Thank you Yuval. EVERYTHING gets blamed on over optimization. Yuval presents evidence that the answer may be more nuanced. Nuanced enough that I am sure I do not have an answer now. Maybe someone else does. But it should be looked at rationally as Yuval is doing here.
If P123 can do it they should run the Designer Models WITH NO SLIPPAGE and see if that takes care of the problem. It could be that our result are fairly random with the guaranteed drag of slippage. It may be a simple answer.
Yuval posted an excellent reason that timing should not work most of the time (the market is usual up). P123 should see if they can look at this as a potential problem.
We now have some pretty convincing evidence that optimization of sims has some sort of problem—whatever that problems is. GEORG IS JUST CORRECT ABOUT THIS, PERIOD. Yuval presents anecdotal evidence that optimization may not be the problem or at least not the entire problem. Please correct me if that is not what this study shows or if there is another more important lesson from the study.
P123 hired an AI expert who looked at Random Forests. They were understandably frustrated with the fact that this was no better than Random. RANDOM IS LOOKING GOOD NOW AS THE EVIDENCE WE NOW HAVE SHOWS THAT RANDOM FORESTS ARE BETTER THAN SIMS.
Sims are not Random but are statistically inferior. The “null hypothesis” that sims are equivalent to a random selection of stocks from the universe can probably be rejected.
