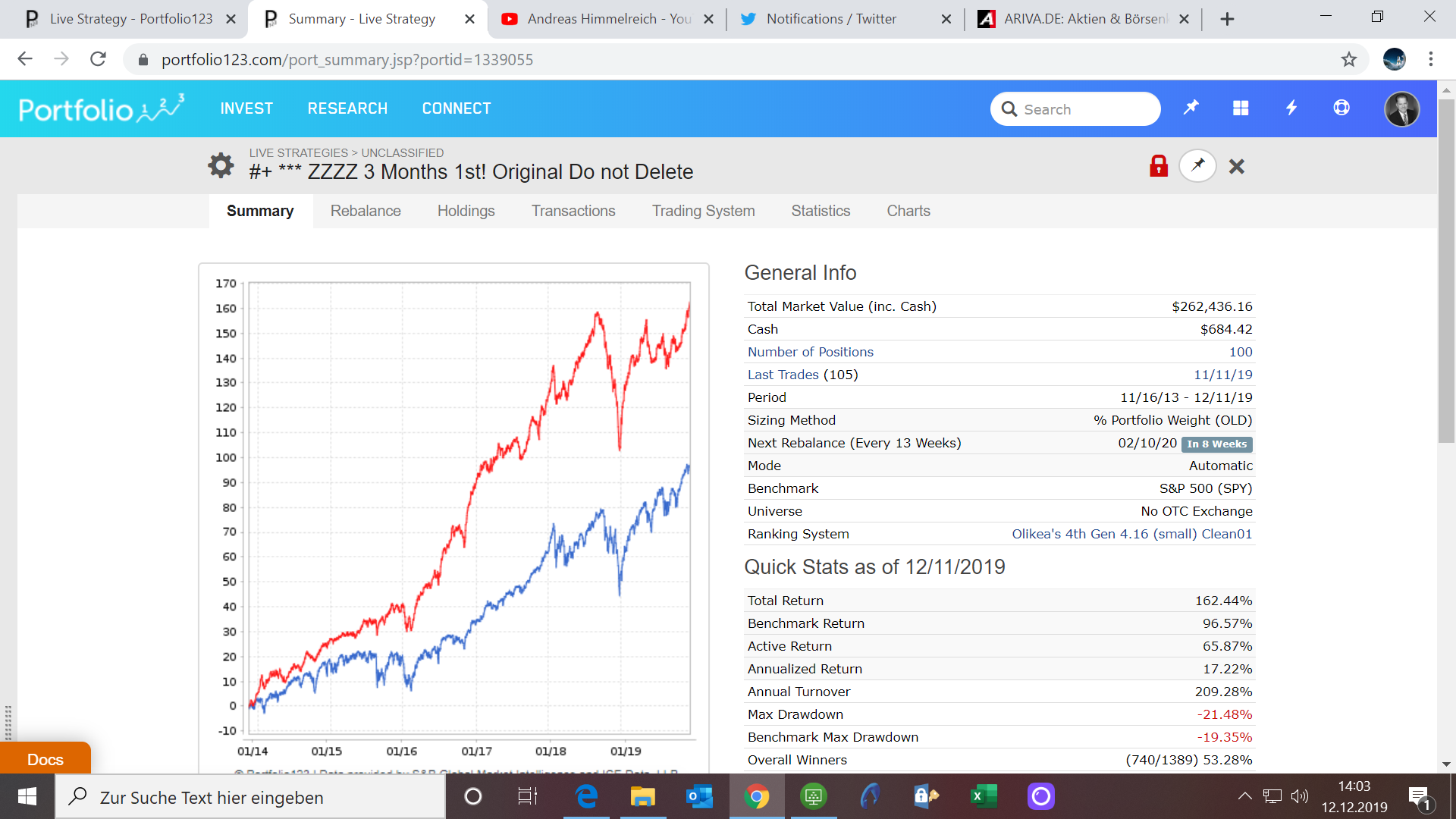
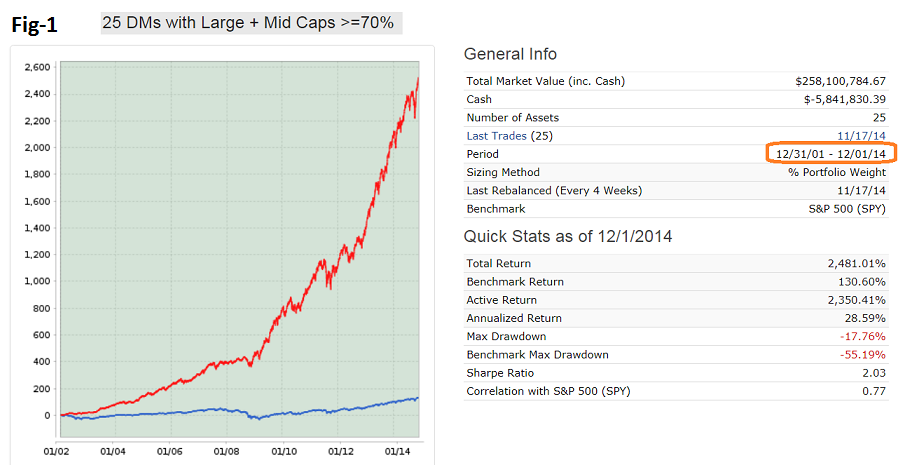
