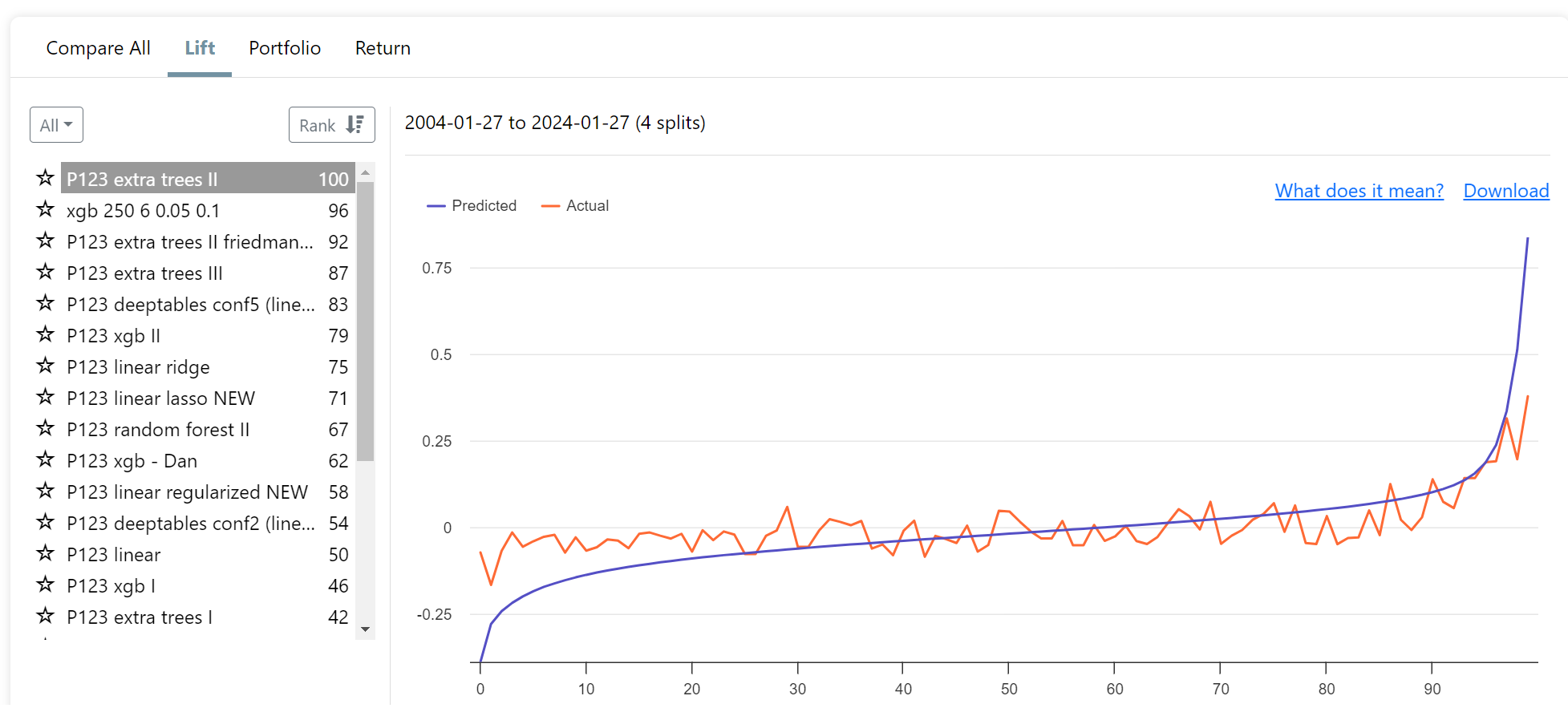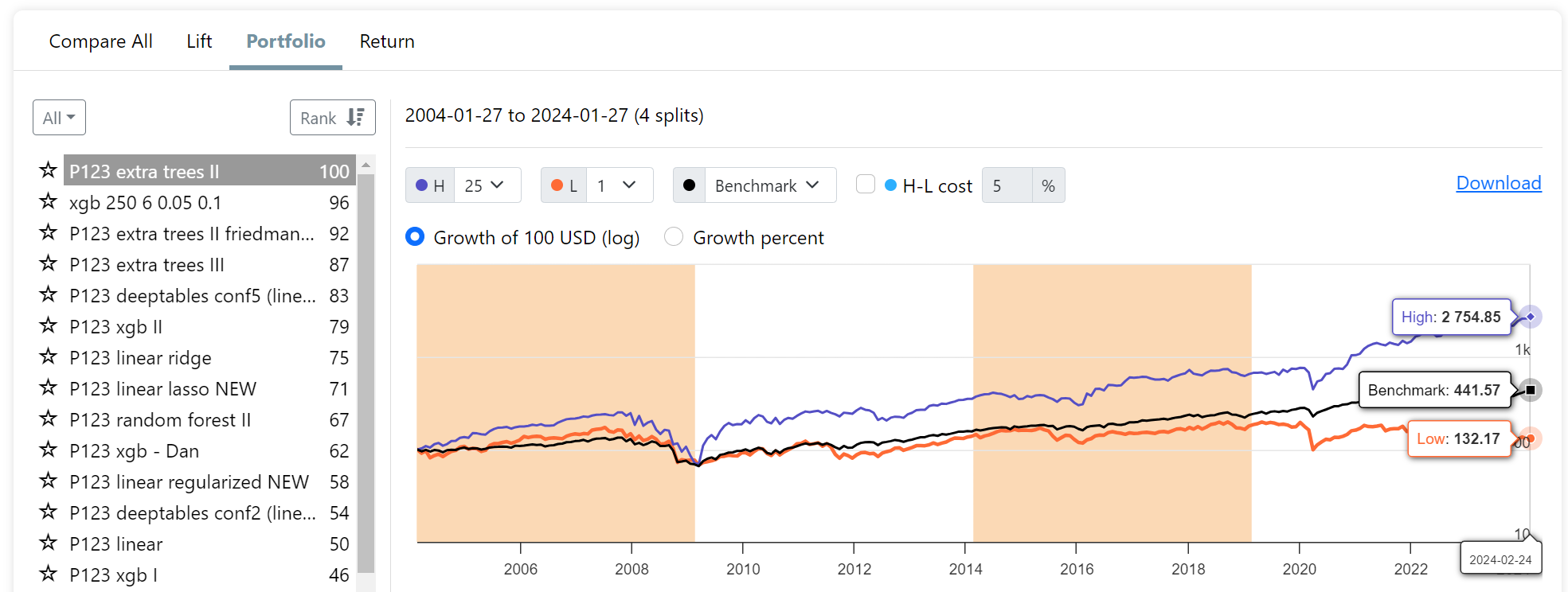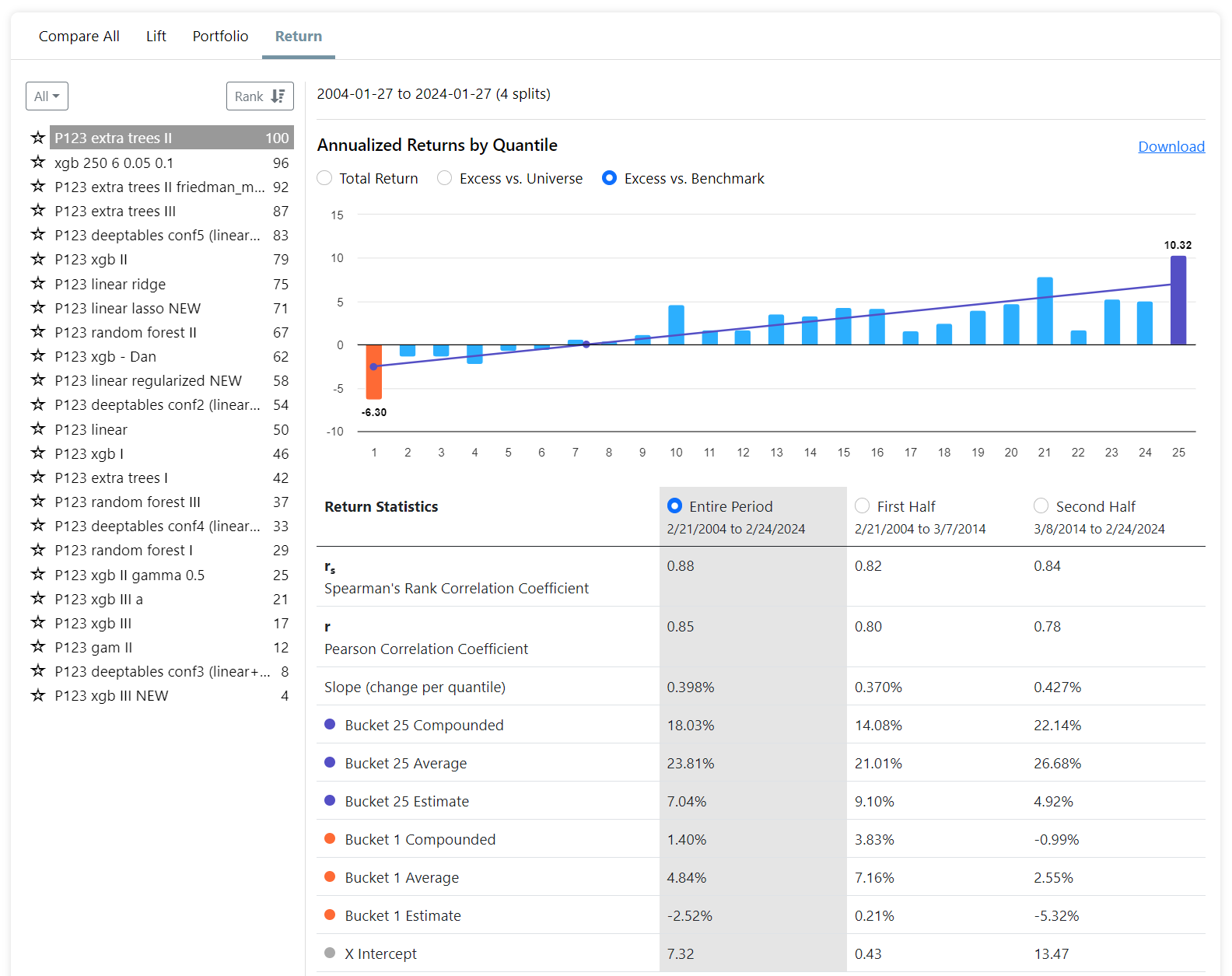
Summary of the conclusion: (https://www.sciencedirect.com/science/article/pii/S0275531924001296)
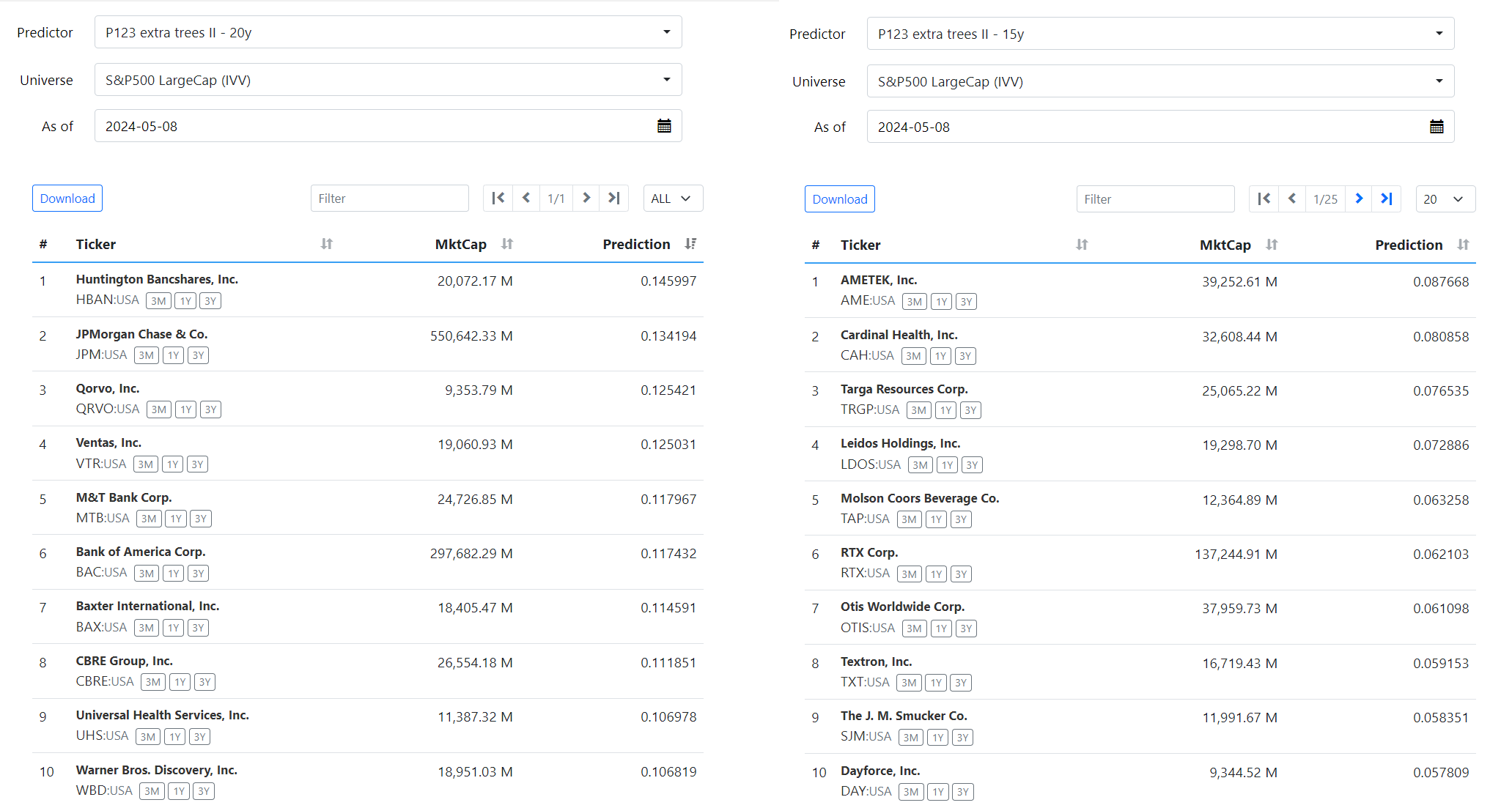
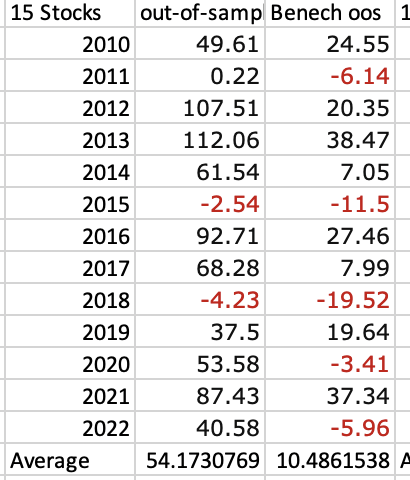
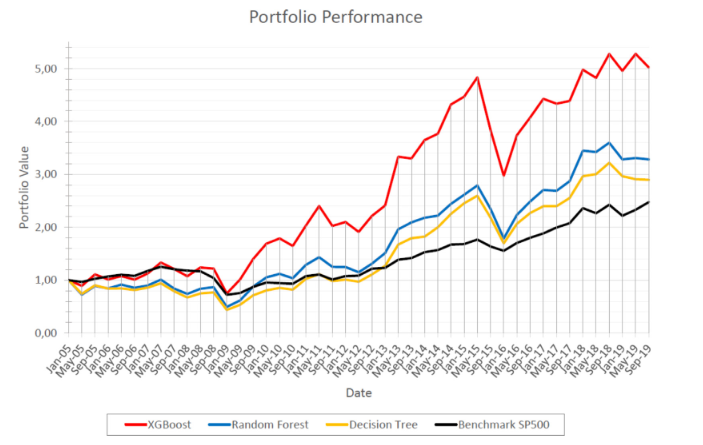
- Outperforming the Market: Machine learning algorithms can outperform the market (like S&P 500) by using financial factors to select a subset of stocks. These algorithms adapt to changing market conditions by adjusting the importance of these factors.
- Good Practices Followed: The study followed recommended practices for applying machine learning to stock returns: reliable data, recent data for predictions, avoiding biases, time-series split training, and hyperparameter tuning.
- Limitations and Improvements:
- Transaction costs were not considered. Frequent rebalancing could erase profits due to buying/selling fees.
- Reliance on data providers: data bias or missing data can impact portfolio formation.
- Ideally, hyperparameter optimization should happen with each rebalancing.
- XGBoost Performs Best: Among the algorithms tested (XGBoost, Random Forest, Decision Trees), XGBoost showed the best performance in terms of classification and financial results.