This specific experiment should be done to be sure this statement is true. Someone with knowledge of this LIKE GEORG should do a paired comparison of sims with equal weigh of factors that seem good and compare this to a random selection of stocks from the universe. Perhaps P123 could randomly select from the 50 factors that they gave to the AI expert for this. Do this enough times to get an answer (this is NOT rocket science).
P123 was going to look at support vector machines (hire the AI expert to do this). I think this can work ALONG WITH FEATURE SELECTION. The SVM must look a nonlinear solutions for this to work.
P123 should look for proof of concept. See if machine learning can work. Once it is shown let the P123 members find the best solutions and sell them as an expanded version of Designer Models. Of course, proof of concept may be desired first.
The first attempt at machine learning—with a Random Forest—seems to be better than sims already. At least it was not shown to be a way to steadily lose money.
I have few answers. I have some anecdotal evidence that machine learning can outperform sims. I certainly do not have access to enough data to prove it.
If P123 could find something that is proven to work with an intelligent selection of factors it would be helpful to their business model. This may be a proprietary method owned by Renaissance Technologies at this point. Maybe, knowledge is not owned by anyone. But it is NOT rocket science.
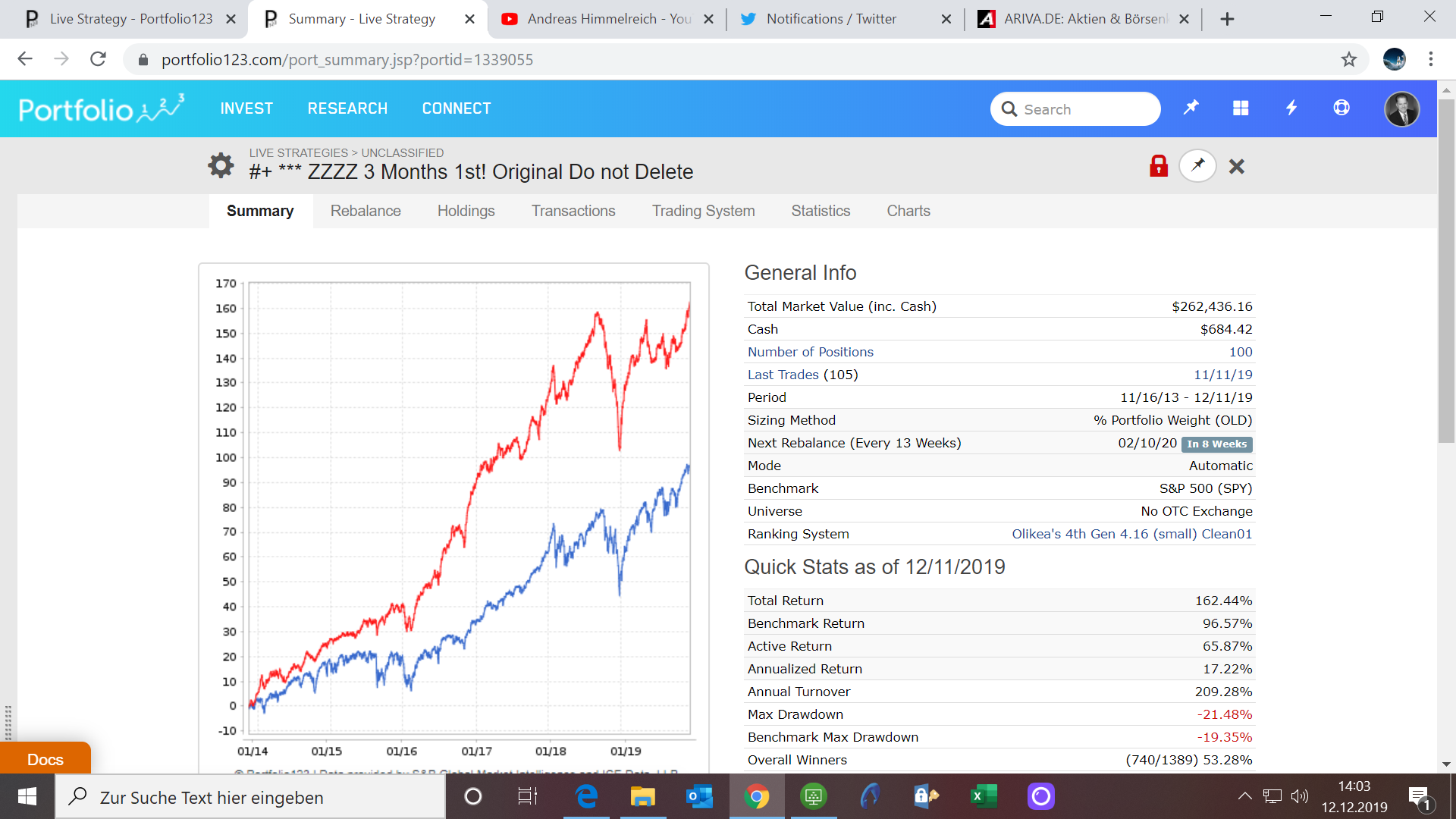
