottom decile)
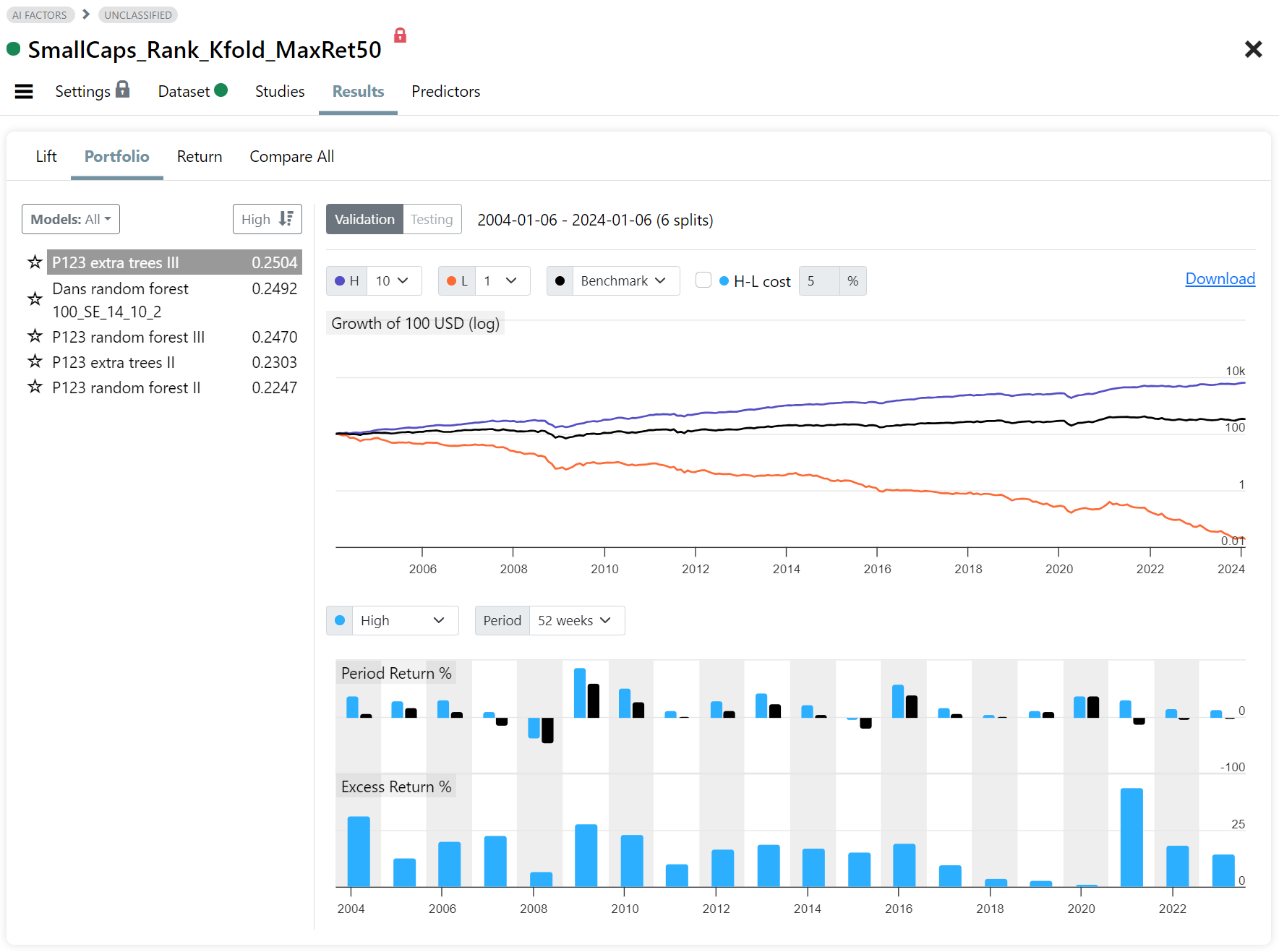
Fig 6. Results: Annualized returns for prediction deciles
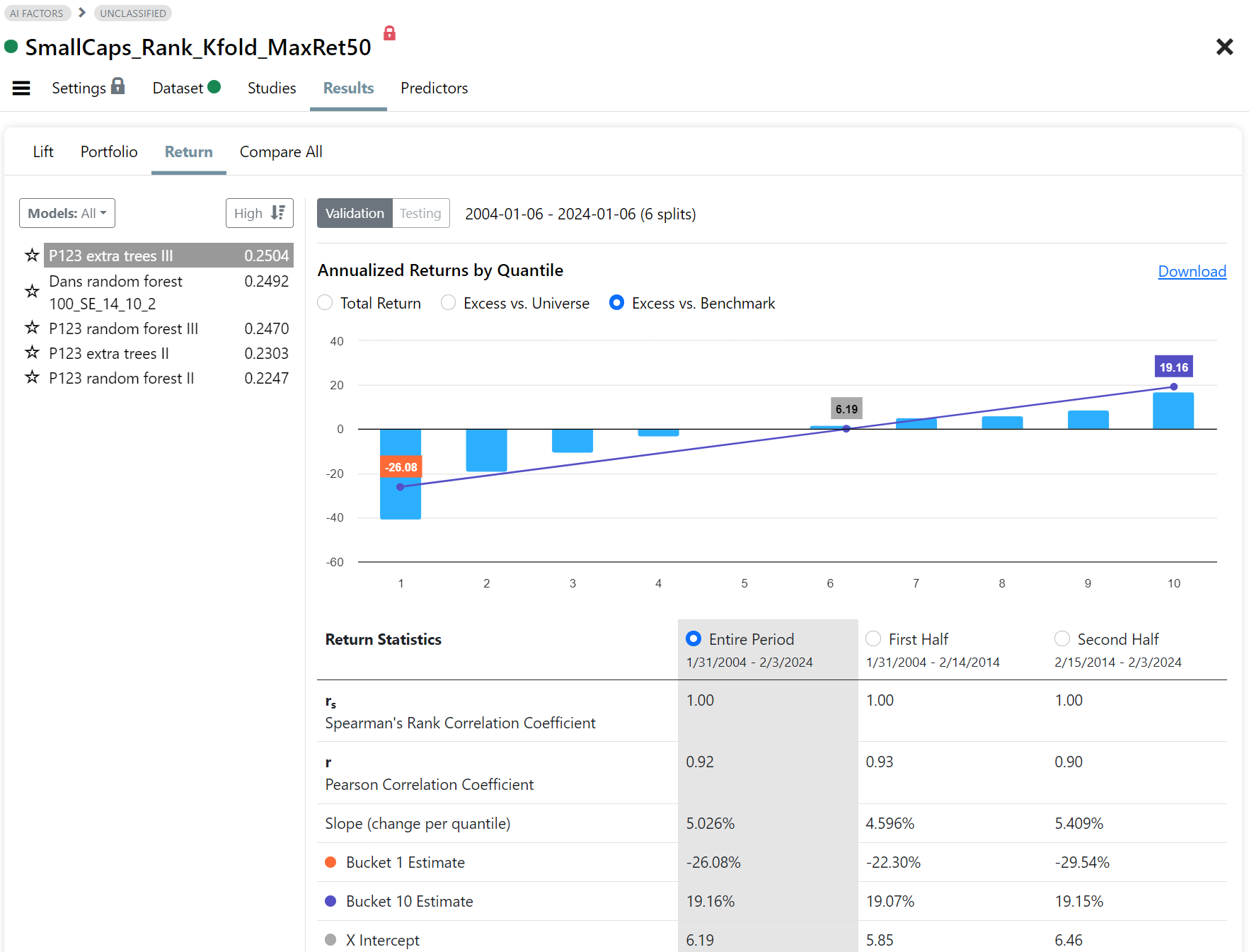