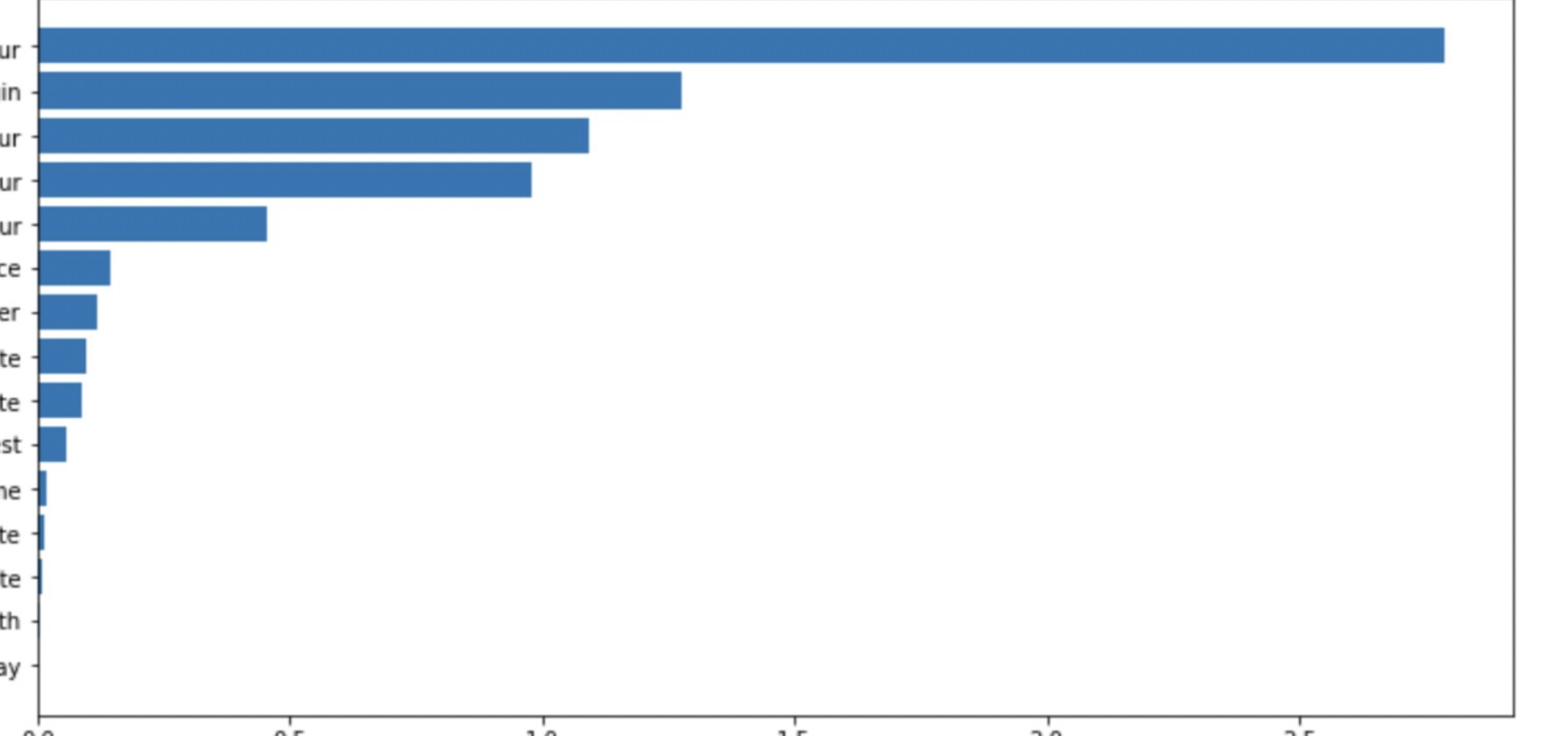
- Adapting to Market Changes: Feature importance analysis revealed that the algorithms adjust to changing market conditions by giving different weights to different factors over time.
- Future Work:
- Analyze factor importance further using tools like SHAP values to understand not just importance but also the relationship between features and stock performance.
- Integrate risk management for better portfolio stability.
- Explore applying this approach in other markets and with optimized weight allocation within the portfolio.
- Combine this model with a model that predicts market crashes for improved performance.
- Leverage ensemble models that combine predictions from different models at different points in time.