I do not think hiding the fact that a port is generally a method of gradually giving away your money is a good business model. A t-score of 11 is a tough handicap. People will eventually leave P123—because they have no money to invest if for no other reason. I miss Oliver Keating. Some of his GREAT IDEAS are performing terribly. Why did he leave? He is smart enough to know when something does not work. I would have bet that DennyHawles’ models would have work. Why didn’t they? Just market timing?
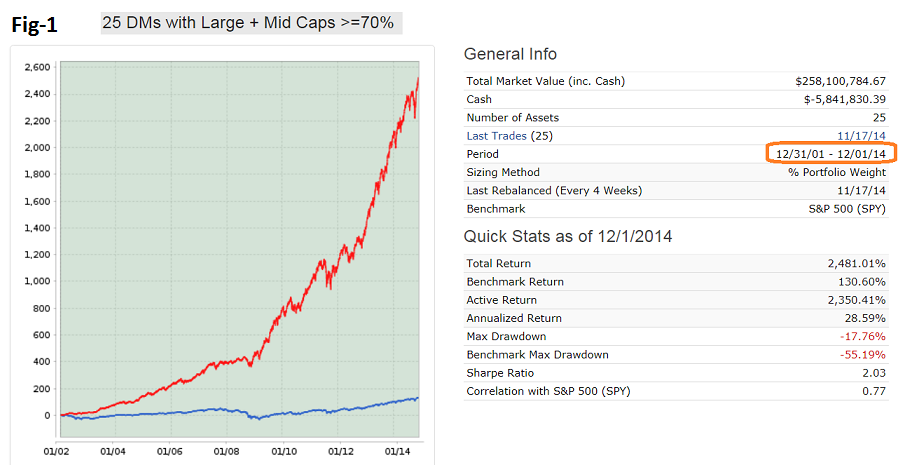
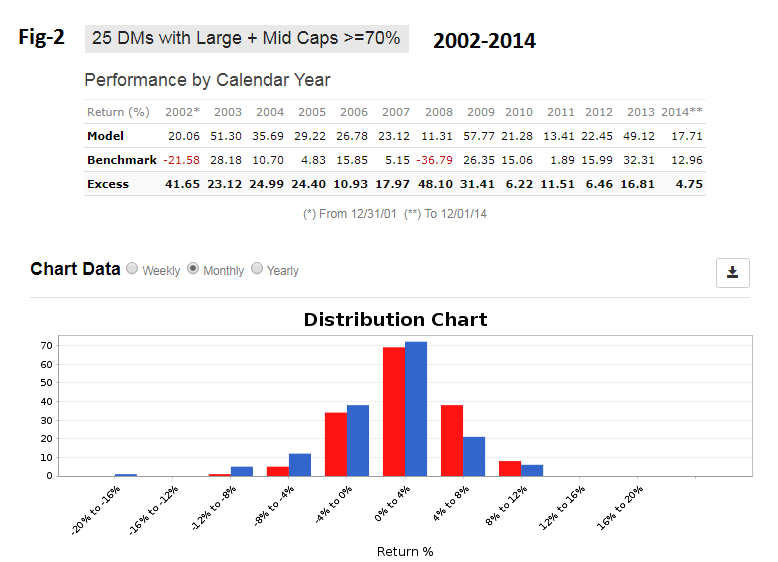
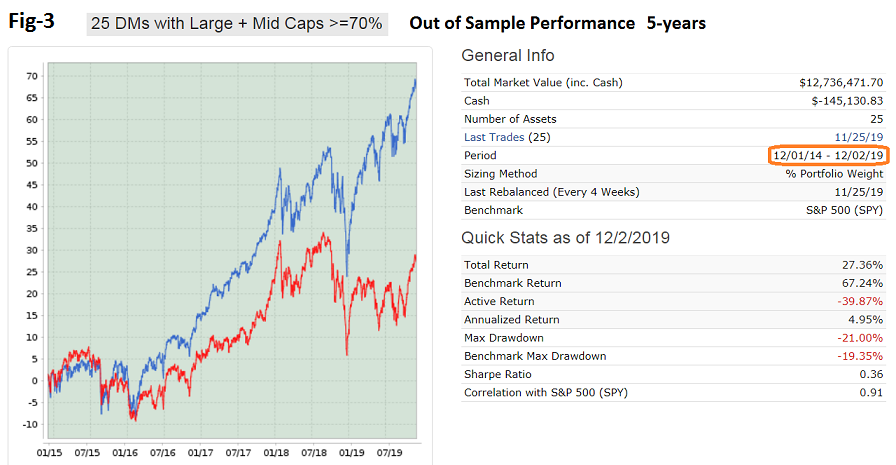
I had extreme respect for Oliver Keating!!! If his sims cannot perform then mine cannot either (long term). This is simple fact. Since he is gone now, because he has a large number of sims (24), and because there is no recent survivorship bias we could look at his stuff (with other good samples). 2-year excess returns -26. I have not looked at his 5-year excess returns. Denny’s models speak for themselves with out any statistics.
I have been a big fan of P123 but I am not going to chase a bunch of cherry-picked backtests. If the sims I have now (that have done okay out-of-sample up until now ) do not rebound in a year or two I will move completely to a method that uses price data to select Sector ETFs. I will probably stay with P123 to get this data. But Yahoo has this data.
I would check slippage and timing first. I am not saying I know here in December of 2019. But I will know at some point (it is NOT rocket science). I do not know if P123 will be with me then. So far they have been hostile toward finding out—with Yuval’s study here being (perhaps) sign of a change at P123. It is a first step.
-Jim

{kind=link}
{kind=link}