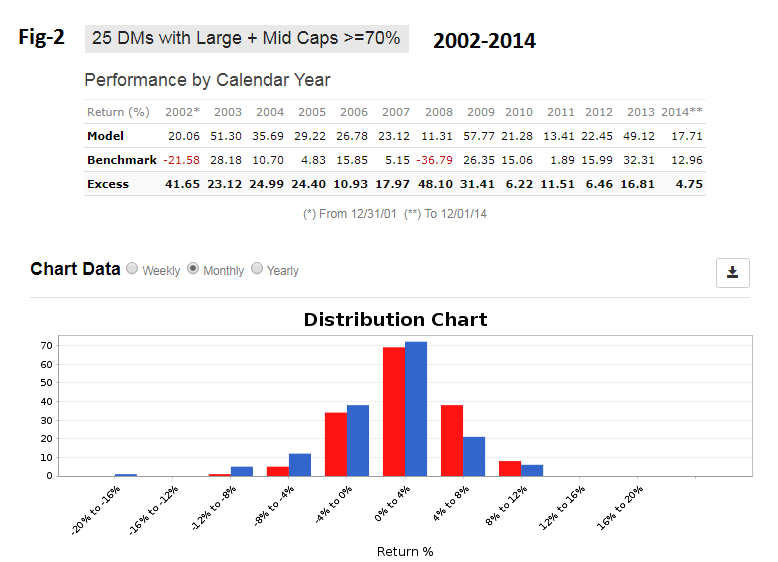
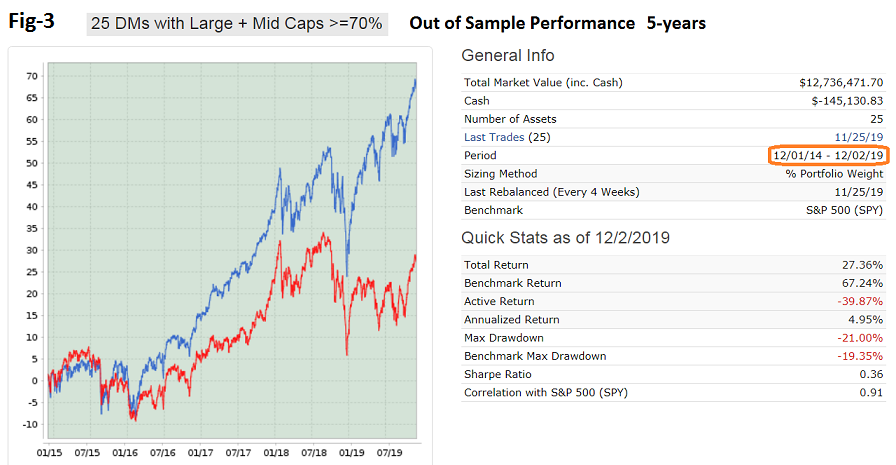
Jim, sorry to answer so late.
