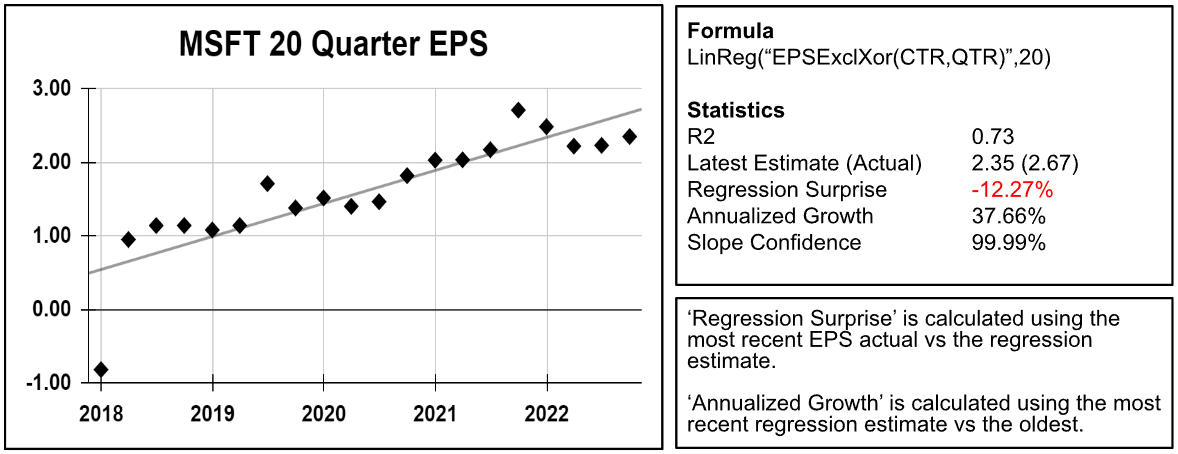
A complete set of regression functions and factors are now available for screening and ranking. These are a great way to deal with outliers. Below is an example with Microsoft's 20-quarter EPS regression. As you can see the growth rate of 37.66%, calculated using the regression, is not affected by the 2018 outlier.
Some of the things you can do with regressions include:
- Find stocks that have a positive EPS slope (growth) with a good fit (low volatility).
- Rank stocks based on their combined regression statistics: slope, R², and growth.
- Find stocks where the latest EPS is above or below the regression estimate.
To use regression functions, you will need an active Ultimate or higher membership (or equivalent). You can also use regressions during a 21-day trial.
You can find all relevant documentation and examples in the factor reference.
Below are some examples and excerpts from the documentation. We hope you find these new features useful. Please let us know if you have any questions!
Cheers,
The Portfolio123 Team
Examples
To use regression, you need to use a LinReg function, then you can use factors to access the statistics. Multiple regression in your formulas are allowed using precise placement: regression factors access the most recent regression formula preceding the factor.
Time Series Regression
To find stocks where the 10Y sales regression has: 1) a positive slope 2) a good R2 of at least 0.8 and 3) latest sales above the trend, you could type the following
LinReg("Sales(CTR,ANN)",10)
R2 > 0.8 and Slope > 0 and SurpriseY(0) > 0
XY Regression
To find company where the latest EPS is above the expected EPS for a given revenue you could do the following:
LinRegXY("Sales(CTR,ANN)","EPSExclXor(CTR,ANN)",10)
SurpriseY(0) > 0
Spreadsheet calculation
Click here to open a spreadsheet example of all formulas
FORMULA FUNCTIONS ➞ REGRESSION FUNCTIONS
The following functions evaluate a regression:
LinReg("Formula(CTR)", iterations )
LinRegVals(y0,y1, …. y50)
LinRegXY("X-Formula(CTR)", "Y-Formula(CTR)", iterations)
LinRegXYVals(x0, y0, …, x50, y50)
The first two are time-series regressions where the X is not supplied and represents a period of time. The “XY” regressions are general regressions where the X is explicitly supplied.
FORMULA FUNCTIONS ➞ REGRESSION STATS
The following statistics are available after you calculate a regression:
R2, SE, Slope, SlopeSE, SlopeTStat, SlopePVal, SlopeConf%, Samples, Intercept, InterceptSE
These statistics have a parameter
SurpriseY( offset ), EstimateY( offset ), EstimateXY( X ), RegGr% ( period = 1 )
PREBUILT SMOOTH FACTORS
For every fundamental line item you can find predefined regression factors for the most recent estimate and for the annualized regression growth. We predefine them for two periods: 5Y of TTM values sampled every 6 months and 10Y of Annual values. You will find these Smooth factors in the reference of each line time. For Example these are the Smooth factors for “Sales”
Prebuilt regression factors are available for any membership.
| Factor | Equivalent to |
|---|---|
| SalesRegEstTTM | Eval(LinReg("Sales(CTR * 2, TTM)", 10), EstimateY(0), NA) |
| SalesRegGr%TTM | Eval(LinReg("Sales(CTR * 2, TTM)", 10), RegGr%(2), NA) |
| SalesRegEstANN | Eval(LinReg("Sales(CTR, ANN)", 10), EstimateY(0), NA) |
| SalesRegGr%ANN | Eval(LinReg("Sales(CTR, ANN)", 10), RegGr%(1), NA) |