Georg,
Thank you.
Shouldn’t P123 hope this is overfitting? I think they should.
Twice you mentioned AIC which will stop overfitting in its tracks. I leave it to you to try to explain how you would implement this to the staff at P123 and the members—if you think anyone (other than me) will listen to you the third time. I think they should.
AIC is good. I also like LASSO regression. That would mean using that m x n array I keep mentioning to do a LASSO regression. But once the features are selected you could move back to a rank performance optimazation with the selected features. BTW, LASSO or AIC would not use much computer resources.
Result: no more overfitting. Gone, nada, none. Zero, zip overfitting. The big goose egg….
Ultimately I would use something related, myself, but I doubt we will get past AIC or LASSO regression in any discussion.
Anyway, I think P123 should hope the problem is the easily addressed problem of overfitting and give us the tools to end the problem (if that is what the problem is). P123 should hire a consultant if Georg is not understood by P123 staff this third time.
It is NOT rocket science. But you cannot read a post about this somewhere and become an expert either. Georg has obviously studied this to know this as well as he does. But I am going to stick my neck out and say that despite his obvious training and credentials he might not have been a “Rocket Scientist.”
Okay, it helps to be a Rocket Scientist or Engineer like Georg. People should really listen to his ideas about AIC and maybe some of the other methods of addressing overfitting. If overfitting is the cause of the poor Designer Model performance if would probably pay to hire a consultant to make sure Georg is understood.
-Jim

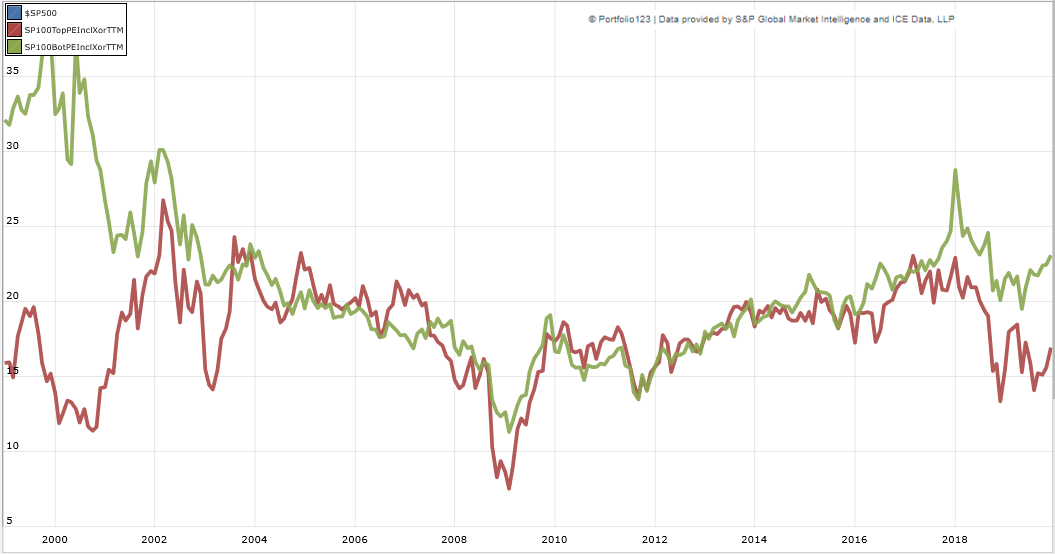
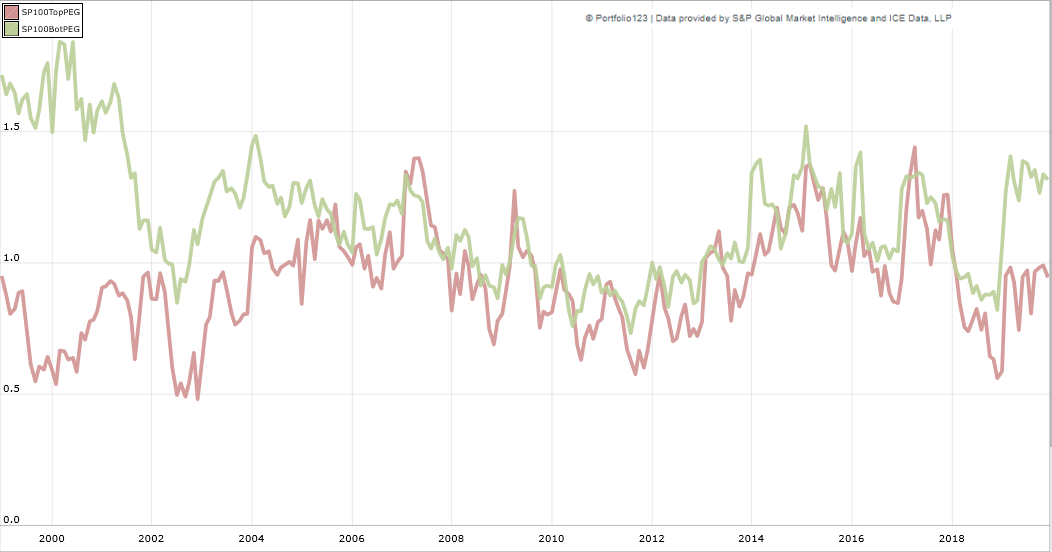
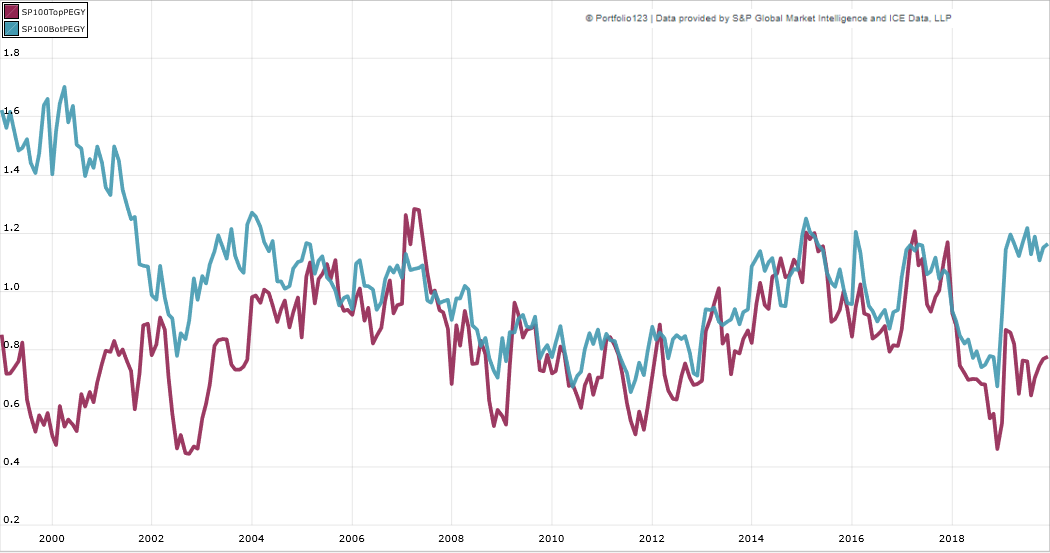
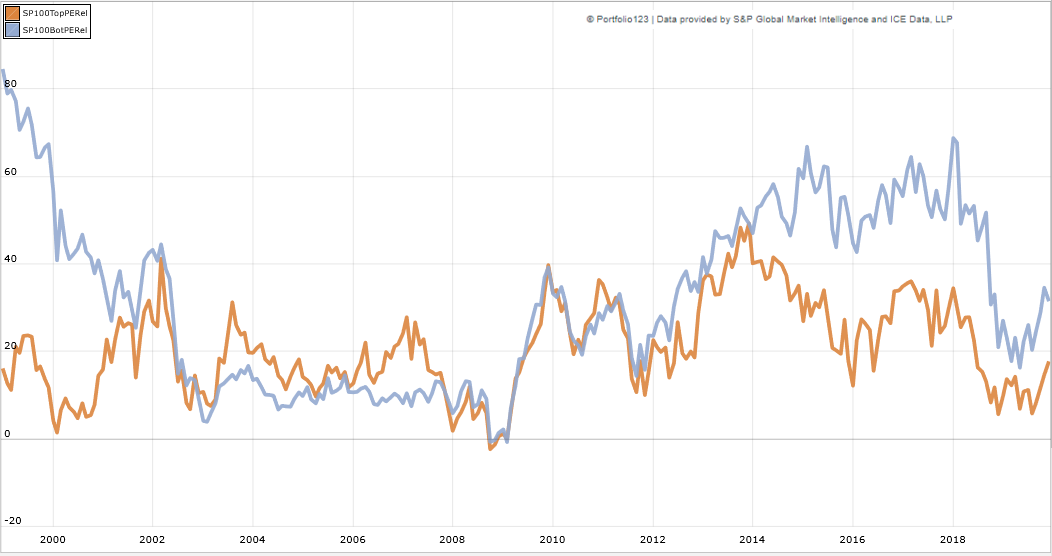
{kind=link}
{kind=link}