My post relates not to black box systems. I know I shoot me in the foot here, but I personally would never trade a black box system and I actually would not recommend it.
I might trade one but only if the provider would give almost everything away (like on a 1:1 ZOOM session where he or she shows me at least the ranking system and reveils it and does the robustness tests life together with me).
The reason: you need to have 100% trust in your system if you want to trade it and you have at least I need to have test it on robustness (1, 3, 5, 10, 20, 50, 100, 200 Stocks, different caps (nano, small, mid, big), evenid =1, evenid = 0, different universes (US, Canada, Nasdaq 100, Sp500), at least all sectors, if not at least 20 industries and sub industries) and then looking at the capital curve (no statistics, bc. they do not capture the tails, at least the once I know).
Also on every factor I use, I need to find at least a dozen researching papers from akademia (my favorite OSAM), If they can not backtest it
for much longer timeframes (like 1870).
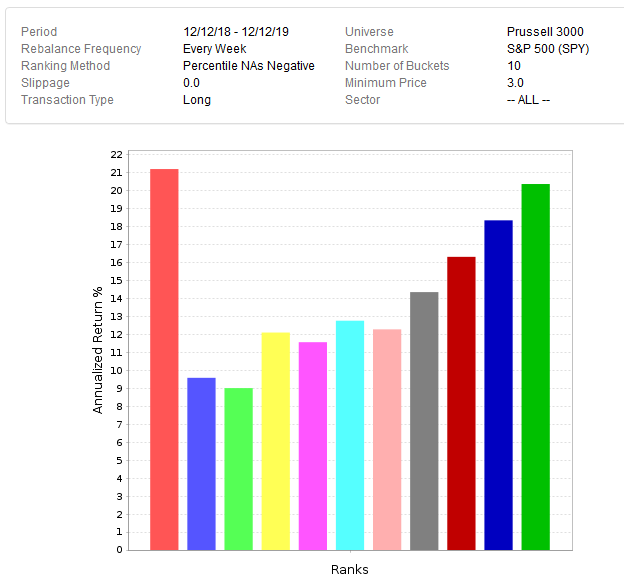
Also, I always look, that my system that I trade has a lot of degrees of freedom. That means as less buy and sell rules as possible and a lot of stocks
left in the universe (I look at the screen of the buy rules, if there are less then 1000 Stocks I am not using it and get rid of buy rules).
For example: I have a trading system that works great on the overall market and this trading system works almost perfectly on
the sector healthcare, but I do not use it (the healthcare version) simply bc. the overall stock count on healtcare is to low for me, I am to scared
that something might happen to the sector and I am dead in the water. I give up performance bc. I do not want to get even near to overoptimisation.
I know I might let something on the table, but the closer I get to optimisation, the less confident I will be to trade it.
Last step is to find an assumption on why the factor works, and if this is not assumptionable by cycle behaiviour or simply emotions, I do not use
it no matter how good the backtest and the robustnes test was (though this step is highly subjective).
That is also the reason why I would never trade a system where I do not understand the methods that are used. For example AI stuff where even
the backtest change from run to run.
the Job of my coach is not to understand all this, but to keep me in the process. he asks: ok. lets go through the process and make
sure you have done everything concerning to your rules. Then he asks, o.k., trust your sellf (in an event of a DD that is hard for me).
My main point is: For me, following above rules, P123 is already perfect (I might want to have a function where the system buys more stocks when it is 20% down, if you know how to do this help me :-)), also bc. its already a lot to do to follow this rules. Something new I would probably not use until I have mastered the fuctionality set of todays P123 and I have not yet, maybe I am at 30% (though looking forward to international stocks and how my modells do there, bc.
its perfect for robustness testing). I want to master what is in front of (and that is 80% my mindset and only 20% P123) me. it is me, not the function
that is missign on P123, that is my point.
This process is 100% based on what I learned since 2010 here with the p123 Comunity.
Best Regards
Andreas