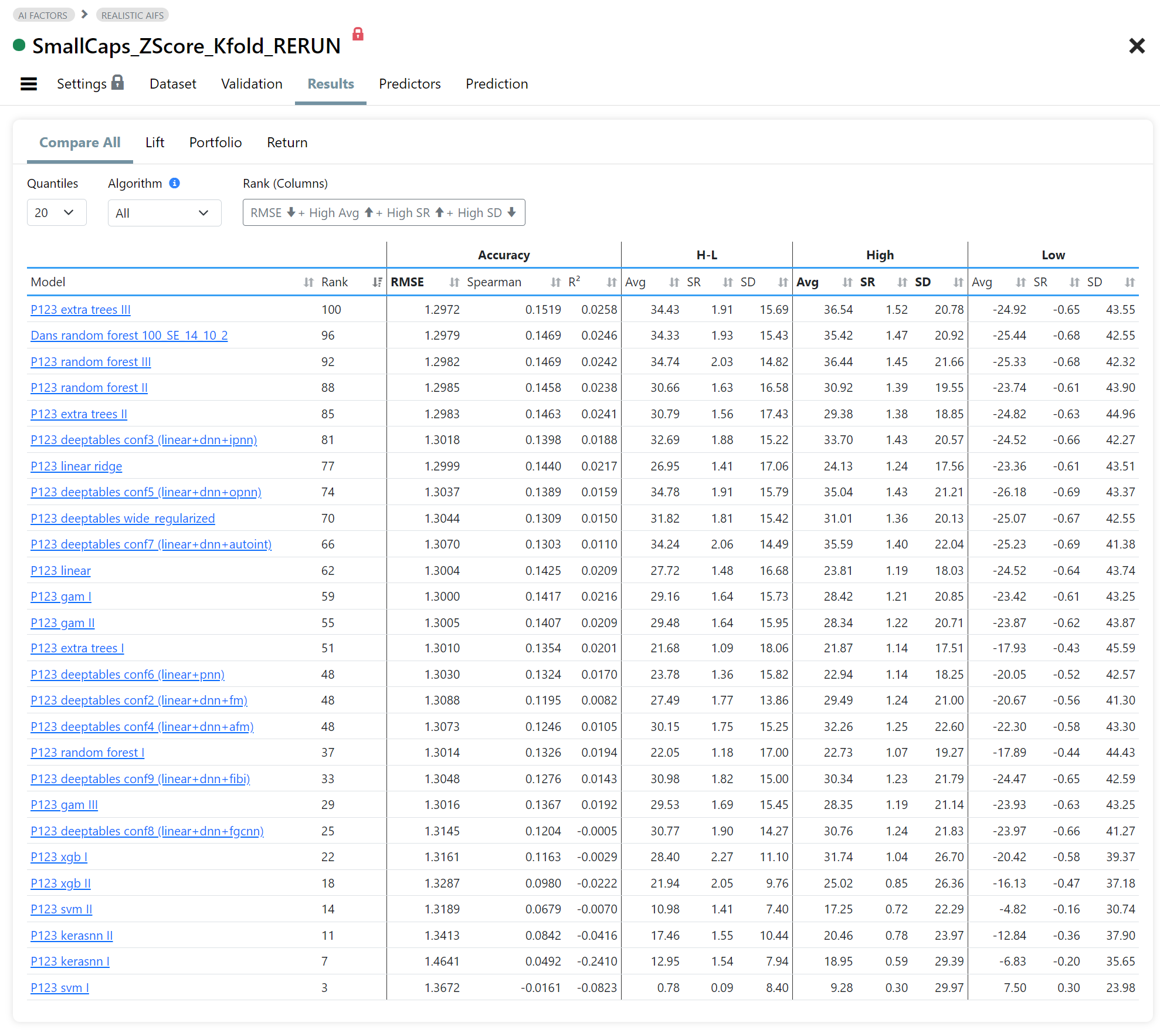
Fig 7. Compare Results
Table that compares accuracy statistics and portfolio statistics for each validated model (H=top bucket, L=bottom bucket, H-L=long short). The table is sorted by Rank which is a composite score of user selectable stats.